本文主要是介绍谣言检测论文阅读 - Rumor Detection on Social Media with Bi-Directional Graph Convolutional Networks,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文链接:https://arxiv.org/pdf/2001.06362.pdf
目录
摘要
1 简介
2 相关工作
3 初步说明
表示法
图卷积网络
DropEdge
Bi-GCN谣言检测模型
1 构造传播图和散布图
2 计算高级节点表示
3 根特征增强
4 谣言分类的传播和散布表示
4 实验
设置和数据集
整体表现
消融研究
早期谣言检测
5 结论
摘要
背景介绍:
社会媒体由于其传播新信息的特性,在公共领域得到了迅速的发展,导致了谣言的传播。与此同时,从社交媒体上如此庞大的信息中发现谣言正成为一个艰巨的挑战。
前人方法局限性:
因此,一些研究采用了深度学习方法,如递归神经网络(RvNN)等,通过谣言的传播方式来发现谣言。然而,这些深度学习方法只考虑了深度传播的模式,而忽略了谣言检测中广泛传播的结构。
本文方法:
实际上,传播和散播是谣言的两个重要特征。
本文提出了一种新的双向图模型——双向图卷积网络(Bi-GCN) ,通过对谣言的自顶向下和自底向上传播两种方式进行操作来探索这两种特性。
它利用一个 GCN 和一个自上而下的流言传播有向图来学习流言传播的模式;
一个 GCN 和一个反向的流言传播有向图来捕捉流言传播的结构。
此外,GCN 的每一层都包含了来自源文章的信息,以增强谣言根源的影响力。若干基准的实证结果令人鼓舞,证实了所提出的方法优于最先进的方法。
1 简介
进行谣言检测原因:
随着互联网的快速发展,社交媒体已经成为用户获取信息、表达意见和相互交流的便捷网络平台。随着越来越多的人热衷于参与关于热门话题的讨论,并在社交媒体上交流意见,出现了许多谣言。由于用户数量庞大,社交媒体容易访问,谣言可以在社交媒体上广泛而迅速地传播,给社会带来巨大的危害,并造成大量的经济损失。因此,针对谣言引起的潜在恐慌和威胁,迫切需要提出一种方法来尽早有效地识别社交媒体上的谣言。
Conventional detection methods:
传统的检测方法主要采用手工制作的特征 (例如用户特征,文本内容和传播模式) 来训练受监督的分类器,例如,决策树 (Castillo,Mendoza和Poblete 2011),Random Forest (Kwon等人2013),支持向量机 (SVM) (Yang等人2012)。一些研究应用更有效的特征,如用户评论(Giudice 2010) ,时间结构特征(Wu,Yang 和 Zhu 2015)和帖子的情绪态度(Liu et al。2015)。然而,这些方法主要依靠特征工程,这是非常耗时和劳动密集型。此外,这些手工制作的特征通常缺乏从传播和散布谣言中提取的高层次表现。
Deep learning methods:
