本文主要是介绍Hadoop3.0大数据处理学习3(MapReduce原理分析、日志归集、序列化机制、Yarn资源调度器),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
MapReduce原理分析
什么是MapReduce
前言:如果想知道一堆牌中有多少张红桃,直接的方式是一张张的检查,并数出有多少张红桃。
而MapReduce的方法是,给所有的节点分配这堆牌,让每个节点计算自己手中有几张是红桃,然后将这个数汇总,得到结果。
概述
- 官方介绍:MapReduce是一种分布式计算模型,由Google提出,主要用于搜索领域,解决海量数据的计算问题。
- MapReduce是分布式运行的,由俩个阶段组成:Map和Reduce。
- MapReduce框架都有默认实现,用户只需要覆盖map()和reduce()俩个函数,即可实现分布式计算。
原理分析
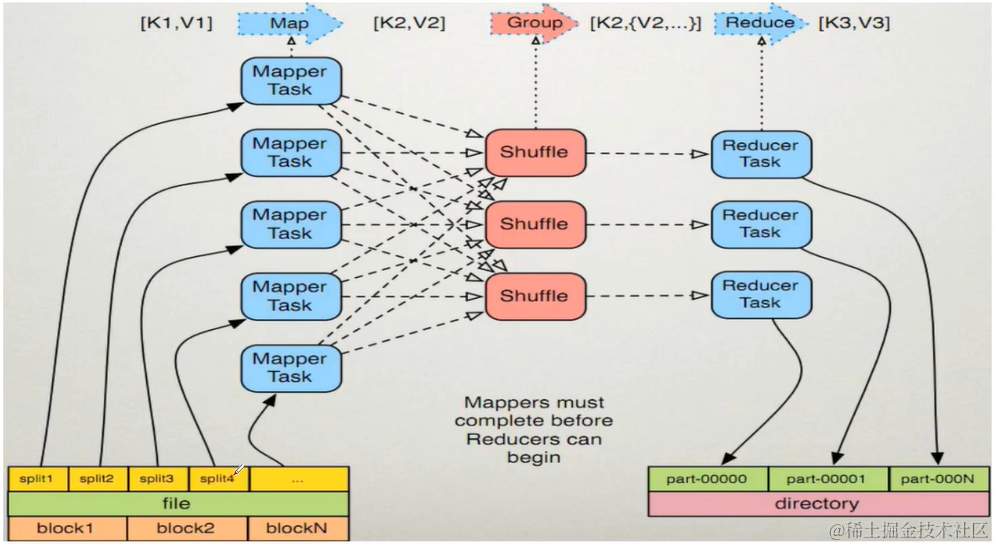
Map阶段执行过程
- 框架会把输入文件划分为很多InputSplit,默认每个hdfs的block对应一个InputSplit。通过RecordReader类,将每个InputSplit解析为一个个键值对<K1,V1>。默认每一个行会被解析成一个键值对。
- 框架会调用Mapper类中的map()函数,map函数的形参是<k1,v1>,输出是<k2,v2>。一个inputSplit对应一个map task。
- 框架对map函数输出的<k2,v2>进行分区。不同分区中的<k2,v2>由不同的reduce task处理,默认只有一个分区。
- 框架对每个分区中的数据,按照k2进行排序、分组。分组指的是相同k2的v2分为一组。
- 在map节点,框架可以执行reduce规约,此步骤为可选。
- 框架会把map task输出的<k2,v2>写入linux的磁盘文件
Reduce阶段执行过程
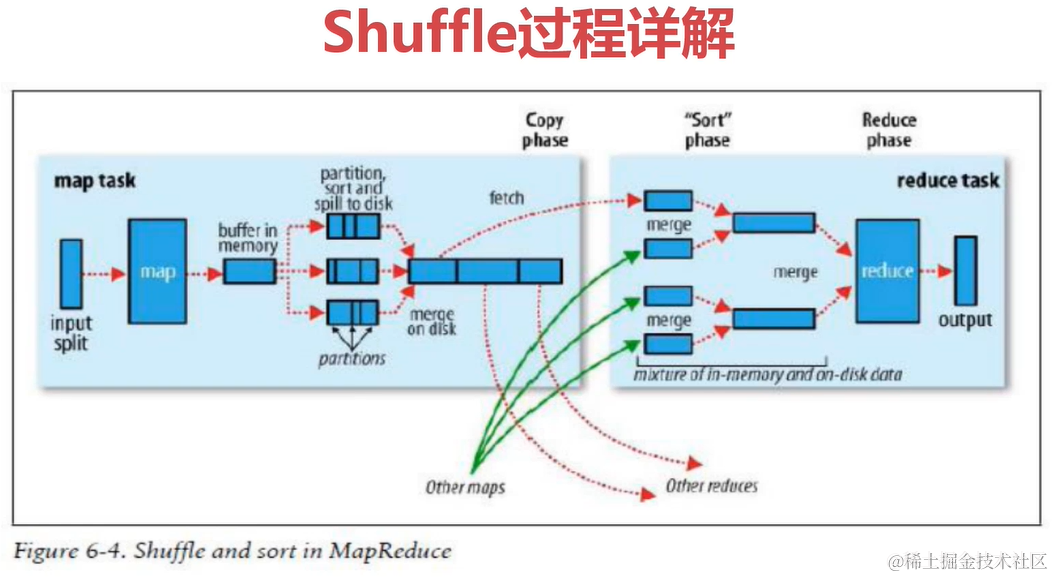
- 框架对多个map任务的输出,按照不同的分区,通过网络copy到不同的reduce节点,这个过程称为shuffle。
- 框架对reduce端接收到的相同分区的<k2,v2>数据进行合并、排序、分组
- 框架调用reduce类中的reduce方法,输入<k2,[v2…]>,输出<k3,v3>。一个<k2,[v2…]>调用一次reduce函数。
- 框架把reduce的输出保存到hdfs。
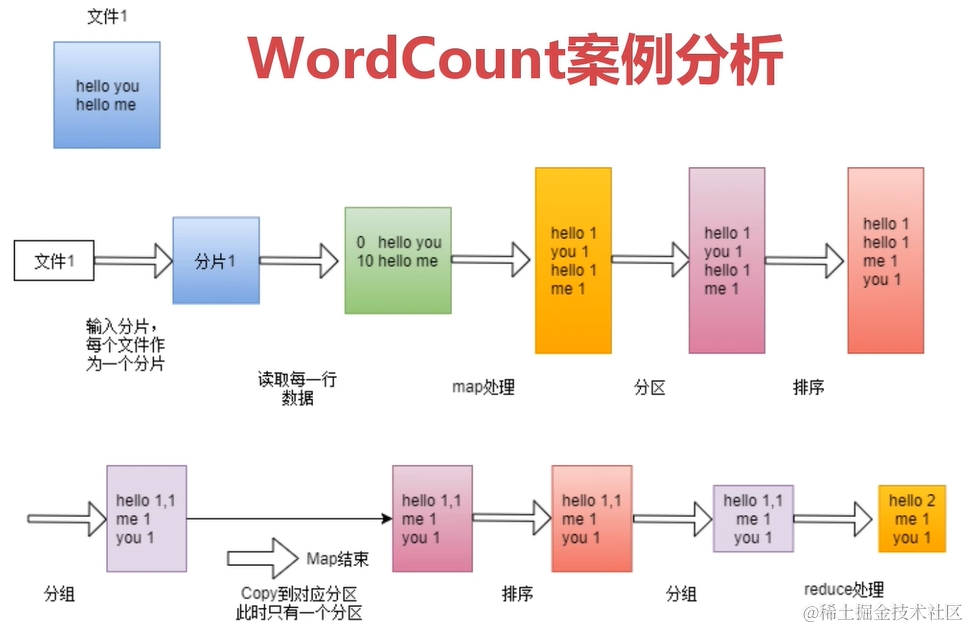
WordCount案例分析
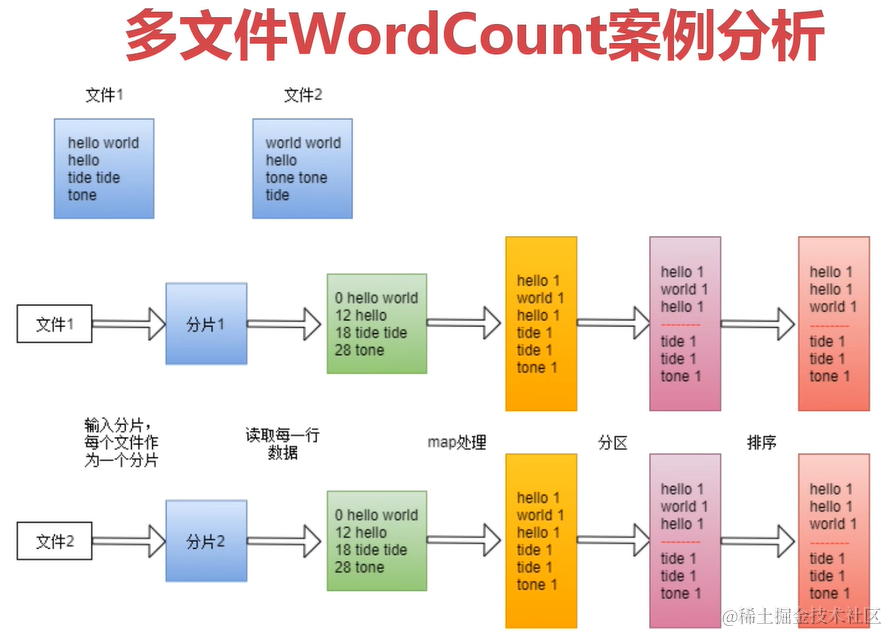
多文件WordCount案例分析
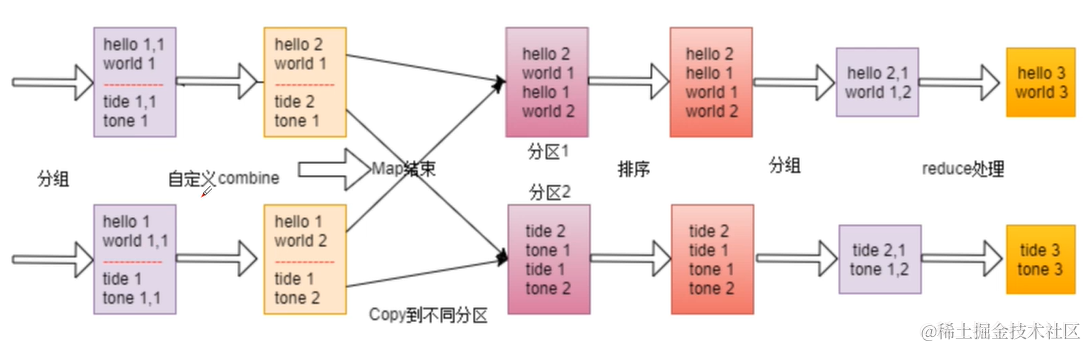
Shuffle过程详解
shuffle是一个过程,贯穿map和reduce,通过网络将map产生的数据放到reduce。
Map与Reduce的WordsCount案例(与日志查看)
