本文主要是介绍回归预测 | MATLAB实现IBES-ELM基于改进的秃鹰搜索优化算法优化极限学习机的数据回归预测(多指标,多图),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
回归预测 | MATLAB实现IBES-ELM 基于改进的秃鹰搜索优化算法优化极限学习机的数据回归预测(多指标,多图)
目录
- 回归预测 | MATLAB实现IBES-ELM 基于改进的秃鹰搜索优化算法优化极限学习机的数据回归预测(多指标,多图)
- 效果一览
- 基本介绍
- 程序设计
- 参考资料
效果一览
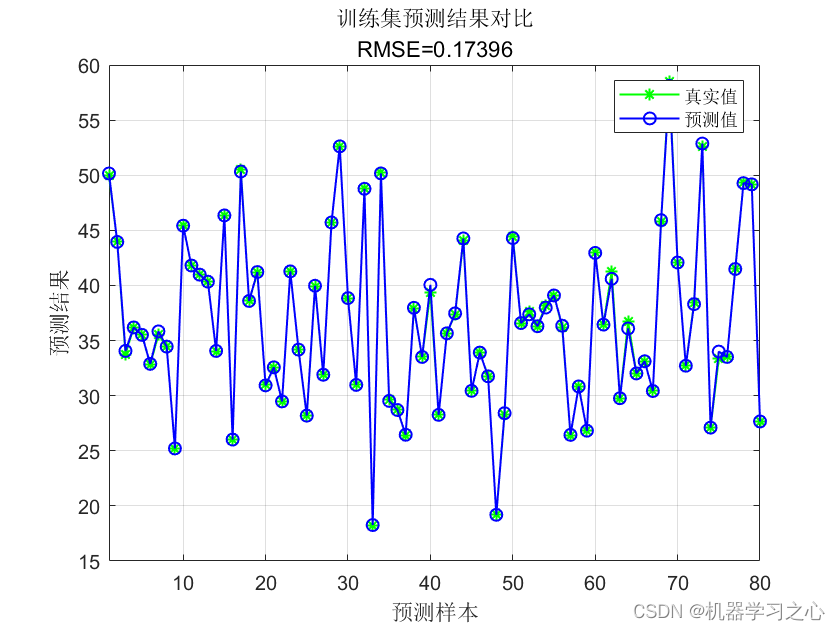
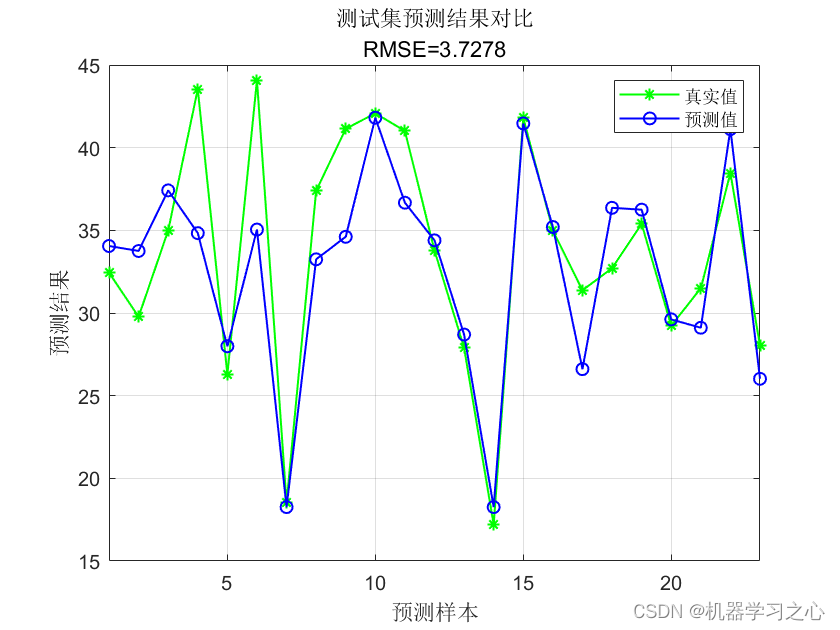

基本介绍
1.MATLAB实现IBES-ELM基于改进的秃鹰搜索优化算法优化极限学习机的数据回归预测(多指标,多图)。
2.直接替换Excel数据即可用,注释清晰,适合新手小白
3.附赠示例数据,输入格式如图2所示,直接运行main文件一键出图。
程序设计
- 完整源码和数据获取方式:私信回复MATLAB实现IBES-ELM 基于改进的秃鹰搜索优化算法优化极限学习机的数据回归预测(多指标,多图)。
%% 清空环境变量
warning off % 关闭报警信息
close all % 关闭开启的图窗
clear % 清空变量
clc % 清空命令行%% 导入数据
res = xlsread('data.xlsx');%% 划分训练集和测试集
temp = randperm(103);P_train = res(temp(1: 80), 1: 7)';
T_train = res(temp(1: 80), 8)';
M = size(P_train, 2);P_test = res(temp(81: end), 1: 7)';
T_test = res(temp(81: end), 8)';
N = size(P_test, 2);%% 数据归一化
[p_train, ps_input] = mapminmax(P_train, 0, 1);
p_test = mapminmax('apply', P_test, ps_input);[t_train, ps_output] = mapminmax(T_train, 0, 1);
t_test = mapminmax('apply', T_test, ps_output);%% 仿真测试
t_sim1 = sim(net, p_train);
t_sim2 = sim(net, p_test);%% 数据反归一化
T_sim1 = mapminmax('reverse', t_sim1, ps_output);
T_sim2 = mapminmax('reverse', t_sim2, ps_output);%% 均方根误差
error1 = sqrt(sum((T_sim1 - T_train).^2) ./ M);
error2 = sqrt(sum((T_sim2 - T_test ).^2) ./ N);%% 相关指标计算
% 决定系数 R2
R1 = 1 - norm(T_train - T_sim1)^2 / norm(T_train - mean(T_train))^2;
R2 = 1 - norm(T_test - T_sim2)^2 / norm(T_test - mean(T_test ))^2;disp(['训练集数据的R2为:', num2str(R1)])
disp(['测试集数据的R2为:', num2str(R2)])% 平均绝对误差 MAE
mae1 = sum(abs(T_sim1 - T_train)) ./ M ;
mae2 = sum(abs(T_sim2 - T_test )) ./ N ;disp(['训练集数据的MAE为:', num2str(mae1)])
disp(['测试集数据的MAE为:', num2str(mae2)])% 平均相对误差 MBE
mbe1 = sum(T_sim1 - T_train) ./ M ;
mbe2 = sum(T_sim2 - T_test ) ./ N ;disp(['训练集数据的MBE为:', num2str(mbe1)])
disp(['测试集数据的MBE为:', num2str(mbe2)])
参考资料
[1] https://blog.csdn.net/kjm13182345320/article/details/129215161
[2] https://blog.csdn.net/kjm13182345320/article/details/128105718
这篇关于回归预测 | MATLAB实现IBES-ELM基于改进的秃鹰搜索优化算法优化极限学习机的数据回归预测(多指标,多图)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