最近的研究利用了深度学习方法,这些方法从传播路径/树或网络中挖掘高级表示来识别谣言。
recursive neural network局限性: 使用诸如长短期记忆 (LSTM) 、门控递归单元 (GRU) 和递归神经网络 (RvNN) (马等人2016; 马、Gao和Wong 2018) 之类的深度学习模型,因为它们能够从谣言随着时间的传播中学习顺序特征。但是,这些方法对效率有很大的限制,因为时间结构特征仅关注谣言的顺序传播,而忽略了谣言散布的影响。
CNN局限性: 谣言散布的结构也表明了谣言的某些传播行为。因此,一些研究试图通过调用基于卷积神经网络 (CNN) 的方法 (Yu等人,2017; Yu等人,2019) 来涉及谣言传播结构中的信息。基于CNN的方法可以获得局部邻居内的相关特征,但不能处理图或树中的全局结构关系 (Bruna等人2014)。因此,这些方法忽略了谣言传播的整体结构特征。实际上,CNN 的设计并不是为了从结构化数据中学习高级表示,而是为了学习图卷积网络(Graph Convolutional Network,GCN)(Kipf and Welling 2017)。
引入GCN方法:
因此,我们可以简单地将GCN应用于谣言检测吗?因为它已经在各个领域取得了成功的进展,如社交网络 (汉密尔顿、英和莱斯科维克2017) 、物理系统 (Battaglia等人2016) 和化学药物诊断 (Defferrard、Bresson,和Vandergheynst 2016)?答案是否定的。如图1(a)所示,GCN,或称为无定向GCN(UD-GCN),只依靠相关贴子之间的关系来聚合信息,但失去了后续的顺序。尽管UD-GCN具有处理谣言传播的全球结构特征的能力,但它并未考虑谣言传播的方向,但事实证明,谣言传播是谣言检测的重要线索 (吴,杨和朱2015)。具体而言,沿着关系链的深度传播 (Han等人2014) 和整个社会社区的广泛分散 (Thomas 2007) 是谣言的两个主要特征,渴望一种同时服务于两者的方法。
提出文本方法:
为了解决谣言的传播和散布问题,本文提出了一种新颖的双向GCN (Bi- GCN),它同时对谣言的自上而下和自下而上传播进行操作。该方法分别通过自上而下的图卷积网络 (td-gcn) 和自下而上的图卷积网络 (BU-GCN) 两部分获得传播和散播的特征。如图1(b) 和1(c) 所示,td-gcn表示来自谣言树中节点的父节点的信息以表示谣言传播,而BU-GCN则表示来自谣言树中节点的子节点的信息以表示谣言散布。
然后,通过完全连接将从TD-GCN和BU-GCN的嵌入中汇集的传播和散布表示合并在一起,以得出最终结果。同时,我们将谣言树中根的特征与每个GCN层的隐藏特征连接起来,以增强谣言根的影响。此外,我们在训练阶段采用DropEdge (Rong等人2019) 来避免模型的过度拟合问题。这项工作的主要贡献如下:
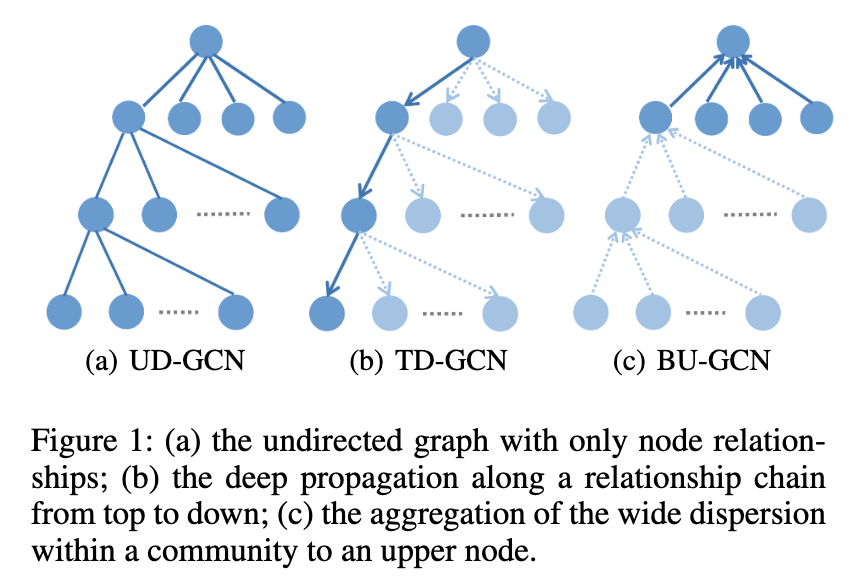