引入依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>2.7.14</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.hx</groupId><artifactId>hadoopDemo1</artifactId><version>0.0.1-SNAPSHOT</version><name>hadoopDemo1</name><description>Demo project for Spring Boot</description><properties><java.version>1.8</java.version></properties><dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.3.0</version><scope>provided</scope></dependency></dependencies>
</project>
编码
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;/*** @author Huathy* @date 2023-10-21 21:17* @description 组装任务*/
public class WordCountJob {public static void main(String[] args) throws Exception {System.out.println("inputPath => " + args[0]);System.out.println("outputPath => " + args[1]);String path = args[0];String path2 = args[1];// job需要的配置参数Configuration configuration = new Configuration();// 创建jobJob job = Job.getInstance(configuration, "wordCountJob");// 注意:这一行必须设置,否则在集群的时候将无法找到Job类job.setJarByClass(WordCountJob.class);// 指定输入文件FileInputFormat.setInputPaths(job, new Path(path));FileOutputFormat.setOutputPath(job, new Path(path2));job.setMapperClass(WordMap.class);job.setReducerClass(WordReduce.class);// 指定map相关配置job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(LongWritable.class);// 指定reducejob.setOutputKeyClass(Text.class);job.setOutputValueClass(LongWritable.class);// 提交任务job.waitForCompletion(true);}/*** @author