本文主要是介绍CVPR1904_人脸聚类 Learning to Cluster Faces on an Affinity Graph,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
摘要
面部识别近年来取得了显着进步,其表现达到了很高的水平。将其提升到一个新的水平需要更大的数据,这将涉及过高的注释成本。因此,利用未标记的数据成为一种有吸引力的选择。最近的研究表明,聚集未标记的面部渗透方法,往往会导致性能提升。然而,如何有效地聚类,特别是在大规模(即百万级或更高级别)数据集上,仍然是一个悬而未决的问题。一个关键的挑战在于集群模式的复杂变化,这种模式可以满足传统的聚类方法以满足所需的精度。这项工作探索了一种新颖的方法,即学习集群而不是依靠手工制作的标准。具体而言,我们提出了一种基于图卷积网络的框架,该框架结合了检测和分割模块来精确定位面部聚类。实验表明,我们的方法可以显着提高面部聚类的准确性,从而也可以提高人脸识别的性能。
1.简介
由于深度学习技术的进步,人脸识别的表现得到了显着提升[25,22,27,3]。然而,应该注意的是,现代面部识别系统的高精度在很大程度上依赖于大规模注释训练数据的可用性。虽然人们可以很容易地从互联网上收集大量的面部图像,但是对它们进行注释却非常昂贵。因此,利用未标记的数据,例如,通过无监督或半监督学习,成为一个引人注目的选择,吸引了学术界和工业界的很多兴趣[30,1]。
将未标记的数据库版本利用为“伪类”的一种自然想法,使得它们可以像被标记的数据一样被使用并且被用于监督学习管道。最近的作品[30]表明,这种方法可以带来性能提升。然而,这种方法的实现仍然有很多不足之处。特别是,他们经常使用无监督的方法,例如K-means [19],谱聚类[11],层次聚类[31]和近似秩序[1]来对未标记的面部进行分组。这些方法仅仅是简单的假设,例如,K-意味着假设它们的例子是单个中心;谱聚类要求聚类大小相对平衡等。因此,它们缺乏具有复杂聚簇结构的能力,从而产生噪声聚类,特别是当应用于从实际世界设置中收集的大规模图像时。这个问题严重限制了性能的提高。
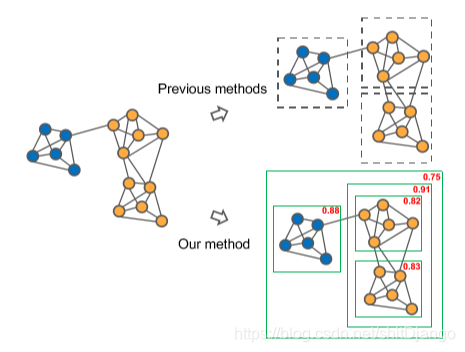
图1:展示现有方法与我们的方法之间差异的案例。蓝色顶点和橙色顶点分别代表了两个类别。以前的无监督方法依赖于特定的政策,可以对具有复杂内部结构的橙色集群进行处理。通过从结构中学习,可以评估群集提议的不同组合(绿色框),并输出具有高分数的群集。
因此,为了有效地利用未标记的人脸数据,我们需要开发有效的集群算法,以应对出现的复杂的集群结构。在实践中。显然,依靠简单的假设不会提供这种能力。在这项工作中,我们探索了一种根本不同的方法,即学习如何从数据中进行聚类。特别是,我们希望借助图形卷积网络的强大表达能力来捕获面部聚类中的常见模式,并利用它们来帮助对未标记数据进行分区。
我们提出了一种基于图卷积网络的人脸聚类框架[15]。该框架采用了Mask R-CNN [10]的管道,例如分段,即生成提议,识别正提议,然后用掩码重新确定它们。这些步骤分别由迭代提议生成器基于超顶点,图形检测网络和图形分割网络完成。虽然我们受Mask R-CNN的启发,但我们的框架仍然有本质区别:前者在2D图像网格上运行,而后者在具有任意结构的亲和图上运行。如图1所示,依赖于基于卷积网络的结构模式,以及一些简单的假设,我们的框架可以处理具有复杂结构的集群。
该方法显着提高了大规模人脸数据的聚类精度,得到了85.66的F-score,这不仅优于无监督聚类方法(F-score 68.39)获得的最佳结果,而且高于近期最先进的[30](F-score 75.01)。使用这个聚类框架来处理未标记的数据,我们将MegaFace上的人脸识别模型的性能从60.29改进到78.64,这完全可以在所有数据上获得对所有数据的监督(80.75)。
主要贡献于三方面:
(1)以监督的方式进行自上而下的面部聚类的第一次尝试阶段。
(2)首先将基于图卷积网络的聚类表示为检测和分割流水线。
(3)我们的方法在大规模人脸聚类中实现了最先进的性能,并且在应用发现的聚类时,将面部识别模型提升到接近监督结果。
2.相关工作
面部聚类