(图1 :( a) 仅具有节点关系的无向图; (b) 沿着关系链从上到下的深度传播; (c) 社区内广泛分散到上层节点的聚集。)
本文贡献点:
我们利用图卷积网络来检测谣言。据我们所知,这是第一个使用 GCN 在社会媒体谣言检测的研究;
我们提出了Bi-GCN模型,该模型不仅考虑了谣言沿着关系链从上到下传播的因果特征,而且还通过自下而上的收集从社区内的谣言散布中获得了结构特征。
我们将源帖子的特征与每个图卷积层的其他帖子连接起来,以综合利用根特征中的信息,并在谣言检测中获得出色的性能;
在三个真实数据集上的实验结果表明,我们的Bi-GCN方法优于几种最先进的方法; 对于早期发现谣言的任务,这对于实时识别谣言并防止其传播至关重要,bi-GCN也取得了更高的效率。
2 相关工作
特征工程方法:
近年来,社交媒体上的自动谣言检测引起了人们的广泛关注。以前大多数关于谣言检测的工作主要集中在从文本内容,用户配置文件和传播结构中提取谣言特征,以从标记数据中学习分类器(Castillo,Men-doza 和 Poblete 2011; Yang 等2012; Kwon 等2013; Liu 等2015; Zhao,Resnick 和 Mei 2015)。马等人通过使用时间序列对谣言进行分类,以模拟手工制作的社交环境特征的变化。Wu 等(Wu,Yang,and Zhu 2015)将 RBF 核与基于随机游走的图核相结合,提出了一种基于图核的混合支持向量机分类器。Ma et al。(Ma,Gao,and Wong 2017)构建了一个传播树内核,通过评估传播树结构之间的相似性来检测谣言。这些方法不仅效率低下,而且严重依赖于手工特征工程来提取信息量大的特征集。
深度学习方案:
为了自动学习高级特征,提出了一系列基于深度学习模型的谣言检测方法。马等人利用递归神经网络 (RNN) 从时间内容特征中捕获隐藏表示 (马等人2016)。Chen等人 (Chen et al. 2018) 通过将注意力机制与RNN相结合以关注具有不同注意力的文本特征来改进这种方法。Yu等人 (Yu et al. 2017) 提出了一种基于卷积神经网络 (CNN) 的方法,用于学习分散在输入序列中的关键特征,并塑造重要特征之间的高级交互。Liu等人 (Liu和Wu 2018) 合并了RNN和CNN,以基于时间序列获得用户特征。最近马等人 (马,Gao和Wong 2019) 采用了对抗性学习方法来改善谣言分类器的性能,其中将鉴别器用作分类器,并且相应的生成器通过产生冲突噪声来改善鉴别器。此外马等人构建了树状结构的递归神经网络 (RvNN),以从传播结构和文本内容中捕获隐藏的表示 (马,Gao和Wong 2018)。但是,这些方法效率低下,无法学习支撑结构的特征,并且它们也忽略了谣言散布的全局结构特征。
GCN 介绍:
