本文主要是介绍yolov7 训练crowded human 【head, full body, visible body box detection】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- 0 前言
- 0 训练数据公开
- 1 相关资料
- 2 crowded human数据集下载
- 2.1 官网数据集下载
- 3 YOLOv5-Tools
- 3.1 YOLOv5-Tools 安装
- 3.2 YOLOv5-Tools中关键文件
- 3.3 CrowdHuman数据转化为coco数据集格式
- 3.4 转化后的结果展示
- 3.5 图像文件和标注文本文件 重构
- 3.6 CrowdHuman YOLO格式数据下载
- 4 yolov7 训练与测试
- 4.1 下载预训练权重
- 4.2 配置文件
- 4.3 训练
- 4.5 训练结果
- 4.6 测试
- 4.7 结果对比
- 4.7 分析训练结果
0 前言
知乎:
b站:https://www.bilibili.com/video/BV1f94y1n7NG/
上一篇博客:yolov5 训练crowded human 【visible body detection】
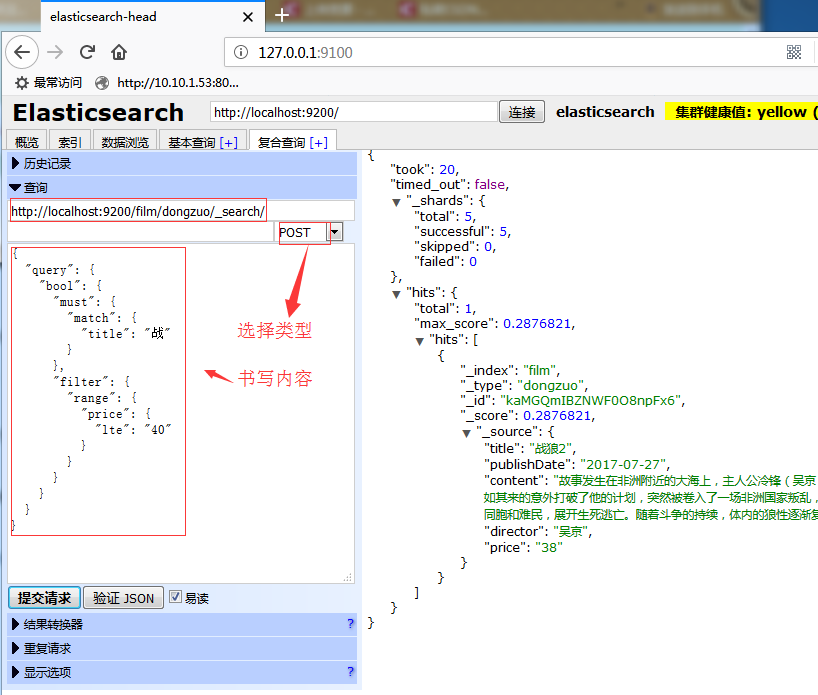
在对拥挤人群(我应用场景是学生课堂)进行检测时,采用现有的模型代码,有一定问题,比如直接采用yolov8、yolov7、yolov5、yolov3、faster rcnn等,在拥挤场景的检测效果不佳,但使用crowded human数据集重训练后的yolov7,效果很好。crowded human数据集标签如下,有Head BBox、Visible BBox、Full BBox。如下图显示:

0 训练数据公开
YOLOv7x训练权重及训练相关文件
YOLOv7x权重:
链接:https://pan.baidu.com/s/1DJ0GEpxlaUtnNDCmxNr3UA?pwd=4lf2
提取码:4lf2
YOLOv7x 训练相关文件:
链接:https://pan.baidu.com/s/1BWYLHt2uf8zjN6d3UNOLaQ?pwd=s77o
提取码:s77o
google drive:https://drive.google.com/drive/folders/1FYd8xiQvmTfKcpgl_2fedawuor61snjo?usp=sharing
crowdhuman_vbody_yolov5m:
https://drive.google.com/file/d/1VJtrdE85Wc4xSZXqAPUkWABLResUYG8V/view?usp=sharing
crowdhuman_vbody_yolov5m:
链接:https://pan.baidu.com/s/1w-5BH2CMfJ9t5qFKyd89Ag?pwd=td3j
提取码:td3j
1 相关资料
CrowdHuman的论文
CrowdHuman: A Benchmark for Detecting Human in a Crowd:https://arxiv.org/pdf/1805.00123.pdf
yolov5-crowdhuman的代码,这里是训练后的head detection和 full body detection 的模型,并没有 visible body detection。
yolov5-crowdhuman:https://github.com/deepakcrk/yolov5-crowdhuman
这是githun中对CrowdHuman论文的翻译
PaperWeekly/CrowdHuman.md:https://github.com/Mycenae/PaperWeekly/blob/master/CrowdHuman.md
这一个博客就非常重要了,是我能完成这篇博客的核心
目标检测 YOLOv5 CrowdHuman数据集格式转YOLOv5格式:https://blog.csdn.net/flyfish1986/article/details/115485814
YOLOv5-Tools-main源码
我也将这个同步到了自己的github中:https://github.com/Whiffe/YOLOv5-Tools-main
也同步到了码云:[https://gitee.com/YFwinston/YOLOv5-Tools-main](https://gitee.com/YFwinston/YOLOv5-Tools-main
2 crowded human数据集下载
2.1 官网数据集下载
CrowdHuman dataset下载链接:https://www.crowdhuman.org/download.html

下载后有这些文件:
3 YOLOv5-Tools
3.1 YOLOv5-Tools 安装
YOLOv5-Tools的功能之一就是讲crowded human转化为yolo可以使用的数据集格式,即coco数据集格式。
YOLOv5-Tools代码链接:https://gitcode.net/mirrors/shaoshengsong/YOLOv5-Tools
我也将这个同步到了自己的github中:https://github.com/Whiffe/YOLOv5-Tools-main
也同步到了码云:https://gitee.com/YFwinston/YOLOv5-Tools-main
选择社区景象(https://www.autodl.com/home)

cd /root/autodl-tmp
git clone https://gitee.com/YFwinston/YOLOv5-Tools-main
3.2 YOLOv5-Tools中关键文件
YOLOv5-Tools中有1个关键文件:
/root/autodl-tmpYOLOv5-Tools-main/CrowHuman2YOLO/data/gen_txts_hfv.py

3.3 CrowdHuman数据转化为coco数据集格式
crowdhuman 数据集位于:/root/autodl-pub/CrowdHuman
crowded human数据转化为yolo数据集格式,执行下面的代码
cd /root/autodl-tmp/YOLOv5-Tools-main/CrowHuman2YOLO/data/mv /root/autodl-tmp/CrowdHuman/* /root/autodl-tmp/YOLOv5-Tools-main/CrowHuman2YOLO/data/rawbash prepare_data_hfv.sh 608x608


3.4 转化后的结果展示
然后目录/root/autodl-tmp/YOLOv5-Tools-main/CrowHuman2YOLO/data/raw/Images的结构如下
Images
├── 273271,1017c000ac1360b7.jpg
├── 273271,10355000e3a458a6.jpg
├── 273271,1039400091556057.jpg
├── 273271,104ec00067d5b782.jpg
├── ...
