本文主要是介绍文章解读 -- MotionNet: Joint Perception and Motion Prediction for Autonomous Driving Based on Bird’s Eye,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章解读 – MotionNet: Joint Perception and Motion Prediction for Autonomous Driving Based on Bird’s Eye View Maps
摘要
可靠地感知环境状态的能力,特别是对物体的存在以及它们的运动行为判断,对于自动驾驶至关重要。在这项工作中,我们提出了一个高效的深度模型,称为 MotionNet,用于从 3D 点云同时执行感知和运动预测。 MotionNet 将一系列LiDAR扫描作为输入,输出鸟瞰图 (BEV),在每个网格单元将对象类别和运动信息编码。MotionNet的主干网络是一种新颖的时空金字塔网络,它以分层方式提取深层空间和时间特征。为了在空间和时间上加强预测的平滑性,MotionNet加入空间和时间一致性loss。大量实验表明,提出的方法总体上优于最先进的方法,包括最新的场景流和基于3D对象检测的方法。这表明提议方法的潜在价值,可以作为基于边框的系统的备份,并在自动驾驶中向运动规划提供补充信息。
1. 介绍
环境状态评价通常包括两个任务:(1)感知,从背景中识别前景对象;(2)运动预测,预测对象的未来轨迹。传统的环境感知方法主要依赖于包围盒的检测,通过图像2D,点云3D和融合的方式。检测的包围盒被送入到追踪器中,进行运动预测。另一个可替代方向是使用占据格网图(OGM)代表环境信息,可以为可行驶区域和运动规划提供支持。缺点是随时间,难以找到网格之间的联系,而且物体类别信息被丢弃了。
基于此,BEVmap拓展了OGM,提供了三个重叠的信息:占据、运动和类别信息。我们的模型MotionNet,即使针对训练集中没有的物体。模型的核心是新奇的时空金字塔网路(STPN),STPN在层次结构中执行一系列时空卷积(STC),每个STC依赖于2D空间卷积,然后是轻量级的伪 1D 时间卷积,STPN 的输出被传送到不同的头:网格分类、状态估计和运动预测。
总结我们做的主要工作:
- 我们提出了一种新的模型,称为MotionNet,用于同时进行BEV图的感知和运动预测。MotionNet对边界框不做要求,可以为自动驾驶提供补充信息;
- 我们提出了一种新颖的时空金字塔网络,在层次结构中提取时空特征。这种结构轻巧高效,适合实时部署;
- 我们开发空间和时间一致性loss,来约束网络训练,在空间和时间上加强预测的平滑性;
- 大量实验验证了我们的有效性方法,并提供深入的分析来说明,我们设计背后的动机。
2. 相关工作
感知。现有检测工作分三类:图像2D,点云3D和融合的方式。
运动预测。典型方法是依赖于准确的物体检测和追踪轨迹的获取。另一种是联合3D物体检测、追踪和运动预测。
流估计。依赖于输入数据,运动信息从2D光流和3D场景流获取。
3. 方法