与上述深度学习模型相比,GCN能够更好地从图或树中捕获全局结构特征。受CNN在计算机视觉领域的成功启发,GCN在各种图形数据的任务中表现出最先进的性能(Battaglia等人,2016;Defferrard, Bresson, and Vandergheynst,2016;Hamilton, Ying, and Leskovec, 2017)。Scarselli等人(Scarselli et al. 2008)首先介绍了GCN作为无向图或有向图的特殊传递模型。后来,Bruna等人 (Bruna et al. 2014) 基于谱图理论对无向图的图卷积方法进行了理论分析。随后,Defferrard等人 (Defferrard,Bresson和Vandergheynst 2016) 开发了一种方法,命名为切比雪夫光谱CNN (ChebNet),并使用切比雪夫多项式作为滤波器。在这项工作之后,Kipf等人 (Kipf和Welling 2017) 提出了ChebNet (1stChebNet) 的一阶近似,其中每个节点的信息从节点本身及其附近的节点聚合。我们的谣言检测模型受到GCN的启发。
3 初步说明
我们介绍了一些基本概念,这些概念对于我们的方法是必需的。首先,本文使用的符号如下。
表示法
设为谣言检测数据集,其中
为第i个事件,m为事件数。
,其中
指
中的帖子数,
是源帖子,每个
代表第j个相关响应帖子,
指传播结构。
具体来说,被定义为一个图
,其中
是根节点(Wu,Yang 和 Zhu 2015; Ma,Gao 和 Wong 2017) ,其中
,
表示从响应帖子到转发帖子或响应帖子的边集,如图1(b)所示。例如,如果
对
有响应,那么将有一个有向边
,即
。如果
对
有响应,那么将会有一个有向边
,即
。表示
为一个邻接矩阵
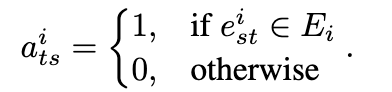
将表示为从
中的帖子中提取的特征矩阵,其中
表示
的特征向量,每个其他行特征
代表
的特征向量;
此外,每个事件 都与一个基本事实标签
(即,假谣言或真谣言)相关联。在某些情况下,
是四个更细粒度的类之一{ N,F,T,U }(即,非谣言,虚假谣言,真实谣言和未经证实的谣言)(Ma,Gao,and Wong 2017; Zubiaga et al。2018)。给定数据集,谣言检测的目标是学习分类器:
![]()
其中C和Y分别是事件和标签的集合,以基于文本内容、用户信息和由该事件的相关帖子构建的传播结构来预测事件的标签。
图卷积网络
最近,人们越来越关注将卷积推广到图域。在所有现有作品中,GCN是最有效的卷积模型之一,其卷积操作被认为是一种通用的 “消息传递” 体系结构,如下所示:
![]()
其中是由 k 图常规层(GCL)计算的隐特征矩阵,M 是消息传播函数,它依赖于邻接矩阵 A、隐特征矩阵
和可训练参数
。
GCN的消息传播函数M有很多种 (Bruna等人2014; Defferrard、Bresson和Vandergheynst 2016)。其中,在ChebNet (1stChebNet) (Kipf和Welling 2017) 的一阶近似中定义的消息传播函数如下:
