cluster专题

Hive中order by,sort by,distribute by,cluster by的区别
一:order by order by会对输入做全局排序,因此只有一个Reducer(多个Reducer无法保证全局有序),然而只有一个Reducer,会导致当输入规模较大时,消耗较长的计算时间。关于order by的详细介绍请参考这篇文章:Hive Order by操作。 二:sort by sort by不是全局排序,其在数据进入reducer前完成排序,因此,如果用sort

K8s高可用集群部署----超详细(Detailed Deployment of k8s High Availability Cluster)
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:Linux运维老纪的首页,持续学习,不断总结,共同进步,活到老学到老 导航剑指大厂系列:全面总结 运维核心技术:系统基础、数据库、网路技术、系统安全、自动化运维、容器技术、监控工具、脚本编程、云服务等。 常用运维工具系列:

redis-cluster实现分布式集群以及JedisCluster连接集群
redis-cluster redis-cluster结构:两两相连 redis-cluster结构 哨兵集群redis技术中只能主要负责解决高可用的问题,但是实现分布式比较浪费资源,分布式计算比较复杂,需要根据搭建的结构实现不同的分布式hash一致性的重写过程。 redis3.0版本redis出现了最终的结构支持高可用分布式同时存在的redis-cluster 特性 基础:两两互联

使用VMware VSphere WebService SDK进行开发 (四)——获取集群(Cluster, ComputeResource)的相关信息
欢迎支持笔者新作:《深入理解Kafka:核心设计与实践原理》和《RabbitMQ实战指南》,同时欢迎关注笔者的微信公众号:朱小厮的博客。 欢迎跳转到本文的原文链接:https://honeypps.com/backend/vmware-vsphere-webservice-sdk-cluster/ 获取集群的信息不再过多的赘述,详细读过前面两篇文章的读者已经很快上路子了~ 疯狂罗列
Redis三种集群模式:主从模式、哨兵模式和Cluster模式
1. 总结经验 redis主从:可实现高并发(读),典型部署方案:一主二从 redis哨兵:可实现高可用,典型部署方案:一主二从三哨兵 redis集群:可同时支持高可用(读与写)、高并发,典型部署方案:三主三从 2. 概述 Redis 支持三种集群模式,分别为主从模式、哨兵模式和Cluster模式。 最初,Redis采用主从模式构建集群。在这种模式下,如果主节点(master)出现故障

WAVE-CLUSTER算法原理及Python实践
一、WAVE-CLUSTER算法原理 WAVE-CLUSTER算法,也称为WaveCluster小波聚类算法,是一种基于小波变换的聚类分析方法。其原理主要涉及到将数据看作多维信号进行处理,并通过小波变换将数据从原始空间变换到频域空间,以揭示数据的自然聚类属性。以下是WAVE-CLUSTER算法的主要原理步骤: 1、数据空间量化: 首先,将多维数据空间进行量化,即将每个数据点映射到一个量化
【Redis】Cluster-集群
简介 在生产环境中,我们希望Redis可以支持以下特性: 高可用:时刻保证Redis服务可用,降低单节点宕机带来的损失可拓展:随着数据的增多,可以通过简单的增加节点来实现横向扩展 Redis的主从复制与Sentinel相结合可以实现高可用,解决了扩展读的问题,但仍然是一个单实例Redis,没有解决扩展写问题,Redis Cluster便是官方给出的解决方案。 原理 Redi

Redis系列六---通过Helm部署Redis-Cluster
目录 前 言 搜索redis-cluster chart 下载redis-cluster chart 修改values.yaml文件 部署安装redis-cluster 检查部署结果 测试数据写入 故障测试 前 言 前面文章《Helm来了还在为写复杂的Yaml文件而烦恼吗》讲述了helm工具的使用,结合最近整理的《Redis系列五---轻松搞懂Redis的集群与高可

node.js cluster多进程、负载均衡和平滑重启
1 cluster多进程 cluster经过好几代的发展,现在已经比较好使了。利用cluster,可以自动完成子进程worker分配request的事情,就不再需要自己写代码在master进程中robin式给每个worker分配任务了。 const cluster = require('cluster');const http = require('http');const n

Elasticsearch的核心概念cluster/shards/replicas/recovery/gateway/discovery.zen/transport/settings/mapping等
cluster 代表一个集群,集群中有多个节点,其中有一个为主节点,这个主节点是可以通过选举产生的,主从节点是对于集群内部来说的。es的一个概念就是去中心化,字面上理解就是无中心节点,这是对于集群外部来说的,因为从外部来看es集群,在逻辑上是个整体,你与任何一个节点的通信和与整个es集群通信是等价的。 主节点的职责是负责管理集群状态,包括管理分片的状态和副本的状态,以及节点的发现和删除。 只需要在