└── 284193,ff25000b6a403e9.jpg
使用文件计数命令可以数出Images文件夹下文件数量
cd /root/autodl-tmp/YOLOv5-Tools-main/CrowHuman2YOLO/data/raw/Images
ls -l|grep "^-"| wc -l

结果是:19370
还有个路径也有生成结果:/home/YOLOv5-Tools-main/CrowHuman2YOLO/data/crowdhuman-608x608
结构如下
crowdhuman-608x608
├── 273271,1017c000ac1360b7.jpg
├── 273271,1017c000ac1360b7.txt
├── 273271,10355000e3a458a6.jpg
├── 273271,10355000e3a458a6.txt
├── ...
├── 284193,ff25000b6a403e9.jpg
├── 284193,ff25000b6a403e9.txt
├── test.txt
└── train.txt
我们看看273271,1017c000ac1360b7.txt的内容
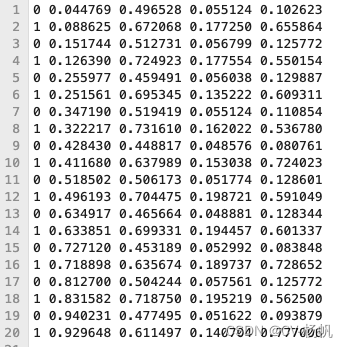
再看看test.txt的内容

再看看train.txt的内容

讲crowded human生成coco标准文件夹格式
3.5 图像文件和标注文本文件 重构
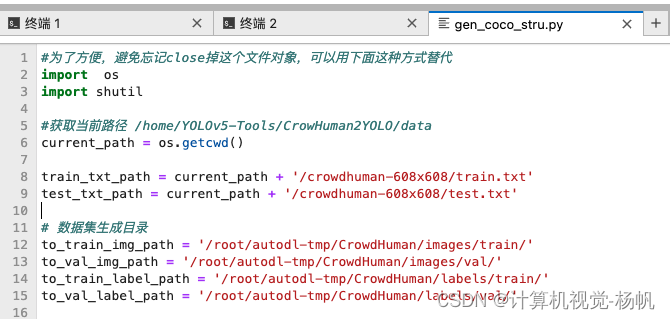
3.3节只是将crowded human数据集转化为了coco结构的数据集,但是图像文件和标注文本文件需要重构,
首先按照下面路径创建文件夹:
# 数据集生成目录
to_train_img_path = '/root/autodl-tmp/CrowdHuman/images/train/'
to_val_img_path = '/root/autodl-tmp/CrowdHuman/images/val/'
to_train_label_path = '/root/autodl-tmp/CrowdHuman/labels/train/'
to_val_label_path = '/root/autodl-tmp/CrowdHuman/labels/val/'
并修改:/root/autodl-tmp/YOLOv5-Tools-main/CrowHuman2YOLO/data/gen_coco_stru.py
然后重构命令:
cd /root/autodl-tmp/YOLOv5-Tools-main/CrowHuman2YOLO/data/
python gen_coco_stru.py
结果如下:
/root/autodl-tmp/CrowdHuman/images/
crowdedHuman
├── Images
│ ├── train
│ │ ├── 273271,1017c000ac1360b7.jpg
│ │ ├── 273271,10355000e3a458a6.jpg
│ │ ├── 273271,1039400091556057.jpg
│ │ ├── ...
│ │ └── 284193,ff01000db10348e.jpg
│ ├── val
│ │ ├── 273271,104ec00067d5b782.jpg
│ │ ├── 273271,10f400006b6fb935.jpg
│ │ ├── 273271,118910008d823f61.jpg
│ │ ├── ...
