本文主要是介绍BEVDepth: Acquisition of Reliable Depth for Multi-view 3D Object Detection 论文笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文链接:https://arxiv.org/abs/2206.10092
1.引言
目前的图像3D目标检测方法在深度估计上的效果很差。基于深度3D检测器特点:
- 若无真实深度的监督,虽然最终的3D检测结果鼓励模型输出正确的深度,但要学习到精确的深度是很困难的;
- 此外,理论上深度子网络应该根据相机内外参推断深度,但目前方法都没有这么做;
- 深度估计后的视图转换子网络很低效,比不基于深度的方法有更慢的速度。
本文的BEVDepth网络使用来自点云的稀疏深度监督;考虑到运动时的外参扰动引起的真实深度扰动,提出深度校正网络;为了在预测深度时利用相机参数,使用了相机感知注意力模块;提出高效体素池化操作,快速将图像特征投影到BEV,减小视图转换的时间和计算量。
3.BEVDepth
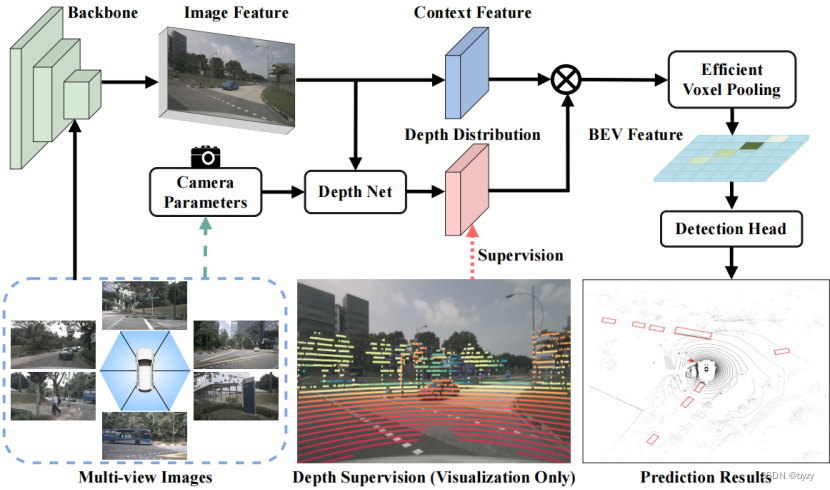
总体结构:原始的BEVDepth就是LSS主干加上CenterPoint检测头。如上图所示,BEVDepth包含图像编码器(提取图像特征)、DepthNet(用图像特征估计离散的图像深度图
)、视图转换器(将图像特征按
转换到3D空间得到
,并池化为BEV表达)、3D检测头(预测类别、边界框偏差和其他属性)。
显式的深度监督:使用点云数据得到深度监督
。设
和
为自车坐标(点云坐标)到第
个相机坐标的旋转和平移矩阵,
为该相机的内参。首先计算
并进一步转化为2.5D图像坐标(
为图像像素坐标)。未投影到图像上的点被丢弃。
为对齐投影点云和预测深度,在使用了最小池化和独热编码(记为操作
),则真实离散深度图为
。
深度估计损失使用二元交叉熵损失。
深度校正:由于上一步中使用的和
参数可能由于自车运动而不精确,从而导致
和
不对齐,这在DepthNet的感受野很小的时候存在大问题。深度校正网络通过增大DepthNet的感受野来解决不对齐问题,即在DepthNet中使用多个残差块和可变形卷积,如下图的右下角所示。
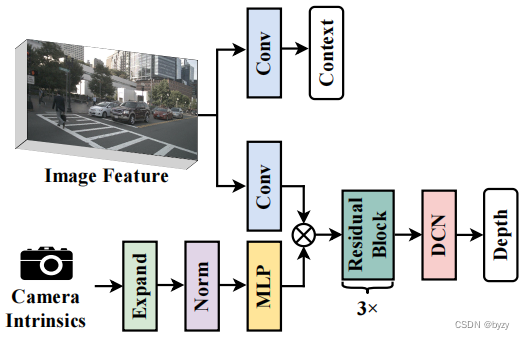
相机感知的深度预测:经典相机模型中,估计深度需要相机内参。首先将相机内参通过MLP放大到特征图的尺寸,然后通过Squeeze-and-Excitation模块(见此文第三点)用其重新加权图像特征。此外,将相机的外参与内参拼接,帮助DepthNet感知在自车坐标系下的空间位置。因此整个相机感知的深度预测可写为
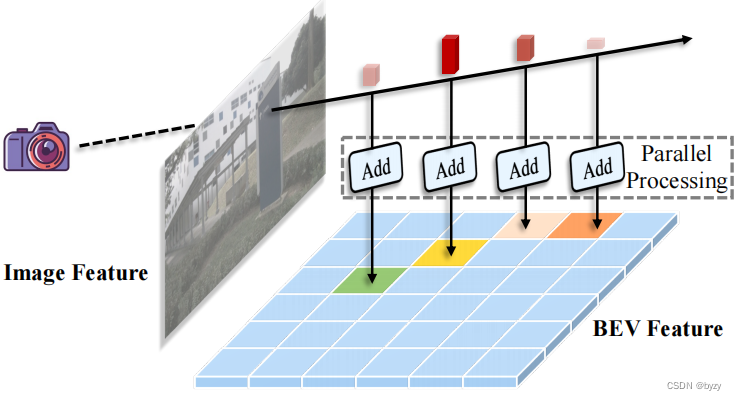
高效体素池化:该模块将3D特征转化为2D BEV特征,即将落在每个BEV网格内的3D特征求和。在LSS中使用累加求和技巧,但其排序操作和累加求和的顺序性都引入了额外计算时间。本文的高效体素池化如下图所示,思想是为每个棱台特征分配一个CUDA线程,将其添加到相应的BEV网格中。
4.实验
4.1 实验设置
深度估计任务的评价指标为尺度不变对数误差(SILog)、平均相对误差绝对值(Abs Rel)、均方相对误差(Sq Rel)、平均log10误差(log10)和均方根误差(RMSE)。
使用图像数据增广如随机裁剪、缩放、翻转、旋转,以及BEV特征数据增广如随机缩放、翻转和旋转。
4.2 消融研究
显式深度监督和深度校正:原始的BEVDepth的深度估计误差很大;增加显式深度监督和深度校正后,总体和各项检测精度均有所提升,且深度估计误差大幅减小。
相机感知:引入相机内外参的编码后,检测精度和深度估计精度也都有一定提升。
高效体素池化:该操作使得训练和推断速度均能加快到3至4倍。
多帧融合:直接拼接相邻两帧的BEV特征会导致自车运动带来的空间不对齐;本文通过对齐中间的点云(即将上一帧的点转换到当前帧的自车坐标下:,其中
为平移-旋转矩阵),然后进行体素池化,得到对齐的BEV特征。
实验表明多帧方法能减小速度/属性估计误差,并提高检测精度。
4.3 主要结果
相比于其余方法,本文的定位误差大幅下降,表明深度预测的精度高。
这篇关于BEVDepth: Acquisition of Reliable Depth for Multi-view 3D Object Detection 论文笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