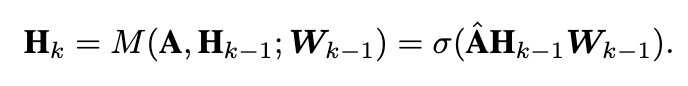
在上述方程 是正规化的邻接矩阵,其中
(即加上自连接) ,
表示第 i 个节点的度,
,σ (·)是一个激活函数,例如,reLU 函数。
DropEdge
DropEdge是一种减少基于GCN的模型的过度拟合的新方法 (Rong等人2019)。在每个训练时期,它都会从输入图形中随机删除边缘,以一定的速率生成不同的变形副本。结果,该方法增加了输入数据的随机性和多样性,就像随机旋转或拍打图像一样。形式上,假设图A中边的总数为,下降率为p,则DropEdge,A ′ 后的邻接矩阵计算如下:
![]()
其中 是从原始边集中随机抽样的
边构造的矩阵。
Bi-GCN谣言检测模型
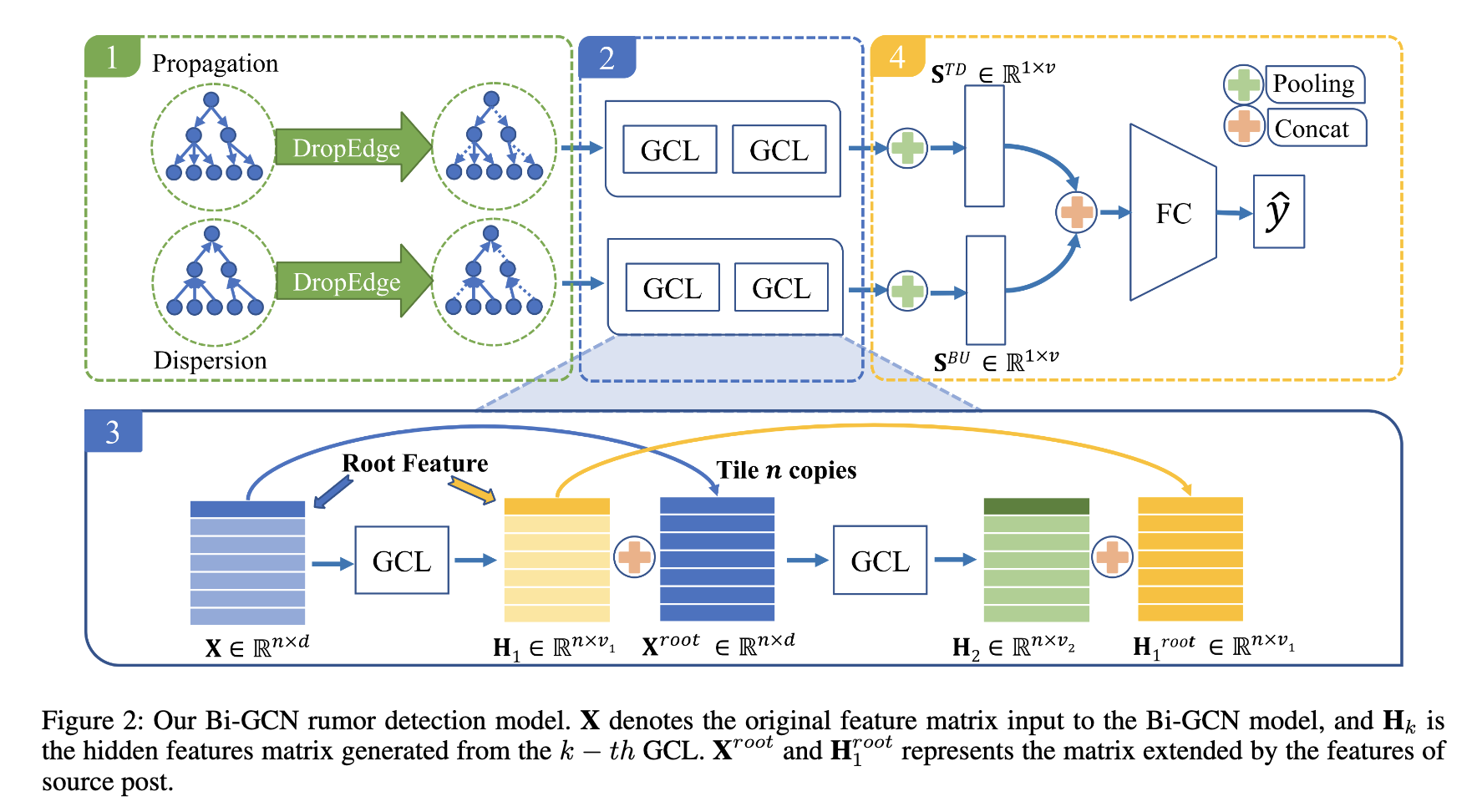
在本节中,我们提出了一种基于谣言传播和谣言散布的有效的基于GCN的谣言检测方法,称为双向图卷机网络 (Bi-GCN)。Bi-gcn的核心思想是从谣言传播和谣言散布中学习合适的高级表示。在我们的bi-gcn模型中,采用两层1stChebNet作为基本的GCN组件。如图2所示,我们分4个步骤详细阐述了使用Bi-GCN的谣言检测过程。
我们首先讨论如何将bi-gcn模型应用于一个事件,即第i个事件的。其他事件的计算方式相同。为了更好地展示我们的方法,我们在以下内容中省略了下标i。
1 构造传播图和散布图
基于转发和响应关系,我们构造了谣言事件的传播结构〈V,E〉。然后,假设
和X分别是其对应的基于谣言传播树的特征矩阵和
的特征矩阵。
如图1(b) 所示,A仅包含从上节点到下节点的边。在每个训练时期,通过公式(3) 删除p个百分比的边形成A',避免过度拟合问题 (Rong等2019)。基于A′ 和X,我们可以建立我们的Bi-GCN模型。我们的Bi-GCN由两个组件组成: 自上而下的图卷积网络 (td-gcn) 和自下而上的图卷积网络 (BU- GCN)。
两个分量的邻接矩阵是不同的。对于td-gcn,邻接矩阵表示为在处。同时,对于BU-GCN,邻接矩阵为
。Td-gcn和BU-GCN采用相同的特征矩阵X。
2 计算高级节点表示
在 DropEdge 操作后,分别利用 TD-GCN 和 BU-GCN 获得了自顶向下和自底向上的传播特征。
通过在两层上用和 X 代替 Eq. (2) ,我们写出 TD-GCN 的方程如下:
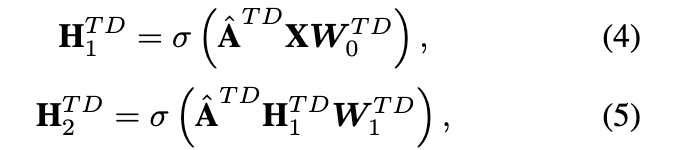
其中 ,
表示两层 TD-GCN 的隐层特征。
为了避免过度拟合,在 GCN 层(GCLs)上应用了dropout(Srivastava et al. 2014)。类似于等式。,我们以与 Eq(4)和(5) 相同的方式计算 BU-GCN 的自底向上隐藏特征 和
。
3 根特征增强
众所周知,谣言事件的来源帖子总是具有丰富的信息,可以产生广泛的影响。有必要更好地利用源帖子中的信息,并从节点与源帖子之间的关系中学习更准确的节点表示。