CentOS7 mysql-cluster安装与配置
目录 下载安装: #拷贝ndb_mgm和ndb_mgmd #创建并编辑配置文件 #初始化管理节点 安装数据节点和sql节点 #初始化mysql #启动mysql #登录并设置新密码 #启动ndbd节点: #启动和停止管理节点 mysql-cluster安装与配置 下载安装

redis3.x cluster设计
redis3.x cluster》 前言 redis集群后,我们就需要一种数据路由算法将不同key分散存储到不同的redis节点内,通常的做法是获取某个key的hashcode,然后mod,不过这种做法无法很好的支持动态伸缩性需求,一旦节点的增或者删操作,都会导致key无法在redis中命中,所以在redis3.x之前,基本上都是采用编写一致性hash算法实现redis的集群,但是
数据库集群-Mysql-mysql-cluster 安装
环境说明 系统环境:CentOS 6.5 mini(64bit) 软件版本:mysql-cluster-advanced-7.3.7-linux-glibc2.5-x86_64.tar.gz IP地址: MGM:192.168.100.211 NDBD1:192.168.100.212 NDBD2:192.168.100.213 SQL1:192.168.100.214

MySQL Cluster 7.3.7+CentOS7集群配置入门 MySQL双管理节点配置入门
1 环境说明:CentOS7(64位) + MySQL Cluster 7 3 7,3台机器(2+2+3),节点分布情况:MGM1:192 168 16 130 MGM2: 192 168 16 131NDBD1 1.环境说明:CentOS7(64位) + MySQL Cluster 7.3.7,3台机器(2+2+3),节点分布情况: MGM1:192.168.16.
mysql cluster (mysql 集群)安装配置方案
一、准备 1、准备服务器 计划建立有5个节点的MySQL CLuster体系,需要用到5台服务器,但是我们做实验时没有这么多机器,可以只用2台,我就是一台本机,一台虚拟机搭建了有5个节点的MySQL CLuster体系,将一个SQL节点一个数据节点一个SQL节点放在了一台服务器上(192.168.1.252),将另一个SQL节点和一个数据节点放在了另外一台服务器上(192.168.1.5
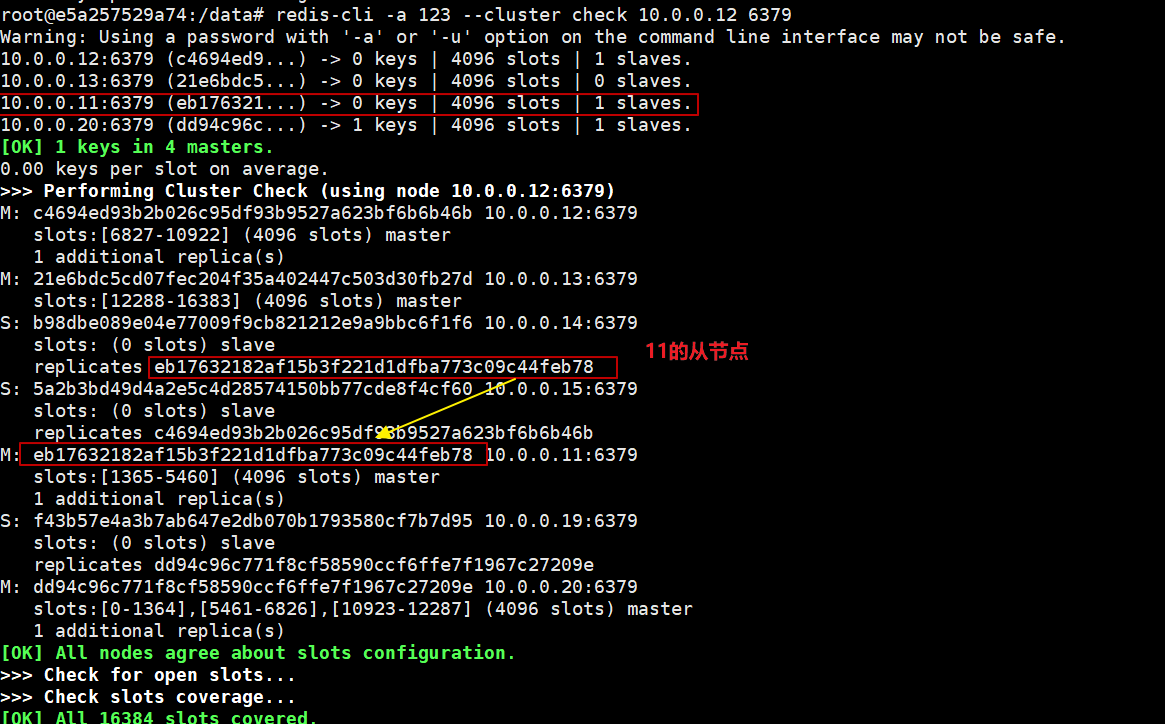
redis-cluster 集群搭建和迁移(二)
上一篇写了redis-cluster集群的搭建过程,这里讲一下redis的迁移过程,因为以前的生产环境是单实例的,所有迁移起来比较麻烦,参考了一下网上的资料,可以使用修改卡槽的办法来实现迁移。 具体的思路是这样,redis 包含16348 个卡槽,是hash分布的,所有的数据都分布在上面,先把redis-cluster所有的卡槽全部集中到一个节点9000上,然后在单节点上通过rds 持久化数据,
redis-cluster 集群搭建和迁移(一)
最近给公司搭建了一个redis-cluster集群,把原来的单实例的数据迁移到了集群上,踩了一些坑,记录一些 使用的redis 版本是5.0.5 操作系统 centos7 安装redis-cluster集群需要ruby环境, centos7 yum 源中的ruby 版本太低,不能安装redis,所以必须离线安装。我选择的版本是2.5.3 一.安装ruby wget https:/
Centos 6.5 redis cluster集群搭建
Centos 6.5 redis cluster集群搭建 参考文章:Redis 学习笔记(十四)Redis Cluster介绍与搭建 前言 对于redis集群的创建,总体来说可以分为两种方式: 1. 使用redis replication功能对redis进行复制,同时对于主从进行读写分离。使用redis sentinel保证redis集群的高可用性。 这种方式有以下优点: 可支持横向