在本节中,我们介绍 MotionNet,见下图。包括三个部分:
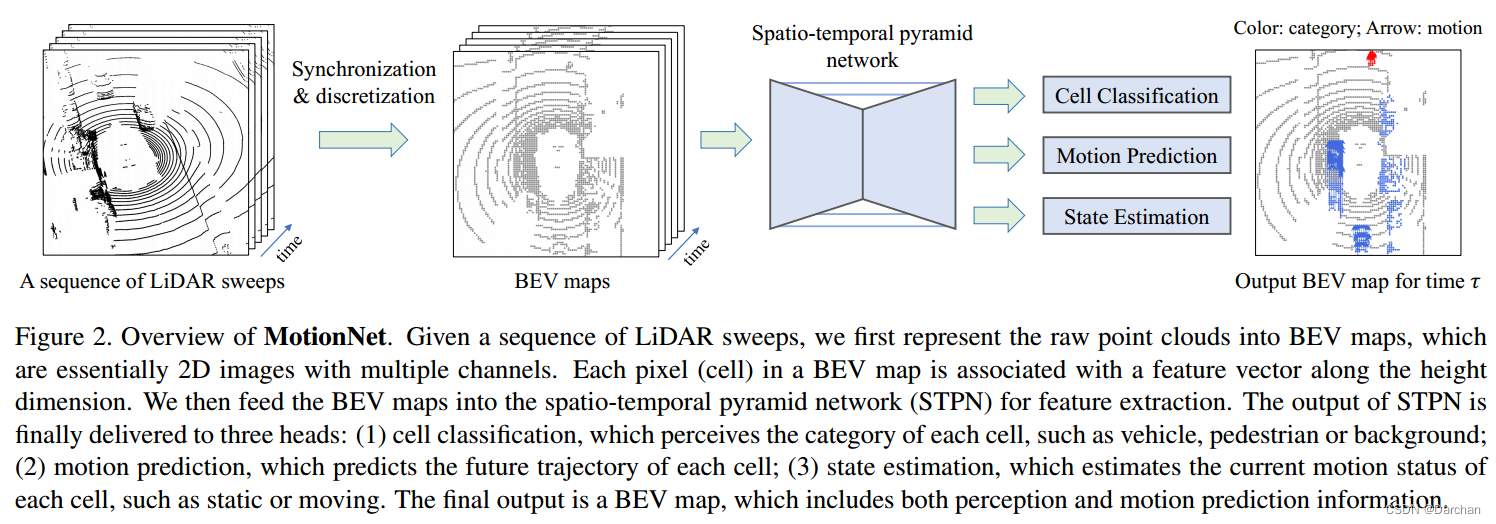
(1) 原始 3D 点云到 BEV 地图的转化;
(2) 时空金字塔网络作为骨干;
(3) 特定任务head,用于网格单元分类和运动预测。
3.1 自身运动补偿
我们需要将所有过去的多帧同步对齐到当前的帧,即表示其中的所有点云都是基于当前坐标系,这样避免了自车运动所带来的影响。
3.2 基于BEV地图的表征
不像PointNet那种每个体素带有高维特征,我们只使用二进制0/1代表体素,表示体素是否有点云占据。然后将3D体素转为为2D伪图像,高度的维度对应图像里面的通道。通过标准2D卷积计算,软硬件支持更友好。
3.3 时空塔式网络
参考视频分类任务的相关成果,我们使用low-cost(例如2D卷积)取代笨重的3D卷积。我们目标是分类当前时刻每一个BEV格子单元和估计它的未来位置。有两个问题需要阐述:一是何时和怎样做才能增强时序特征,二是怎样提取多尺度的时空特征,该特征用来捕获局部和全局语义。下图是SPTN网络结构,由STC模块组成,内部包含标准的2D卷积,来捕获时空特征。3D卷积的核大小是k×1×1,其中k对应于时间维度。这样的 3D 滤波器本质上是一个伪 1D 卷积,因此能够降低模型复杂性。

特别地,对于空间维度,我们使用缩放步数:2,在多个尺度上计算特征图。同样,对于时间维度,我们每层时间卷积后,逐渐降低的时间分辨率,从而提取不同的时间语义。我们使用全局的时序池化来提取显著的时间特征,通过横向链接将他们传递给特征解码的上采样层。
3.4 输出头
我们再SPTN网络结束位置增加了3个头:
1)单元格分类头,对BEV图分割和感知每个格的类别;
2)运动预测头,预测未来单元格的位置;
3)状态估计头,估计每个单元格运动状态,为运动预测提供辅助信息。
运动预测头采用平滑L1的loss进行训练,但是可能会带来静态单元格的异常抖动。我们从其他两个头的输出来规范单元格的轨迹。对于静态背景,如停靠的车辆,使用阈值参数来抑制。
评论。与基于边界框的方法相比,上述设计可能能够更好地感知训练集之外的物体。
3.5 loss 函数
对于分类与状态估计头,我们使用交叉商loss,运动预测头我们使用平滑的L1 loss。以上的loss,仅能够在全局范围内规范网络训练,但不保证局部的时空一致性,故需要增加以下的loss。
-
空间一致性loss。
L s = ∑ ∑ ∥ X i , j r − X i ‘ , j ‘ r ∥ L_s = \sum \sum \lVert X_{i,j}^{r} -X_{i^`,j^`}^{r} \rVert Ls=∑∑∥Xi,jr−Xi‘,j‘r∥
对于同一个物体Ok,被分辨率划分为几个cell,但是物体作为一个刚性整体,理论上每一个cell的运动向量X(i,j)是一样的。X代表预测位置(i,j),为了减少计算,我们只选择一个物体两个临近的cell位置,它只是物体很多cell集合的子集,只对其做计算。 -
前景时序一致性loss。
