本文主要是介绍01 Incentive Mechanism for Reliable Federated Learning: A Joint Optimization Approach to Combining R,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
01 Incentive Mechanism for Reliable Federated Learning: A Joint Optimization Approach to Combining Reputation and Contract Theory
概括
1基于声誉衡量可靠性,选择矿工。
2区块链管理声誉。
3奖惩。
在本文中,我们首先引入声誉作为衡量移动设备可靠性和可信度的指标。然后,我们使用多权重主观逻辑模型设计了一个基于声誉的可靠联合学习工作者选择方案。
(1)使用多权重主观逻辑模型进行声誉计算
(2)通过联盟区块链技术以分散的方式进行安全声誉存储。
步骤
1.发任务需求(数据类型大小和准确性、时间范围和CPU周期),满足要求候选
2.计算候选者信誉值
3.选矿工
4.执行联合学习,评估(攻击检测方案)本地模型更新的质量,奖惩【RONI: 是一种典型的中毒攻击检测方案,它通过比较本地模型更新与否对任务发布者预定义数据库的影响来验证本地模型更新。】
5.声誉更新到区块链
使用多权重主观逻辑的声誉计算 细节:
【第一步概括】A. 主观逻辑的信誉意见表示【均为任务发布者 i 对 矿工 j 的 声誉评价】


1) 为了抑制消极交互事件: 定义 消极的权重 > 积极权重 && 消极权重 + 积极权重 = 1

2) 近期交互权重 > 往期交互权重 && 斟酌淡出参数

【第二步概括】B. 加权推荐人的声誉意见【通过 相关的矿工 j , 任务发布者 i ,对 任务发布者 x 计算声誉意见】
间接评价的权重【任务发布者 i 对 任务发布者 x 的评价】
预定义的系数
👇
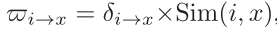
任务发布者 i 和 x 相似度计算公式:
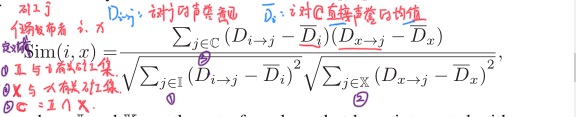
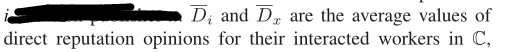
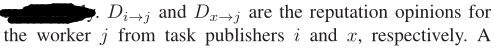
所有来自推荐人的间接声誉,整合到整体声誉中
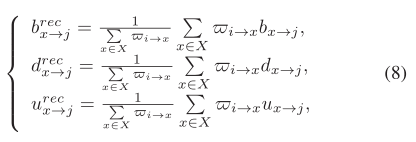
【第三步概括】将直接声誉意见与推荐声誉意见相结合
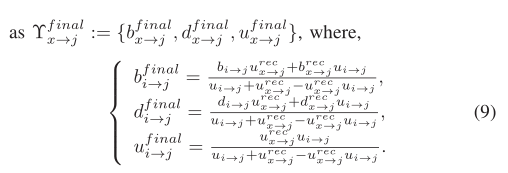
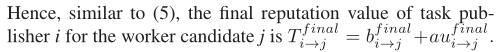
奖励机制
存在问题:
- 由于缺乏先验知识,任务发布者不知道哪些移动设备希望加入模型培训。
- 任务发布者不知道工作人员的准确信誉值和本地数据质量。
- 任务发布者不知道模型培训工人提供的可用计算资源量和数据大小。
因此,任务发布者在向移动设备提供激励时可能会承受太多的成本。为了减少信息不对称的影响,任务发布者必须设计有效的激励机制。
A. 计算模型
一次局部迭代的工人CPU能耗如下:
B. 通信模型


C. 奖励函数 to task publisher
公式繁多,不想学了。
参考文献总结: 【9,11】工作将声誉作为衡量实体在某些活动中的可靠性或可信度的标准 矿工的选择 随机【5】 声誉【9】 【5】H. Kimet al., “Blockchained On-Device Federated Learning,” in IEEE
Communications Letters, in press, 2019. DOI: 10.1109/LCOM-
M.2019.2921755 【9】J. Kang, Z. Xiong, D. Niyatoet al., “Toward secure
blockchain-enabled internet of vehicles: Optimizing consensus
management using reputation and contract theory,”IEEE Transactions on
V ehicular Technology, vol. 68, pp. 2906–2920, March 2019.
这篇关于01 Incentive Mechanism for Reliable Federated Learning: A Joint Optimization Approach to Combining R的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