│ │ └── 284193,ff25000b6a403e9.jpg
└── labels ├── train│ ├── 273271,1017c000ac1360b7.txt│ ├── 273271,10355000e3a458a6.txt│ ├── 273271,1039400091556057.txt│ ├── ...│ └── 284193,ff01000db10348e.txt└── val├── 273271,104ec00067d5b782.txt├── 273271,10f400006b6fb935.txt├── 273271,118910008d823f61.txt├── ...└── 284193,ff25000b6a403e9.txt
cd /root/autodl-tmp/CrowdHuman/images/train
ls -l|grep "^-"| wc -l
cd /root/autodl-tmp/CrowdHuman/images/val
ls -l|grep "^-"| wc -l
cd /root/autodl-tmp/CrowdHuman/labels/train
ls -l|grep "^-"| wc -l
cd /root/autodl-tmp/CrowdHuman/labels/val
ls -l|grep "^-"| wc -l
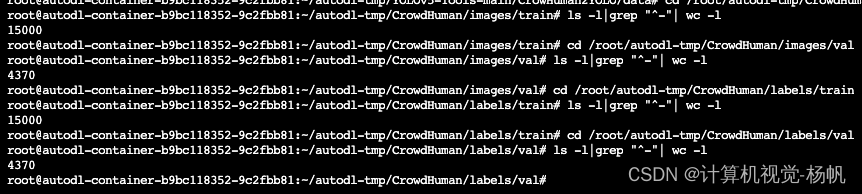
images/train: 15000
images/val: 4370
labels/train: 15000
labels/val: 4370
3.6 CrowdHuman YOLO格式数据下载
CrowdHuman YOLO格式数据我已经上传百度网盘,·:
链接:https://pan.baidu.com/s/1Gw0QgRS7O0QHR9PmyABxdw?pwd=vre3
提取码:vre3
4 yolov7 训练与测试
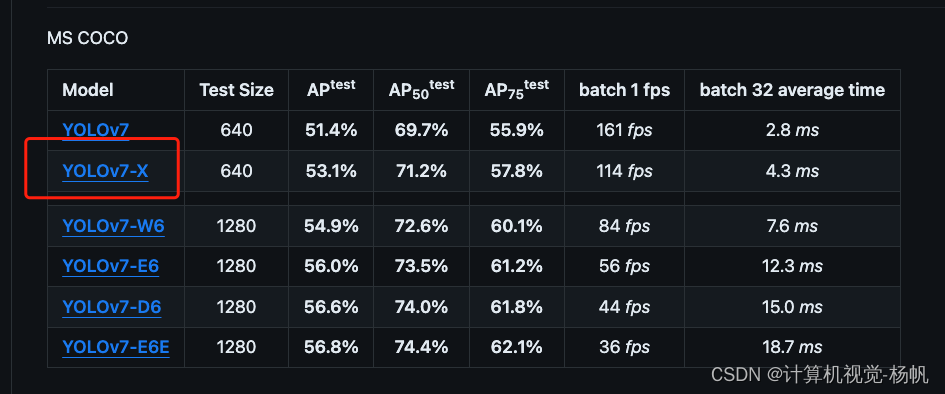
4.1 下载预训练权重
下载yolov7x的模型,https://github.com/WongKinYiu/yolov7
然后上传到平台中
训练需要在 /data/SCB/yolov7-main/data/ 下创建:crowdhuman.yaml,其内容如下:
4.2 配置文件