L f t = ∑ ∥ X o k r − X o k r + t ∥ L_{ft}= \sum \lVert X_{ok}^{r} -X_{ok}^{r+t} \rVert Lft=∑∥Xokr−Xokr+t∥
我们认为连续两帧之间运动不会出现尖锐的变化,这里的X是代表物体k的各个cell的平均运动。 -
背景时序一致性loss。
L b t = ∑ ∥ X i , j r − T i , j ( X ~ r − t ) ∥ L_{bt}= \sum \lVert X_{i,j}^{r} -T_{i,j}(\tilde X^{r-t}) \rVert Lbt=∑∥Xi,jr−Ti,j(X~r−t)∥
其中T代表自身运动,或者从ICP配置算法得到。前一帧属于背景运动cell是静止的,后一帧对于前一帧的背景cell状态进行刚体变换后,在相同的(i,j)位置,求解L1 Loss。 -
总的loss如下:
L = L c l s + L m o t i o n + L s t a t e + α L s + β L f t + γ L b t L = L_{cls} + L_{motion} + L_{state} + \alpha L_s + \beta L_{ft} + \gamma L_{bt} L=Lcls+Lmotion+Lstate+αLs+βLft+γLbt
4. 实验
利用nuScene数据集做的评估实验。
数据集。
++单元格运动的真值获取,将每个bbox中的每个单元运动,计算方式为Rx+c-x,R是box中心位置相对自车的旋转,x代表单元格的位置,c是bbox的中心++。bbox以外的单元格,我们将运动信息置为0。850个场景数据,500个训练,100个验证,250个测试。
我们将每个场景分成片段作为输入网络。为了减少冗余,每个剪辑片段只包含对应于当前时间的关键帧,以及与关键帧同步的四个历史帧。关键帧以2Hz采样用于训练,而对于验证/测试它们以1Hz采样以减少相似性。每个剪辑片段中,两连续的时间跨度为200ms。增加一些剪辑片段(关键帧+50ms),与关键帧剪辑片段组成对,用来计算时序一致性loss。
实现细节。
点云范围[-32,32]×[-32,32]×[-3,2],voxel尺寸(0.25,0.25,0.4)。我们使用连续的5帧提取时序信息,定义了五种类别:背景,车辆,行人,自行车,其他。其他包含nuScene中所有存在的前景目标。
评价标准。
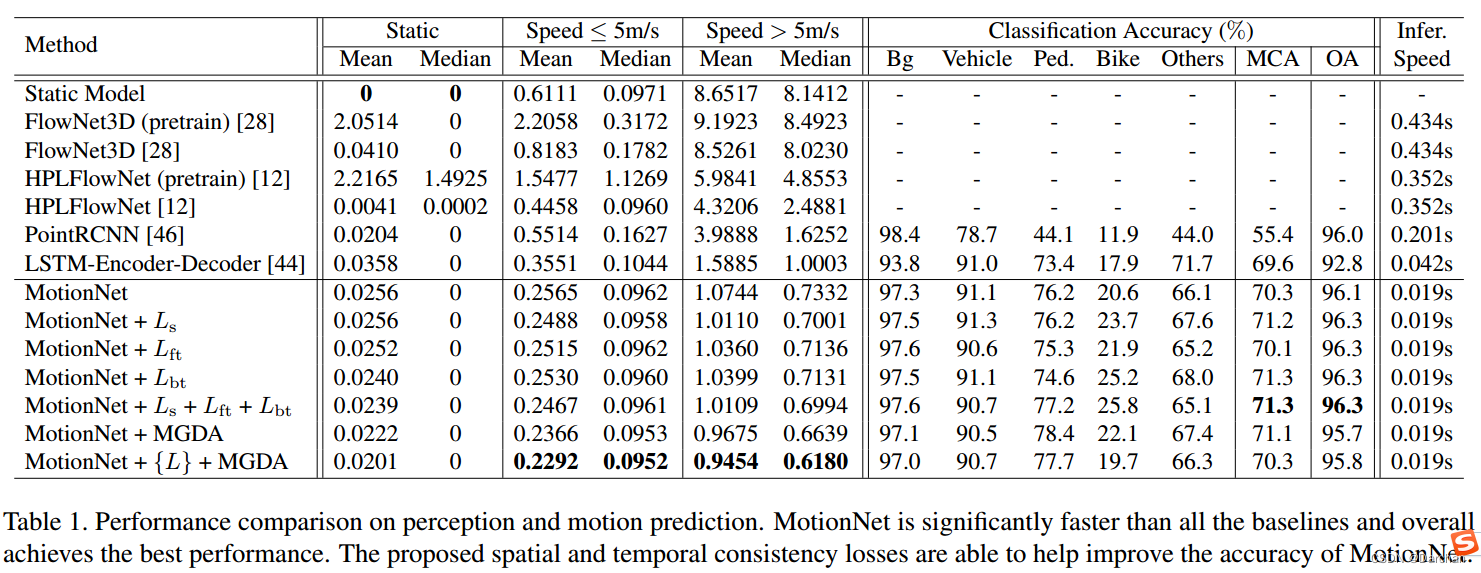
对于运动预测,将单元格分成三类速度:静态,低速(<5m/s),高速(>5m/s)。每一个组别中计算平均值和中值。
对于分类:单元格分类准确度(OA),平均类别准确度(MCA)。
4.1 结果
4.2 消融实验
主要测试几个影响因素:帧数、自运动补偿、输入数据表征、时空特征提取、预测策略
这篇关于文章解读 -- MotionNet: Joint Perception and Motion Prediction for Autonomous Driving Based on Bird’s Eye的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