Huathy* @date 2023-10-21 21:39* @description 创建自定义映射类* 定义输入输出类型*/public static class WordMap extends Mapper<LongWritable, Text, Text, LongWritable> {/*** 需要实现map函数* 这个map函数就是可以接受keyIn,valueIn,产生keyOut、ValueOut** @param k1* @param v1* @param context* @throws IOException* @throws InterruptedException*/@Overrideprotected void map(LongWritable k1, Text v1, Context context) throws IOException, InterruptedException {// k1表示每行的行首偏移量,v1表示每一行的内容// 对获取到的每一行数据进行切割,把单词切割出来String[] words = v1.toString().split("\W");// 迭代切割的单词数据for (String word : words) {// 将迭代的单词封装为<k2,v2>的形式Text k2 = new Text(word);System.out.println("k2: " + k2.toString());LongWritable v2 = new LongWritable(1);// 将<k2,v2>输出context.write(k2, v2);}}}/*** @author Huathy* @date 2023-10-21 22:08* @description 自定义的reducer类*/public static class WordReduce extends Reducer<Text, LongWritable, Text, LongWritable> {/*** 针对v2s的数据进行累加求和,并且把最终的数据转为k3,v3输出** @param k2* @param v2s* @param context* @throws IOException* @throws InterruptedException*/@Overrideprotected void reduce(Text k2, Iterable<LongWritable> v2s, Context context) throws IOException, InterruptedException {long sum = 0L;for (LongWritable v2 : v2s) {sum += v2.get();}// 组装K3,V3LongWritable v3 = new LongWritable(sum);System.out.println("k3: " + k2.toString() + " -- v3: " + v3.toString());context.write(k2, v3);}}}
运行命令与输出日志