执行下面的代码
cd /data/SCB/yolov7-main/data/
vim crowdhuman.yamltrain: /data/CrowdHuman/images/train
val: /data/CrowdHuman/images/val
#test: test.txt#number of classes
nc: 3# class names
names: ['head', 'full body', 'visible body']进入:/data/SCB/yolov7-main/training/yolov7x.yaml
然后修改:
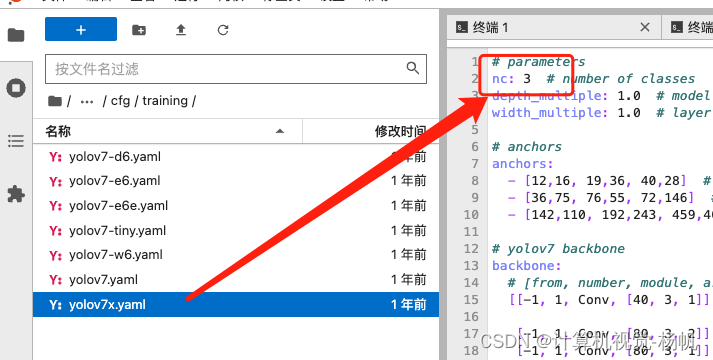
4.3 训练
执行下面的训练代码:
cd /data/SCB/yolov7-main/
python train.py --data ./data/crowdhuman.yaml --cfg ./cfg/training/yolov7x.yaml --weights yolov7x.pt --batch-size 8 --epochs 200 --project runs/train/CrowdHumanYOLOv7x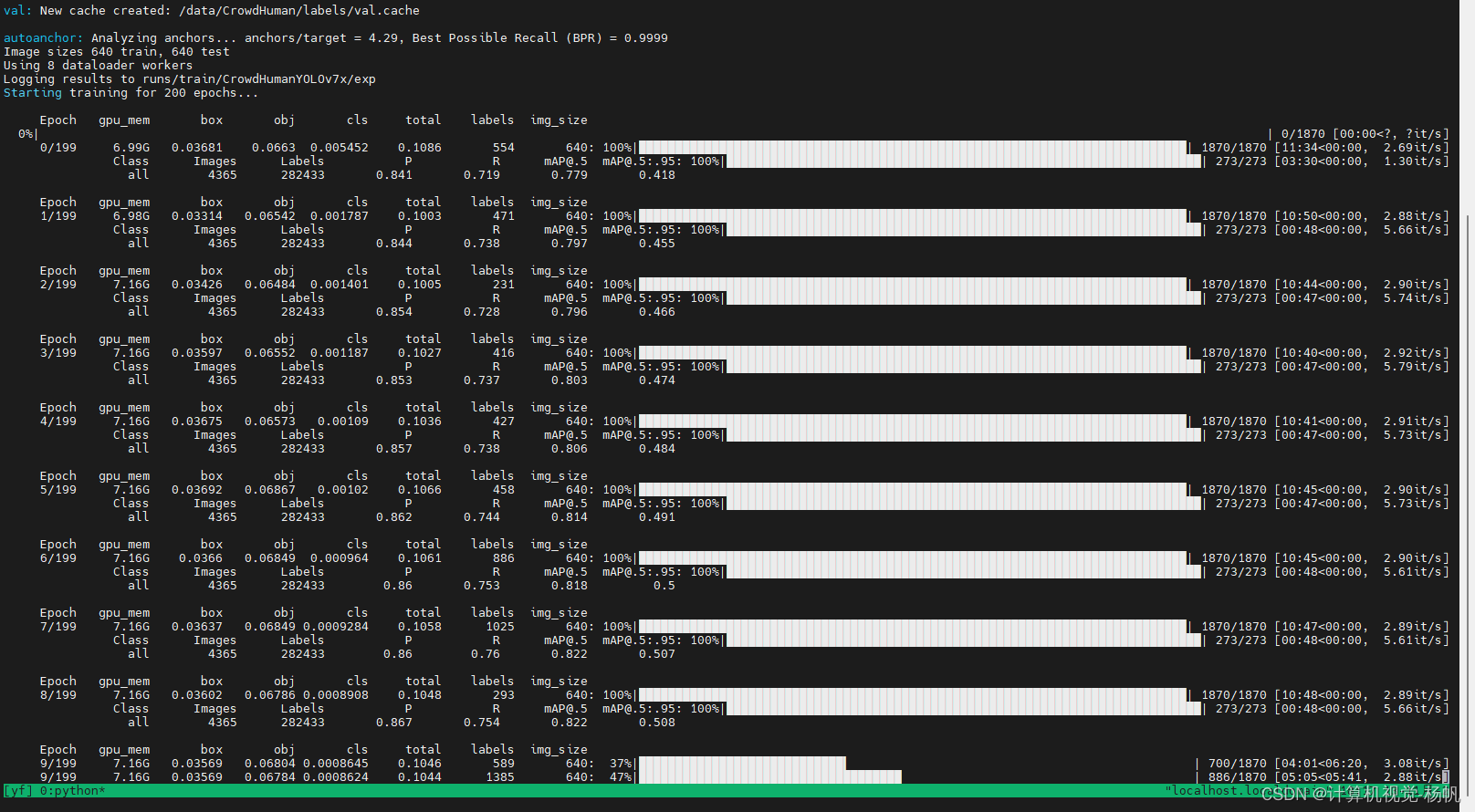
