本文主要是介绍NeRF:Representing Scenes as Neural Radiance Fields for viem Synthesis(用于视图合成的神经辐射场的场景表示),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
NeRF:Representing Scenes as Neural Radiance Fields for viem Synthesis(用于视图合成的神经辐射场的场景表示)|2020年

Fig. 1:通过场景的一些图片作为输入,我们提出一种优化连续的 5D 神经辐射场表示的方法
摘要
- 我们提出一种方法,使用较少的视图(view)作为输入,对一个连续、隐含的体积场景函数(volumetric scene function)进行优化,从而实现了关于复杂场景的新视图合成的最先进的结果。
- 我们的算法用全连接深度网络来表示场景,其输入是 5D 坐标:空间位置 (x,y,z) 和视角方向(viewing direction) (θ,ϕ);其输出是体积密度(volume density)和该空间位置上发射出来的辐射亮度(radiance,与视角相关)。
- 通过沿着相机光线(camera rays)获取 5D 坐标,使用经典的立体渲染(volume rendering)技术,我们将输出的颜色和密度投影到图像上,从而实现视图合成。
- 由于立体渲染是可导的,神经网络的优化,只需要提供一系列确定相机位姿的图像。
1 介绍
-
我们的工作,用新的方法解决了在**视图合成(view synthesis)**中长期以来的问题。
- 我们直接优化一个连续的 5D 场景表示(scene representation)的参数(网络权重),根据捕获到图像,最小化渲染误差。
- 我们把静态场景表示为连续的 5D 函数(指输入是 5D ),输出在各个空间点 (x,y,z)(x,y,z) 和各个方向 (θ,ϕ)(θ,ϕ) 发射出来的辐射亮度和密度(就像可导的透明度,控制穿过 (x,y,z)(x,y,z) 的射线,可以累加多少辐射亮度)。
- 我们的方法是优化一个深度全连接的神经网络,没有用到卷积层,全连接神经网络又称多层感知器(MLP);我们用这个 MLP 来表示这样的函数:根据一个 5D 坐标 (x,y,z,θ,ϕ)(x,y,z,θ,ϕ),回归输出一个体积密度和视角相关的 RGB 颜色。
-
整个流水线如下图所示:
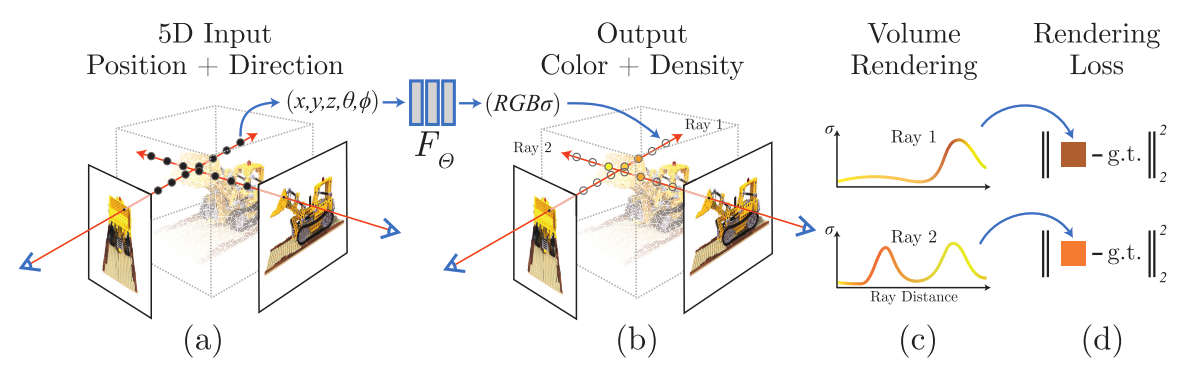
Fig. 2: 神经辐射场场景表示和可导的渲染流程的概述。我们的图像合成,通过(图 a)沿着相机光线采样出 5D 坐标(位置和视角方向);(图 b)把位置喂给 MLP,生成颜色和体积密度;(图 c)使用立体渲染技术,利用这些值得到一张图像。由于这个渲染函数是可导的,因此我们可以最小化合成图像和真实观察图像的残差,进行场景表示的优化。
- 为了根据某一视角(viewpoint),渲染出这个神经辐射场(Neural Radiance Field, NeRF),我们:
1.使相机光线穿过场景,生成一组 3D 采样点;
2.让这些 3D 点和对应的 3D 视角方向作为神经网络的输入,生成一组颜色和密度;
3.使用经典的立体渲染技术,累加这些颜色和密度,得到 2D 图像。
- 由于以上过程是可导的,我们可以使用梯度下降来优化模型,最小化观测图像与模型回归计算的图像之间的误差。
- 这可以鼓励神经网络学习的场景模型具有一致性(coherent),即在包含场景内容的位置,可以得到较大的体积密度和准确的颜色。
- 我们发现对于复杂的场景,用简单的方法优化 NeRF 效果不理想:
- 很难得到高分辨率的收敛结果;
- 也不能高效利用相机光线所需的采样点。
- 于是,我们这样解决以上问题:
- 用一个位置编码(positional encoding)对输入 5D 坐标进行变换,使得 MLP 可以表示高频函数;
- 提出层次化的采样流程(hierarchical sampling procedure),减少所需的采样点。
- 我们的方法保留了体积表示的优点:
- 可以表示复杂的几何和外观;
- 可以通过投影图像进行梯度下降的优化。
- 重要的是,我们的方法克服了体积表示的一个关键问题:在表示高分辨率的复杂场景时,离散的体素网格的存储空间成本非常高。
- 总结下来,本文的贡献如下:
- 包含复杂几何和材质的连续场景的表示方法:使用参数化为 MLP 的 5D 神经辐射场;
这篇关于NeRF:Representing Scenes as Neural Radiance Fields for viem Synthesis(用于视图合成的神经辐射场的场景表示)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