聚类是机器学习的基本任务。 Jain等人。 [12]提供了经典聚类方法的调查。大多数现有的聚类方法都是无监督的。面部聚类提供了一种利用大量未标记数据的方法。这个方向的早期阶段仍然存在。如何在大规模数据上对面进行聚类的问题仍未解决。
早期作品使用手工制作的特征和经典的聚类算法。例如,Ho 等。[11]使用梯度和像素强度作为面部特征。崔等人。 [2]使用了LBP功能。它们都采用谱聚类。近期方法利用学习的功能。 [13]以无人监督的方式进行自上而下聚类。芬利等人。 [5]提出了基于SVM的监督方法。奥托等人。 [1]使用来自基于CNN的人脸模型的深度特征,并提出了将图像对链接为聚类的近似秩次度量度量。 Lin等。[18]基于线性SVM设计了基于数据样本的最近邻居的相似度量。施等人。 [23]提出了条件间度聚类,将聚类公式化为条件随机场,通过成对相似性聚类人脸。林等人。 [17]提出通过引入邻域的最小覆盖范围来改进相似性度量来利用局部深部特征结构。詹等人。 [30]训练了一个MLP分类器来聚合信息,从而发现更强大的联系,然后通过找到连接的组件来获得聚类。
虽然使用了深度特征,但这些工作主要集中在设计新的相似性度量上,并且仍然依赖于无监督的方法来执行聚类。与上述所有工作不同,我们的方法学习如何以自上而下的方式进行聚类,基于检测 - 分割范式。这允许模型处理具有复杂结构的集群。
图卷积网络
图形卷积网络(GCN)[15]扩展CNN以处理图形结构化数据。现有工作已经展示了GCN的优势,例如强大的复杂图形模型建模能力。在各种任务中,使用GCN可以显着提高性能[15,9,26,29]。例如,Kipf等人。 [15]将GCN应用于半监督分类。汉密尔顿等人。 [9]利用GCN来学习特征表示。 Berg等。[26]表明GCNs在链接预测中是优于其他方法的。严等人。 [29]采用GCN模拟人体关节进行基于骨骼的动作识别。
在本文中,我们采用GCN作为在一个亲和图上捕获聚类模式的基本机制。据我们所知,这是第一次使用GCN来学习如何以有监督的方式聚类。
3.方法
在大规模人脸聚类中,聚类模式的复杂变化成为进一步提升绩效的主要挑战。 在挑战中,我们探索了一种监督方法,即基于图卷积网络的容差模式。 具体而言,我们将其表示为一个关联检测和分割问题。
给定面部数据集,我们用训练的CNN提取每个面部图像的特征,形成一组特征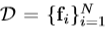 其中fi是d维向量。
其中fi是d维向量。
为了构造亲和图,我们将每个样本视为一个顶点,并使用余弦相似性来找到每个样本的K个最近邻点。 通过在邻居之间连接,我们获得整个数据集的亲和图G =(V,E)。 或者,该功能图也可以由非对称相邻矩阵A∈RN×N表示,其中元素ai,j是连接两个顶点时fi和fj之间的余弦相似度,否则为零。 该图是具有数百万个转换的大尺度图。 从这样的agraph,我们希望得到以下属性:(1)不同的聚类包含不同标签的图像; (2)一个簇中的图像具有相同的标签。
3.1.框架概述
如图2所示,我们的集群框架由三个模块组成,即proposal generator,GCN-D和GCN-S。
(a)第一个模块从亲和图生成cluster proposal,即可能是聚类的子图。
(b)根据所有cluster proposal,我们引入两个GCN模块GCN-D和GCN-S,形成一个两阶段程序,首先选择高质量的proposals,然后通过消除其中的噪声来重新确定selected proposals 。
(c)具体而言,GCN-D执行cluster detection。 以cluster proposal作为输入,它评估proposal构成所需群集的可能性。 然后,GCN-S执行分段重新定义selected proposals。
(d)特别是,给定一个聚类,它估计每个顶点的噪声概率,并通过丢弃异常值来修剪聚类。 根据这两个GCN的输出,我们可以有效地获得高质量的集群。
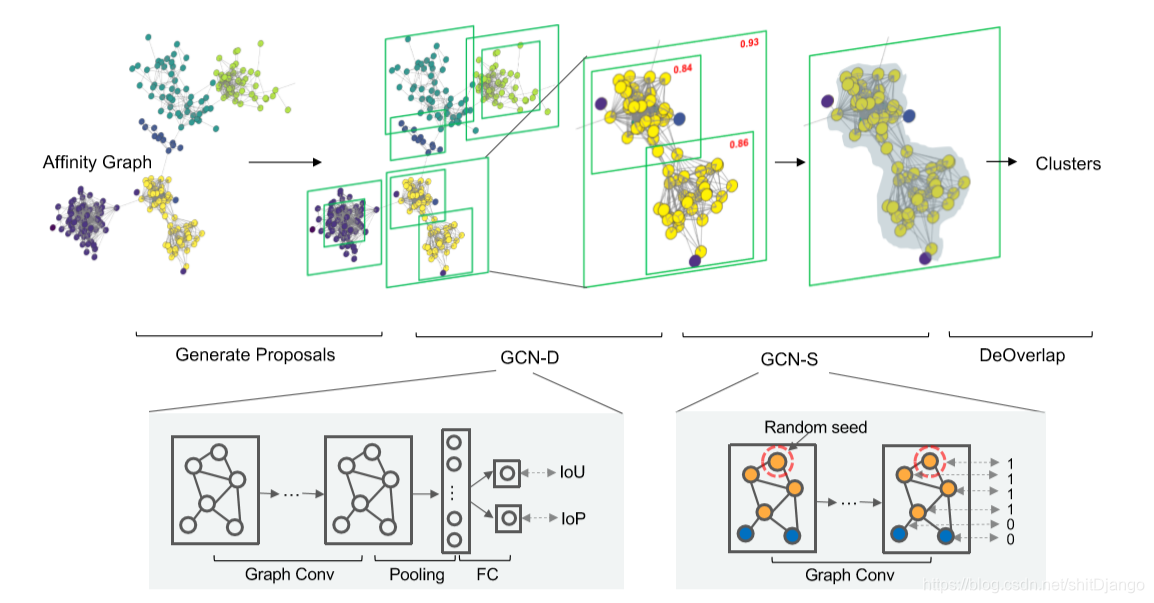
图2:用于群集的图检测和分段概述。
3.2.Cluster Proposals
未完
这篇关于CVPR1904_人脸聚类 Learning to Cluster Faces on an Affinity Graph的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