4.5 训练结果
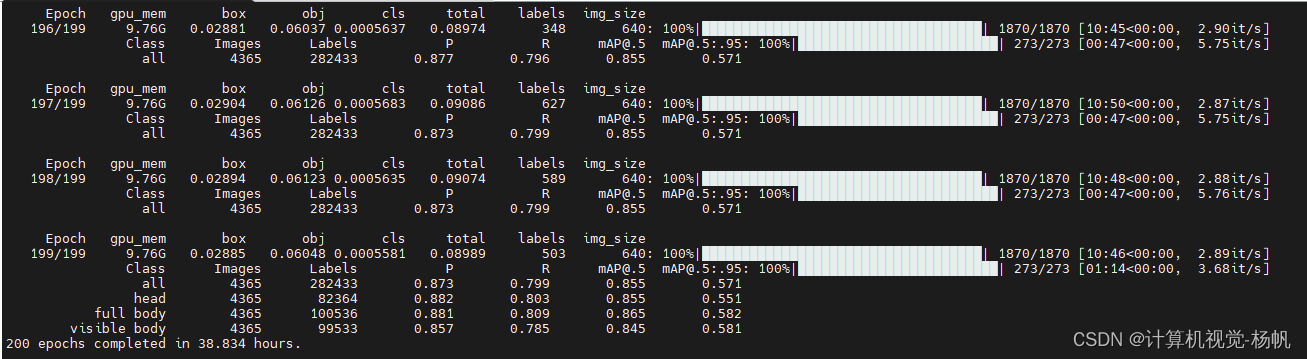
Class Images Labels P R mAP@.5 mAP@.5:.95: all 4365 282433 0.873 0.799 0.855 0.571head 4365 82364 0.882 0.803 0.855 0.551full body 4365 100536 0.881 0.809 0.865 0.582visible body 4365 99533 0.857 0.785 0.845 0.581
200 epochs completed in 38.834 hours.4.6 测试
python test.py --data data/crowdhuman.yaml --weights runs/train/CrowdHumanYOLOv7x/exp/weights/last.pt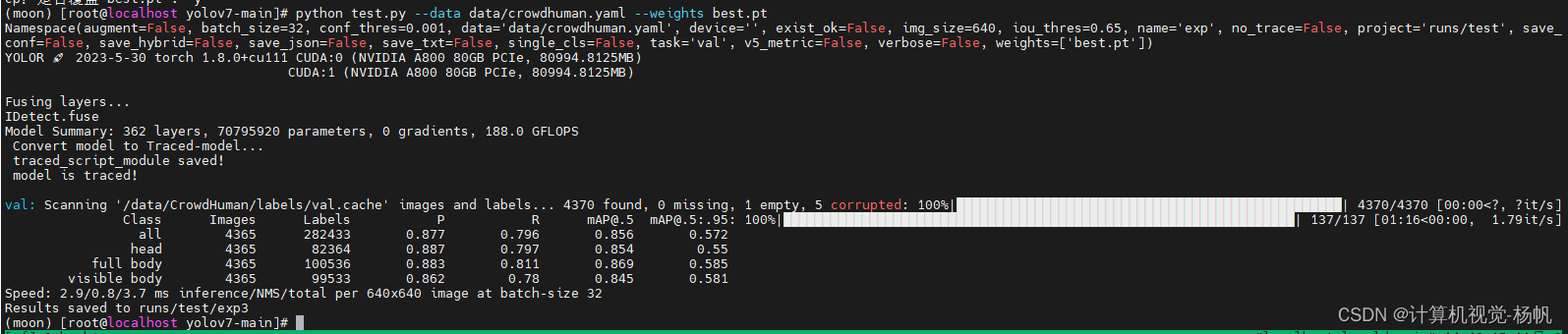