因此,除了td-gcn和BU-GCN的隐藏特征外,我们还提出了根特征增强的操作,以提高谣言检测的性能,如图2所示。具体来说,对于第k个GCL的td-gcn,我们将每个节点的隐藏特征向量与第 (k − 1) 个GCL的根节点的隐藏特征向量连接起来,构造一个新的特征矩阵为

。因此,我们通过替换方程(5)中的
来表达具有根特征增强的td-gcn。用
,然后得到
如下:
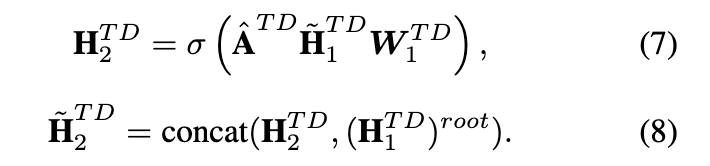
同样地,BU-GCN 的根特征增强的隐特征度量和
也是以与 Eq (7)及等式(8). 相同的方式获得的。
4 谣言分类的传播和散布表示
传播和散布的表示分别是 TD-GCN 和 BU-GCN 节点表示的聚合。在这里,我们使用均值池化操作符来聚合来自这两组节点表示的信息。它的公式是

然后,将传播的表示和散布的表示连接起来,将信息合并为:
![]()
最后,通过几个完整连接层和一个 softmax 层计算事件的标签:
![]()
我们通过最小化预测的交叉熵和ground truth分布 Y,在所有事件中训练 Bi-GCN 模型中的所有参数,L2正则化器应用于所有模型参数的损失函数。
4 实验
在这一部分,我们首先评估了我们提出的双 GCN 方法与几个基线模型相比的经验性能。然后,我们研究了该方法的各个变种的效果。最后,我们还检验了该方法和比较方法对早期谣言的检测能力。
设置和数据集
数据集:我们在三个真实世界的数据集上评估我们提出的方法: Weibo (Ma et al。2016) ,Twitter15(Ma,Gao 和 Wong 2017)和 Twitter16(Ma,Gao 和 Wong 2017)。
新浪微博和 Twitter 分别是中国和美国最受欢迎的社交媒体网站。
在所有三个数据集中,节点指用户,边表示转发或响应关系,特征是在 Bi-GCN 谣言检测模型部分中提到的 TF-IDF 值的前5000个单词提取。
新浪微博的数据包含两个二元标签: False Rumor (F)和 True Rumor (T) ,而 Twitter15和 Twitter16的数据包含四个标签: 非谣言(N) ,False Rumor (F) ,True Rumor (T)和未经证实的谣言(U)。
根据新浪社区管理中心报告的各种错误信息,微博上每个事件的标签都有注释(Ma et al。2016)。在 Twitter15和 Twitter16中,每个事件的标签都是根据揭秘网站(例如 snopes. com,Emergent.info 等)上文章的真实性标签来注释的(Ma,Gao,And Wong 2017)。这三个数据集的统计信息如表1所示。

实验设置:我们将所提出的方法与一些最先进的基线进行了比较,包括
DTC (Castillo,Mendoza和Poblete 2011): 一种利用基于各种手工特征的决策树分类器来获得信息可信度的谣言检测方法;