[root@cent7-1 hadoop-3.2.4]# hadoop jar wc.jar WordCountJob hdfs://cent7-1:9000/hello.txt hdfs://cent7-1:9000/out /home/hadoop-3.2.4/wc.jar
inputPath => hdfs://cent7-1:9000/hello.txt
outputPath => hdfs://cent7-1:9000/out
set jar => /home/hadoop-3.2.4/wc.jar
2023-10-22 15:30:34,183 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
2023-10-22 15:30:35,183 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2023-10-22 15:30:35,342 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1697944187818_0010
2023-10-22 15:30:36,196 INFO input.FileInputFormat: Total input files to process : 1
2023-10-22 15:30:37,320 INFO mapreduce.JobSubmitter: number of splits:1
2023-10-22 15:30:37,694 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1697944187818_0010
2023-10-22 15:30:37,696 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-10-22 15:30:38,033 INFO conf.Configuration: resource-types.xml not found
2023-10-22 15:30:38,034 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2023-10-22 15:30:38,188 INFO impl.YarnClientImpl: Submitted application application_1697944187818_0010
2023-10-22 15:30:38,248 INFO mapreduce.Job: The url to track the job: http://cent7-1:8088/proxy/application_1697944187818_0010/
2023-10-22 15:30:38,249 INFO mapreduce.Job: Running job: job_1697944187818_0010
2023-10-22 15:30:51,749 INFO mapreduce.Job: Job job_1697944187818_0010 running in uber mode : false