val: Scanning '/data/CrowdHuman/labels/val.cache' images and labels... 4370 found, 0 missing, 1 empty, 5 corrupted: 100%|█████████████████████████████████████████████████| 4370/4370 [00:00<?, ?it/s]Class Images Labels P R mAP@.5 mAP@.5:.95: all 4365 282433 0.877 0.796 0.856 0.572head 4365 82364 0.887 0.797 0.854 0.55full body 4365 100536 0.883 0.811 0.869 0.585visible body 4365 99533 0.862 0.78 0.845 0.581
Speed: 2.9/0.8/3.7 ms inference/NMS/total per 640x640 image at batch-size 32
Results saved to runs/test/exp34.7 结果对比

原图

yolov7x

yolov7x_crowdhuman

原图

yolov7x

yolov7x_crowdhuman
4.7 分析训练结果
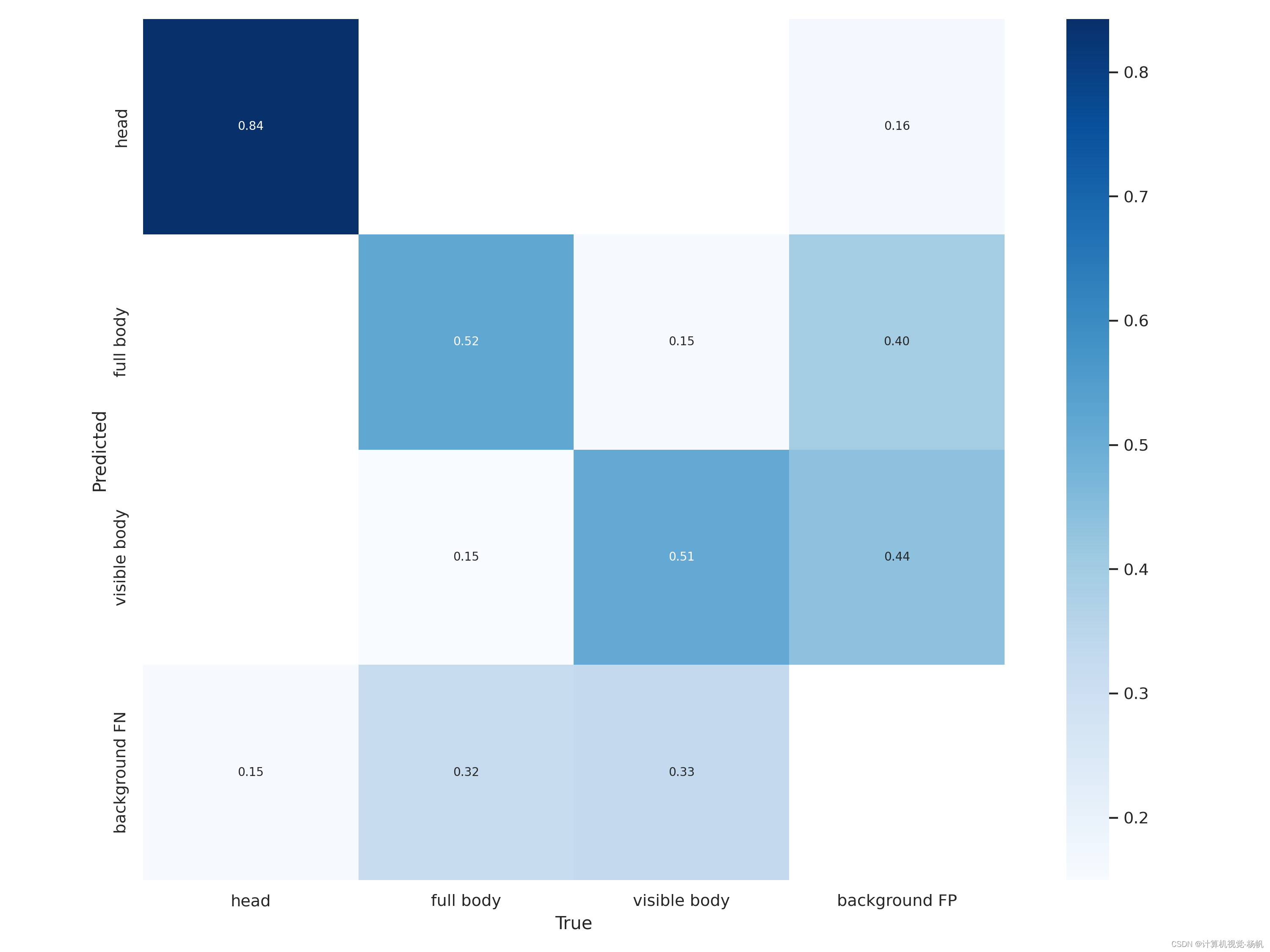
confusion_matrix.png
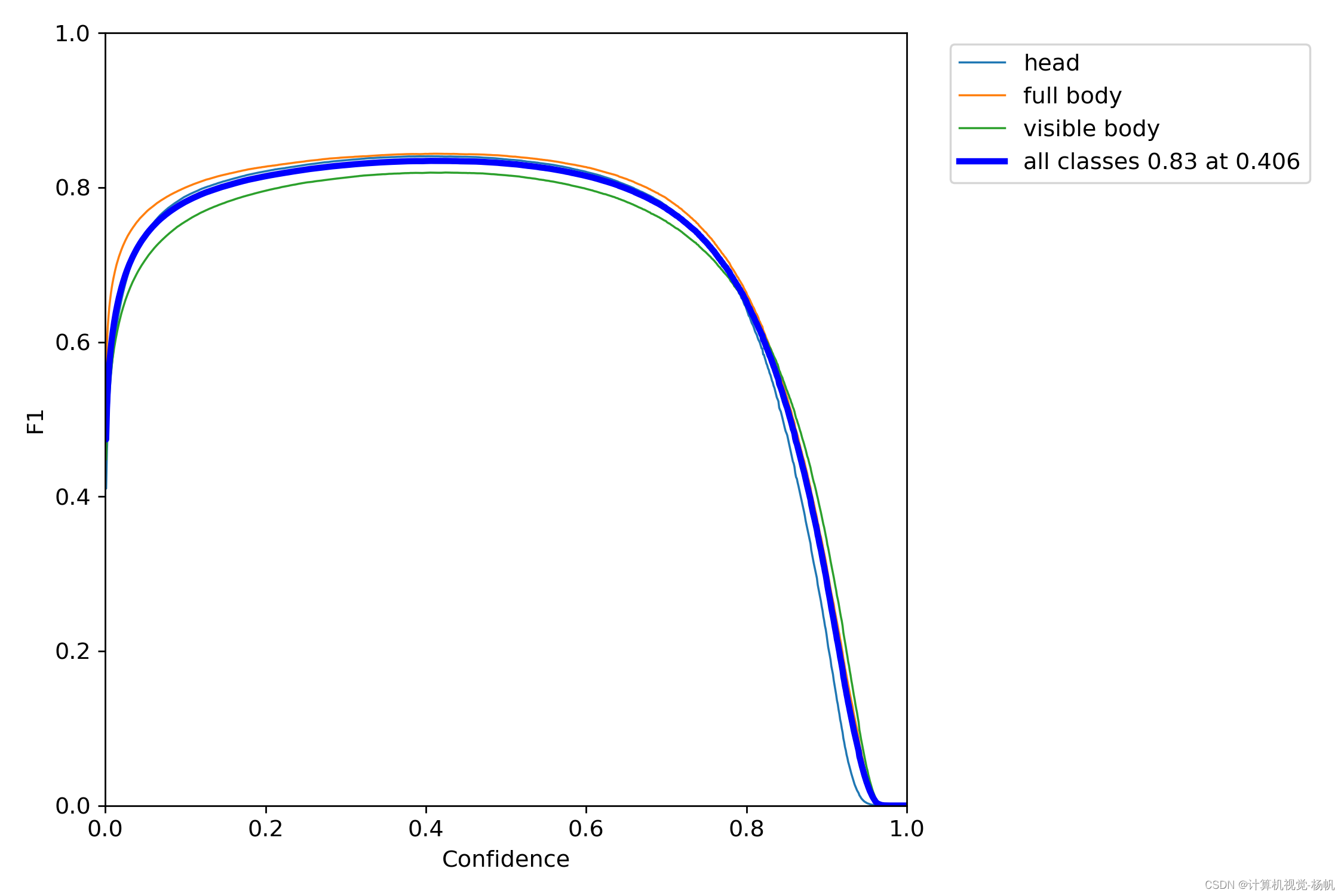
F1_curve.png
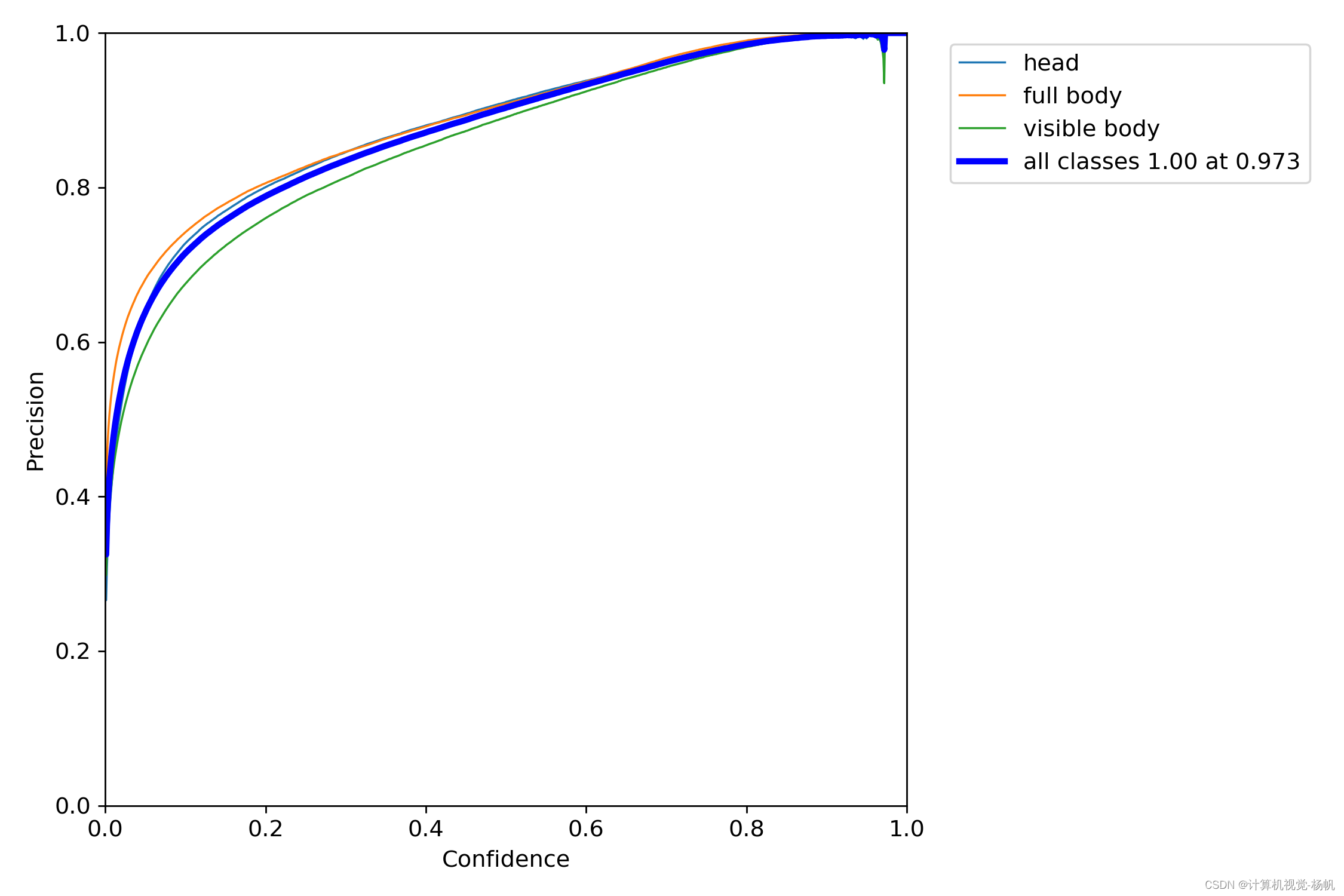
P_curve.png
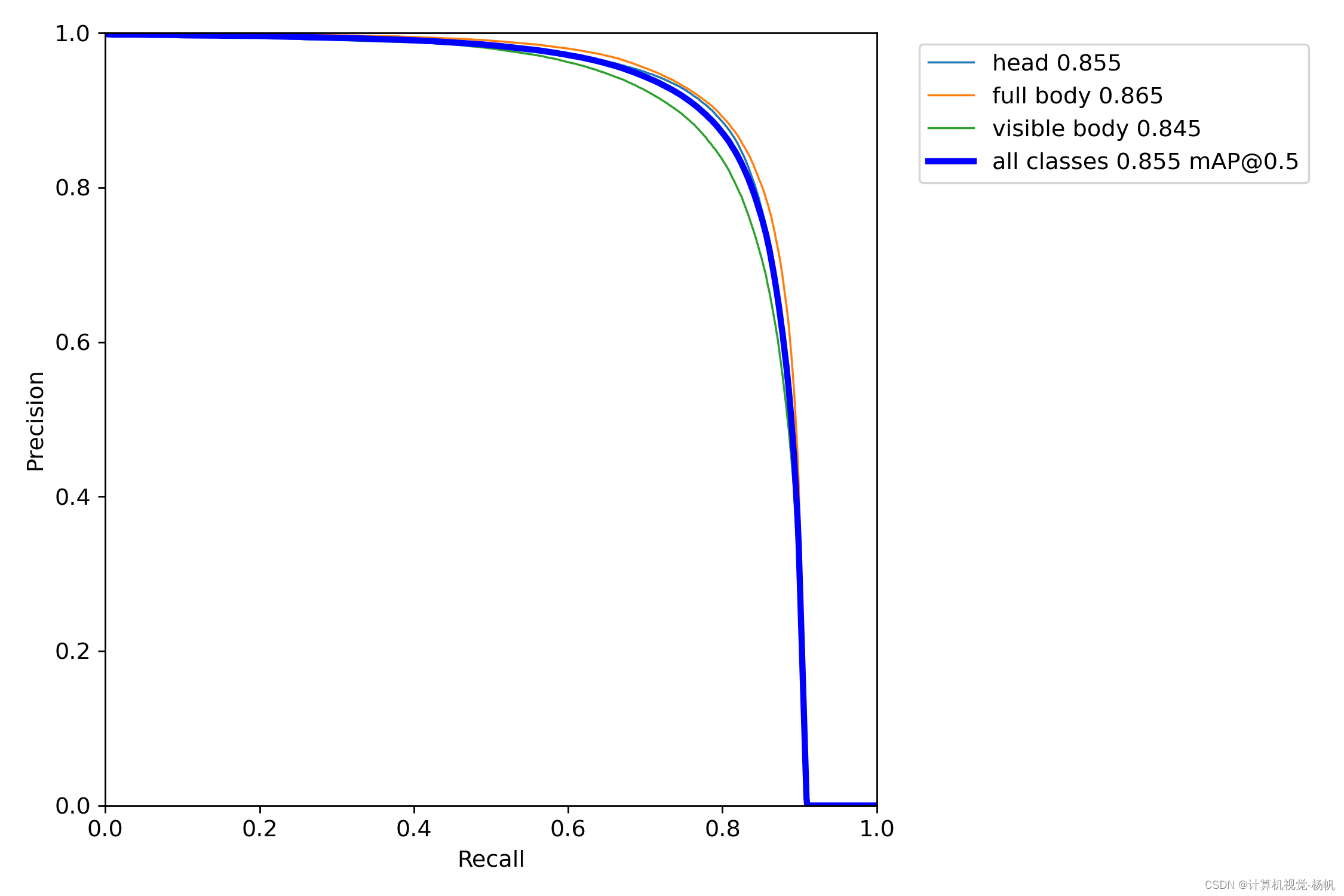
PR_curve.png
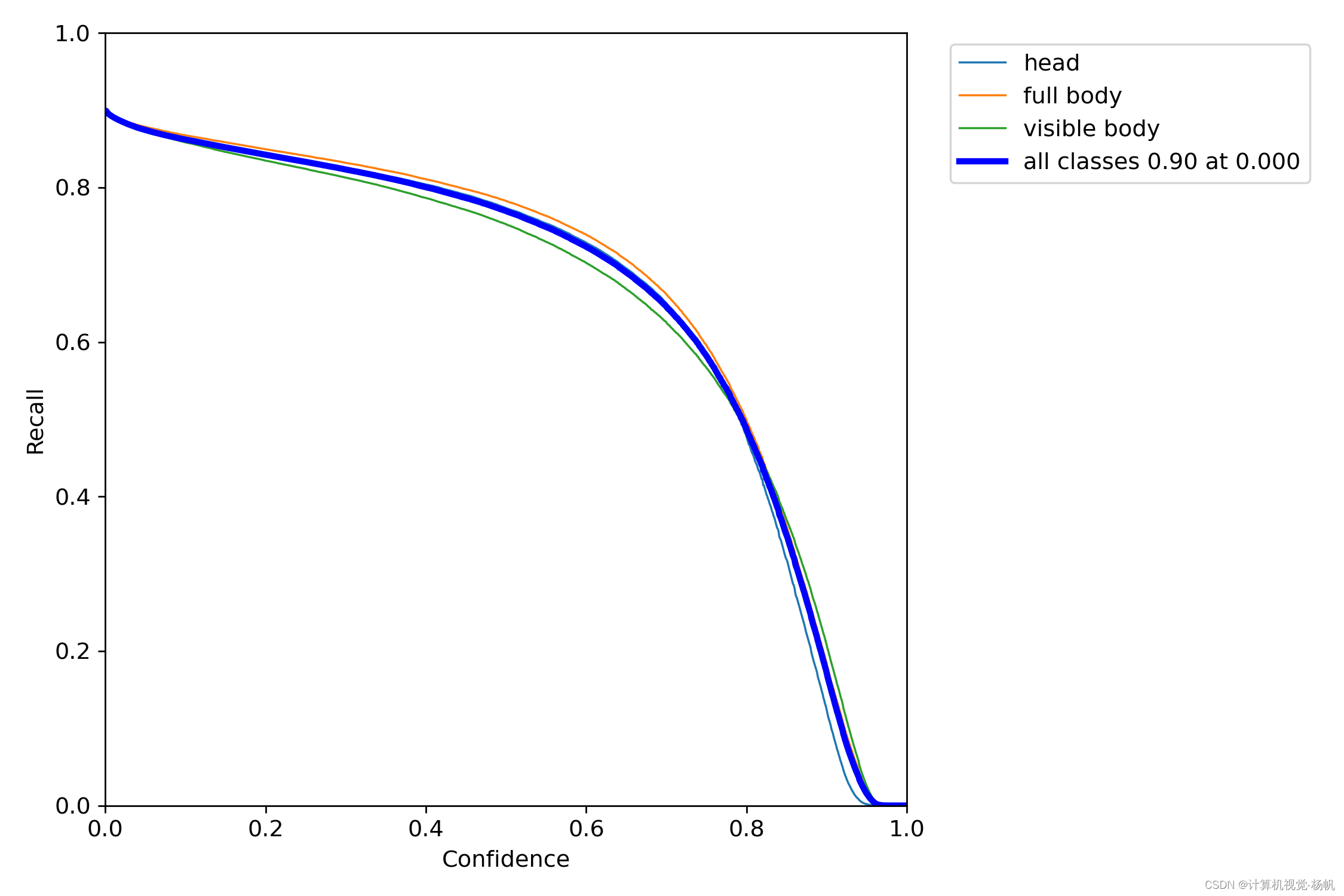
R_curve.png
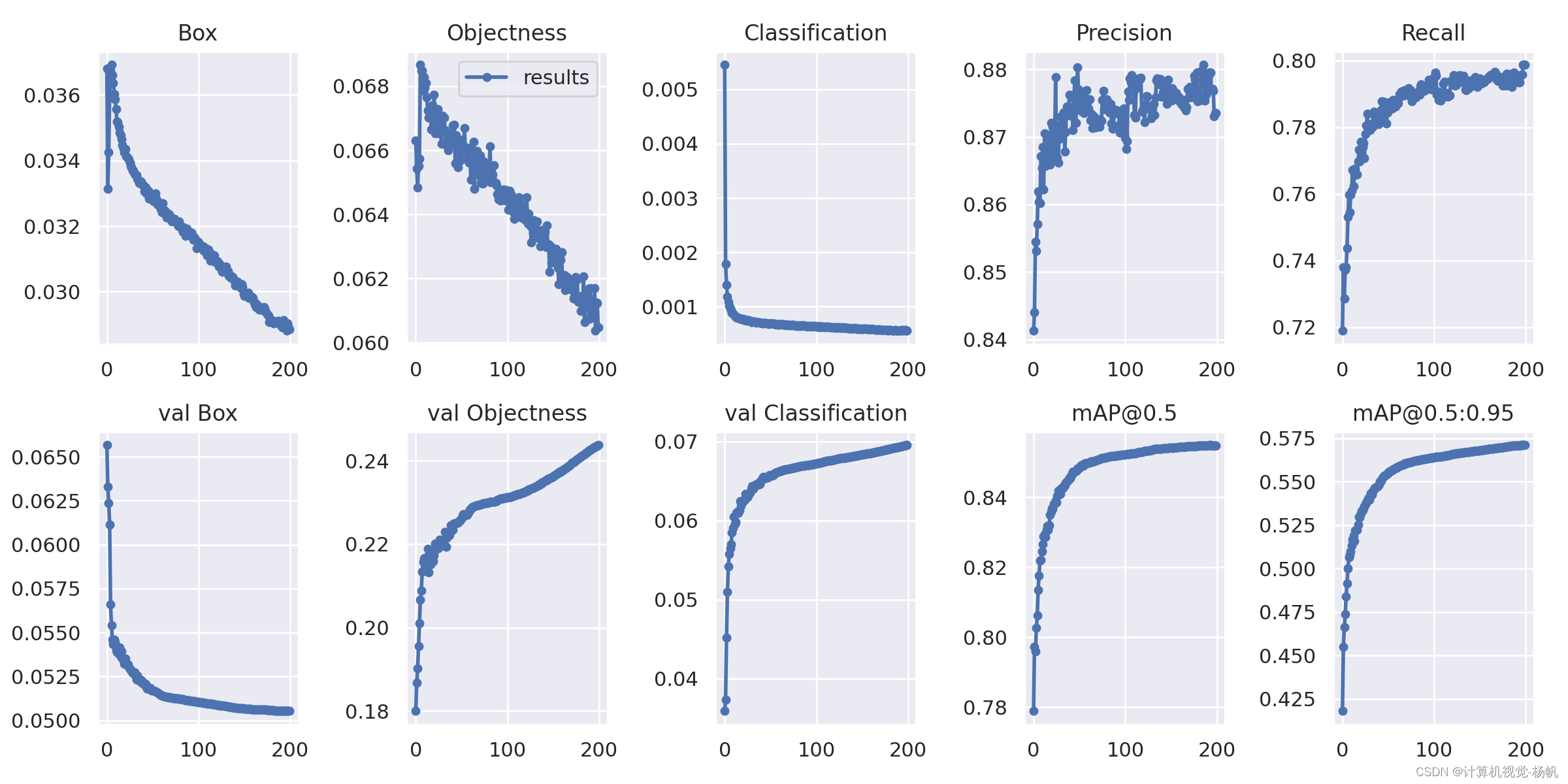
results.png
这篇关于yolov7 训练crowded human 【head, full body, visible body box detection】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!