svm-rbf (Yang等人2012): 基于RBF内核的SVM模型,使用基于帖子的全部统计信息的手工制作的特;
svm-ts (马等人2015): 利用手工制作的特征来构建时间序列模型的线性SVM分类器;
Svm-tk (马,Gao和Wong 2017): 基于谣言的传播结构的具有传播树内核的SVM分类器;
RvNN (马,Gao和Wong 2018): 一种基于树结构递归神经网络的谣言检测方法,其GRU单元通过传播结构学习谣言表;
PPC RNN CNN (刘和吴2018): 结合RNN和CNN的谣言检测模型,通过谣言传播路径中的用户特征来学习谣言表;
Bi-GCN: 我们的基于GCN的谣言检测模型利用了双向传播结构。
我们使用 scikit-learn实现了 DTC 和 SVM 模型; 使用 Keras实现了 PPC RNN + CNN; 使用了 RvNN; 使用了 Pytorch实现了我们的方法。为了进行公平的比较,我们将数据集分成五部分,进行5次交叉验证,以获得可靠的结果。对于微博数据集,我们评估其准确性(Acc)超过两类和精确(Prec.),召回,F1测量(F1)在每个类别。对于这两个 Twitter 数据集,我们评估了 Acc。在四个类别和 F1的每一个类别。使用随机梯度下降更新Bi-GCN的参数,并通过Adam算法 (Kingma和Ba 2014) 优化模型。每个节点的hid- den特征向量的维度为64。DropEdge的下降速度是0.2的,而学习率是0.5的。训练过程在200个epoch上迭代,并且当验证损失停止减少10个epoch时,应用早期停止 (Yao、Rosasco和Caponnetto 2007)。请注意,我们没有在微博数据集上使用svm-tk,因为它在大型数据集上具有指数复杂度。
整体表现
表2和表3分别显示了所提出方法和所有比较方法在微博和Twitter数据集上的性能。

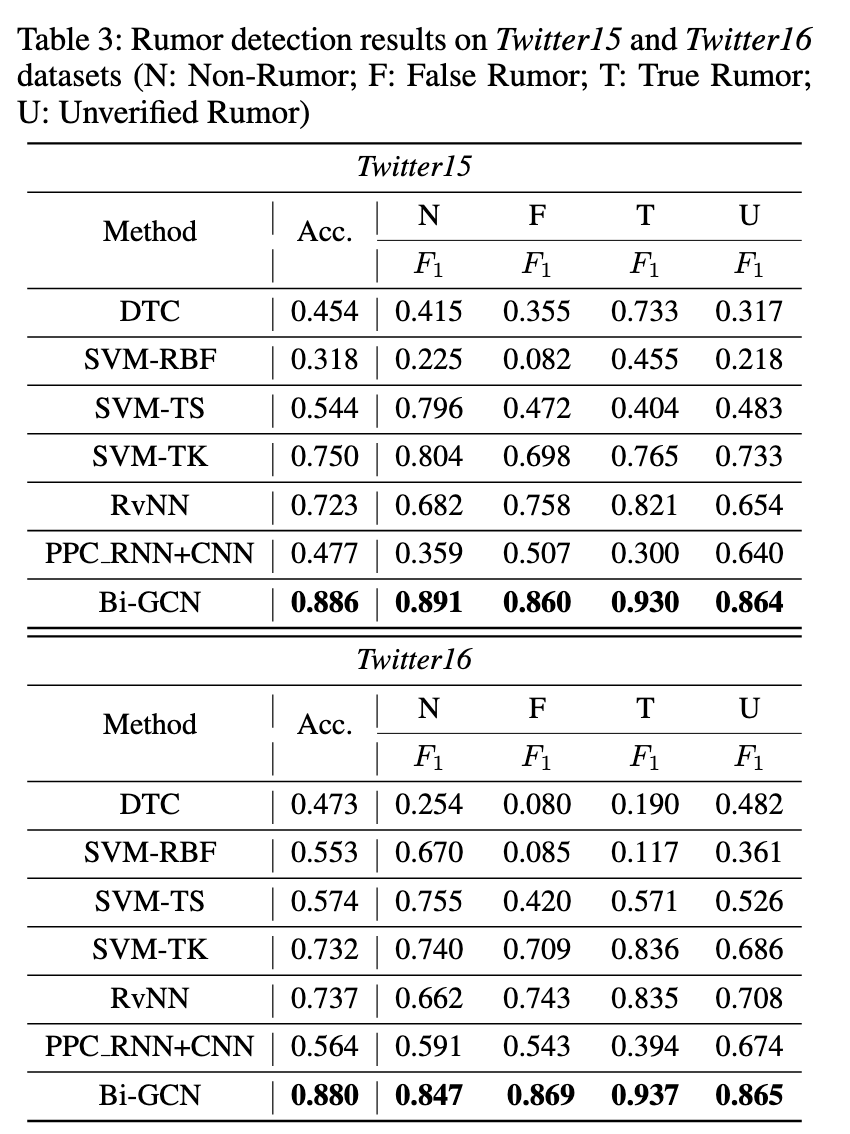
首先,在基线算法中,我们观察到深度学习方法的性能明显优于使用手工特征的方法。这并不奇怪,因为深度学习方法能够学习谣言的高级陈述,以捕获有效的特征。这表明了深入学习谣言检测的重要性和必要性。
其次,所提出的方法在所有性能指标方面均优于PPC RNN CNN方法,这表明将分散结构结合到谣言检测中是有效的。由于RNN和CNN无法处理具有图结构的数据,因此PPC RNN CNN忽略了谣言散布的重要结构特征。这使其无法获得谣言的高效高级表示,从而导致谣言检测性能较差。
最后,Bi-GCN显著优于RvNN方法。由于RvNN仅使用所有叶节点的隐藏特征向量,因此它会受到最新帖子信息的严重影响。但是,最新的帖子总是缺乏诸如评论之类的信息,而只是遵循以前的帖子。
与RvNN不同的是,根部特征的增强使得所提出的方法能够更加关注源帖子的信息,这对改善我们的模型有更大帮助。
消融研究