2023-10-22 15:30:51,751 INFO mapreduce.Job: map 0% reduce 0%
2023-10-22 15:30:59,254 INFO mapreduce.Job: map 100% reduce 0%
2023-10-22 15:31:08,410 INFO mapreduce.Job: map 100% reduce 100%
2023-10-22 15:31:09,447 INFO mapreduce.Job: Job job_1697944187818_0010 completed successfully
2023-10-22 15:31:09,578 INFO mapreduce.Job: Counters: 54File System CountersFILE: Number of bytes read=129FILE: Number of bytes written=479187FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=139HDFS: Number of bytes written=35HDFS: Number of read operations=8HDFS: Number of large read operations=0HDFS: Number of write operations=2HDFS: Number of bytes read erasure-coded=0Job Counters Launched map tasks=1Launched reduce tasks=1Data-local map tasks=1Total time spent by all maps in occupied slots (ms)=4916Total time spent by all reduces in occupied slots (ms)=5821Total time spent by all map tasks (ms)=4916Total time spent by all reduce tasks (ms)=5821Total vcore-milliseconds taken by all map tasks=4916Total vcore-milliseconds taken by all reduce tasks=5821Total megabyte-milliseconds taken by all map tasks=5033984Total megabyte-milliseconds taken by all reduce tasks=5960704Map-Reduce FrameworkMap input records=4Map output records=8Map output bytes=107Map output materialized bytes=129Input split bytes=94Combine input records=0Combine output records=0Reduce input