docker redis4.0 集群(cluster)搭建
docker redis4.0 集群(cluster)搭建 本文转自:docker redis4.0 集群(cluster)搭建 前言 redis集群对于很多人来说非常熟悉,在前些日子,我也有一位大兄弟也发布过一篇关于在阿里云(centOS7)上搭建redis 集群的文章,虽然集群搭建的文章在网上很多,我比较喜欢这篇文章的地方是他在搭建过程中,指出一些我们会遇到而别人没有指出的问题。

Python3交互redis cluster
安装 pip install redis-py-cluster 示例代码 # pip install redis-py-clusterfrom rediscluster import *"""redis 集群信息:Using 3 masters:192.168.196.131:7000192.168.196.129:7003192.168.196.131:7001Adding
spark client mode cluster mode 区别 与选择
1、在我们使用spark-submit 提交spark 任务一般有以下参数 /bin/spark-submit \--class <main-class> \--master <master-url> \--deploy-mode <deploy-mode> \--conf <key>=<value> \... # other options<application-jar> \[applica

CloudStack基本概念-Zone,Pod,Cluster,Host
ZonePodClusterHost Zone Zone(资源域)是CloudStack部署中第二大的组织单元。Zone一般对应一个数据中心,虽然一个数据中心也可以有多个Zone。 把基础设施组织进Zone的一个好处就是可以提供物理隔离和冗余。 例如每个Zone可以有自己的电源供应和网络线路,并且zone之间可以远远地隔离开(虽然不是必须的) 一个zone包括:
Spark on YARN cluster作业运行全过程分析
下面是分析Spark on YARN的Cluster模式,从用户提交作业到作业运行结束整个运行期间的过程分析。 客户端进行操作 1、根据yarnConf来初始化yarnClient,并启动yarnClient 2、创建客户端Application,并获取Application的ID,进一步判断集群中的资源是否满足executor和ApplicationMaster申请的资源,如果不满足
Redis cluster配置文件和集群状态详解
redis cluster命令 集群(cluster) cluster info 打印集群的信息cluster nodes 列出集群当前已知的所有节点(node),以及这些节点的相关信息 节点(node) cluster meet <ip> <port> 将ip和port所指定的节点添加到集群当中,让它成为集群的一份子 cluster forget <nod
redis实战第十五篇 redis cluster的批处理中ask重定向解决方案
ask重定向现象请参考【传送门】 分别使用mget和pipline做批处理 1.使用mget批量获取,如果存在重定向问题,会抛出异常。 @Testpublic void testMget(){JedisCluster jedis = RedisClusterUtil.getJedis();List<String> results = null;results = jedis.mget(
redis实战第十四篇 redis cluster ask重定向
redis cluster除了有一个moved重定向,还存在ask重定向。ask重定向代表的状态比较特别,它是当slot处于迁移状态时才会发生。例如:一个slot存在三个key,分别为hello1、hello2、hello3,假设此时slot正在处于迁移状态,hello1已经迁移到了目标节点,此时如果在源节点获取hello1,则会报出ask重定向错误。 下面通过手动迁移slot来模拟ask重定向