为了分析Bi-GCN的每个变体的效果,我们将所提出的方法与TD-GCN,BU-GCN,UD- GCN及其变体进行了比较,而没有根特征增强。实证结果总结在图3中。
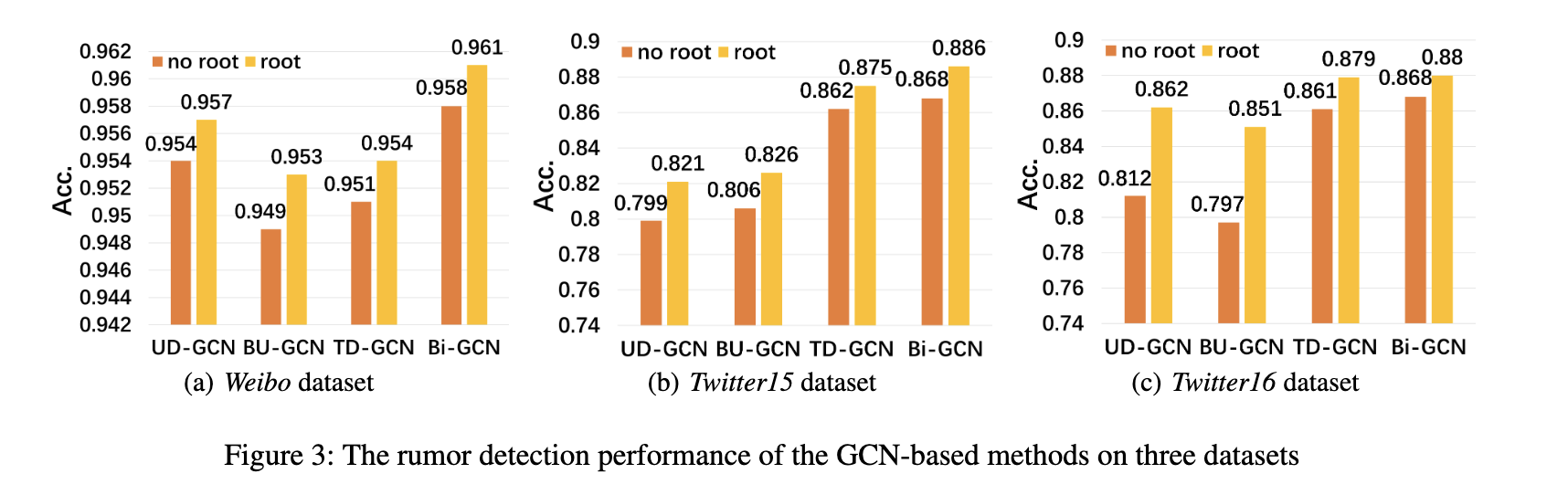
Ud-gcn,td-gcn和BU-GCN代表我们基于GCN的谣言检测模型分别利用无定向,自上而下和自下而上的结构。同时,“根” 是指在网络中连接根特征的基于GCN的模型,而 “无根” 表示在网络中不连接根特征的基于GCN的模型。
从图3中得出一些结论。首先,Bi- GCN,td-gcn,BU-GCN和UD-GCN分别在没有根特征增强的情况下优于其变体。这表明源帖子在谣言检测中起着重要作用。
其次,TD-GCN和BU-GCN不能总是比UD-GCN取得更好的结果,但是Bi-GCN总是优于UD-GCN、TD-GCN和BU-GCN。这意味着同时考虑祖先节点的自顶向下表示和子节点的自底向上表示的重要性。最后,即使是图3中最差的结果,也比表2和表3中其他基线方法的结果好很多,这再次验证了图卷积对谣言检测的有效性。
早期谣言检测
早期检测旨在在传播的早期检测谣言,这是评估方法质量的另一个重要指标。为了构建早期检测任务,我们设置了一系列检测截止日期,并且仅使用在截止日期之前发布的帖子来评估所提出方法和基准方法的准确性。由于PPC RNN CNN方法很难处理变分长度的数据,因此我们无法在该任务的每个截止日期获得PPC RNN CNN的准确结果,因此在本实验中不进行比较。
图4显示了我们的bi-gcn方法与RvNN,svm-ts,svm-rbf和DTC在微博和Twitter数据集的各个截止日期的性能。
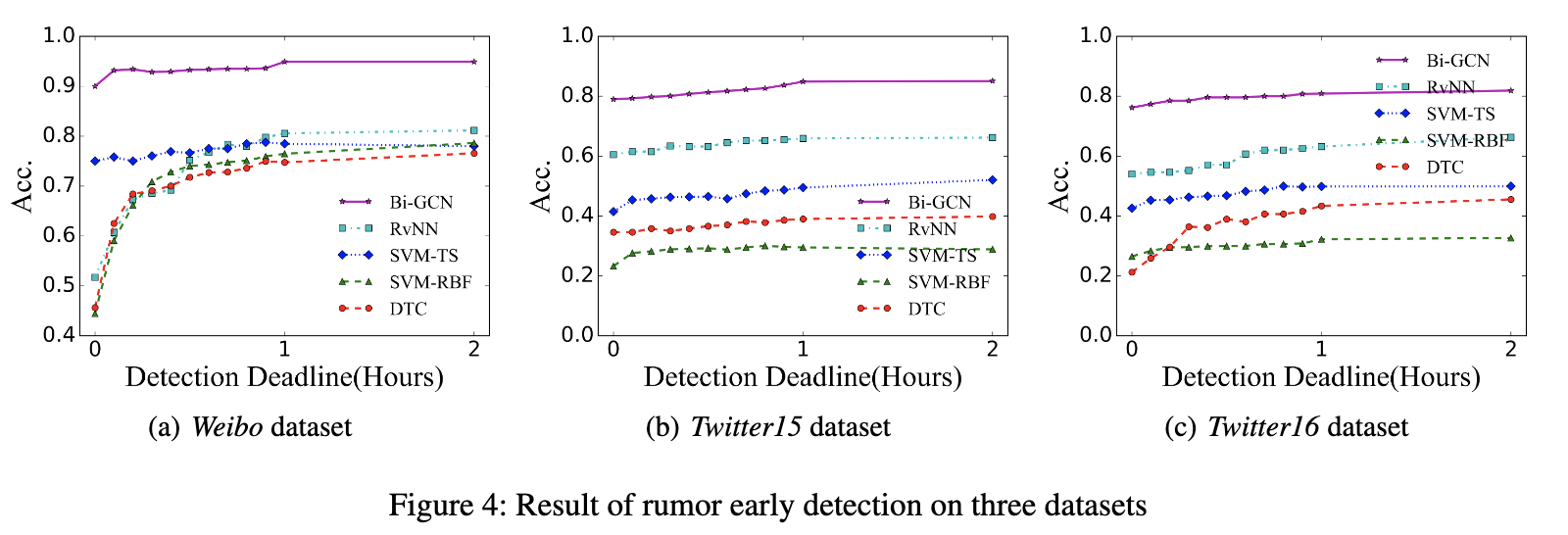
从图中可以看出,所提出的Bi-GCN方法在源初始广播后的很早阶段就达到了相对较高的精度。此外,bi-gcn的性能在每个截止日期都明显优于其他模型,这表明结构特征不仅有利于长期谣言检测,而且有助于谣言的早期检测。
5 结论
在本文中,我们提出了一种基于GCN的社交媒体谣言传播模型,称为Bi-GCN。其固有的GCN模型使所提出的方法具有处理图/树结构和学习更高级代表的能力,更有利于谣言检测。此外,我们还通过在GCN的每个GCL之后合并源帖子的特征来提高模型的有效性。同时,我们构造了Bi-GCN的几种变体来对传播模式进行建模,即UD-GCN,TD-GCN和BU-GCN。在三个真实世界数据集上的实验结果表明,基于GCN的方法在准确性和效率上都超出了执行最先进的基线的幅度。特别是,Bi- GCN模型通过考虑谣言沿着从上到下传播模式的关系链传播的因果特征和通过自下而上收集在社区内的谣言分散的结构特征,实现了最佳性能。
这篇关于谣言检测论文阅读 - Rumor Detection on Social Media with Bi-Directional Graph Convolutional Networks的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!