groups=5Reduce shuffle bytes=129Reduce input records=8Reduce output records=5Spilled Records=16Shuffled Maps =1Failed Shuffles=0Merged Map outputs=1GC time elapsed (ms)=259CPU time spent (ms)=2990Physical memory (bytes) snapshot=528863232Virtual memory (bytes) snapshot=5158191104Total committed heap usage (bytes)=378011648Peak Map Physical memory (bytes)=325742592Peak Map Virtual memory (bytes)=2575839232Peak Reduce Physical memory (bytes)=203120640Peak Reduce Virtual memory (bytes)=2582351872Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format Counters Bytes Read=45File Output Format Counters Bytes Written=35
[root@cent7-1 hadoop-3.2.4]#
MapReduce任务日志查看
- 开启yarn日志聚合功能,将散落在nodemanager节点的日志统一收集管理,方便查看
- 修改yarn-site.xml中的yarn.log-aggregation-enable和yarn.log.server.url
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property>
<property><name>yarn.log.server.url</name><value>http://cent7-1:19888/jobhistory/logs/</value>
</property>
- 启动historyserver:
sbin/mr-jobhistory-daemon.sh start historyserver
UI界面查看
-
访问 http://192.168.56.101:8088/cluster ,点击History
-
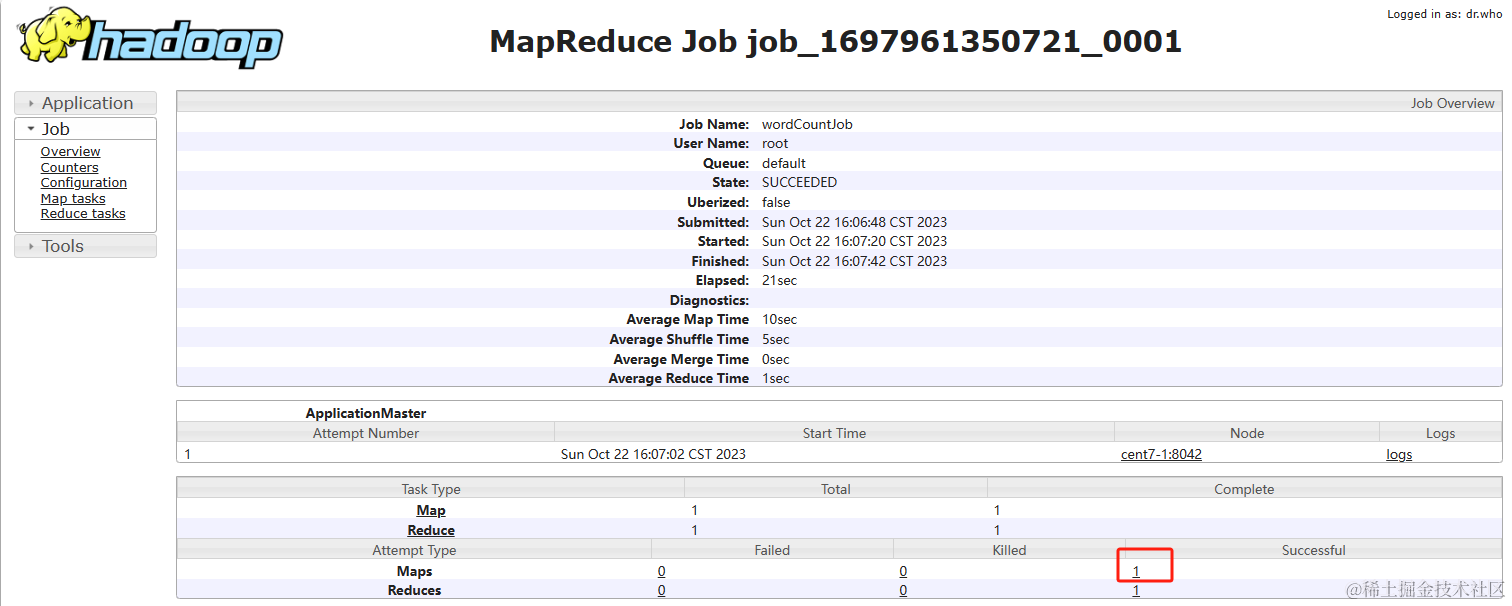
点进Successful
-
看到成功记录,点击logs可以看到成功日志
停止Hadoop集群中的任务
Ctrl+C退出终端,并不会结束任务,因为任务已经提交到了Hadoop
- 查看任务列表:
yarn application -list - 结束任务进程:
yarn application -kill [application_Id]
# 查看正在进行的任务列表
[root@cent7-1 hadoop-3.2.4]# yarn application -list
2023-10-22 16:18:38,756 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
Total number of applications (application-types: [], states: [SUBMITTED, ACCEPTED, RUNNING] and tags: []):1Application-Id Application-Name Application-Type User Queue State Final-State Progress Tracking-URL
application_1697961350721_0002 wordCountJob MAPREDUCE root default ACCEPTED UNDEFINED 0% N/A
# 结束任务
[root@cent7-1 hadoop-3.2.4]# yarn application -kill application_1697961350721_0002
2023-10-22 16:18:55,669 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
Killing application application_1697961350721_0002
2023-10-22 16:18:56,795 INFO impl.YarnClientImpl: Killed application application_1697961350721_0002
Hadoop序列化机制
序列化机制作用
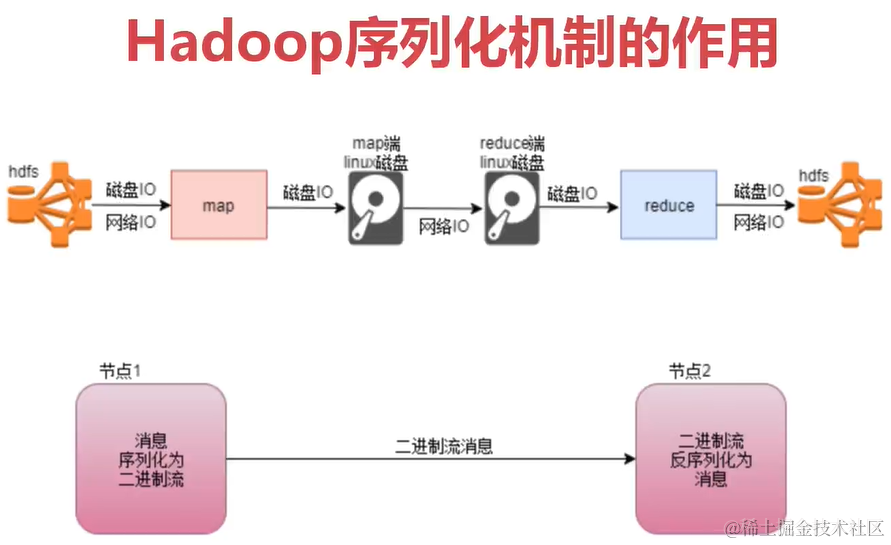
上面可以看出,Hadoop运行的时候大多数IO操作。我们在编写Hadoop的Map和Reduce代码的时候,用的都是Hadoop官方提供的数据类型,Hadoop官方对序列化做了优化,只会序列化核心内容来减少IO开销。
Hadoop序列化机制的特点
- 紧凑:高效的使用存储空间
- 快速:读写数据的额外开销小
- 可扩展:可透明的读取老格式的数据
- 互操作:支持多语言操作
Java序列化的不足
- 不够精简,附加信息多,不适合随机访问
- 存储空间占用大,递归输出类的父类描述,直到不再有父类
- 扩展性差,Hadoop中的Writable可以方便用户自定义
资源管理器(Yarn)详解
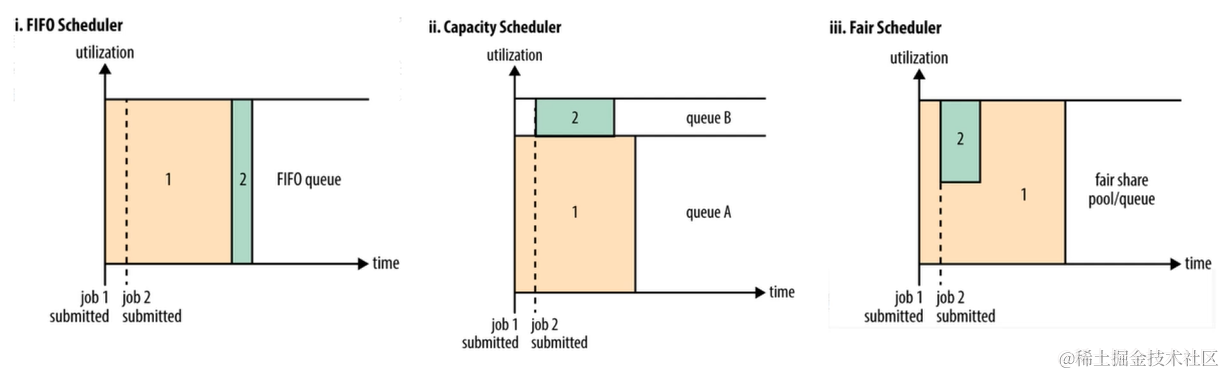
- Yarn目前支持三种调度器:(针对任务的调度器)
- FIFO Scheduler:先进先出调度策略(工作中存在实时任务和离线任务,先进先出可能不太适合业务)
- CapacityScheduler:可以看作是FIFO的多队列版本。可以分成多个队列,每个队列里面是先进先出的。
- FairScheduler:多队列,多用户共享资源。公平任务调度(建议使用)。
这篇关于Hadoop3.0大数据处理学习3(MapReduce原理分析、日志归集、序列化机制、Yarn资源调度器)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





