scenes专题

论文精读-Supervised Raw Video Denoising with a Benchmark Dataset on Dynamic Scenes
论文精读-Supervised Raw Video Denoising with a Benchmark Dataset on Dynamic Scenes 优势 1、构建了一个用于监督原始视频去噪的基准数据集。为了多次捕捉瞬间,我们手动为对象s创建运动。在高ISO模式下捕获每一时刻的噪声帧,并通过对多个噪声帧进行平均得到相应的干净帧。 2、有效的原始视频去噪网络(RViDeNet),通过探
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis 精读
1 传统视图合成和NeRF(Neural Radiance Fields) 1.1 联系 传统视图合成和NeRF的共同目标都是从已有的视角图像中生成新的视角图像。两者都利用已有的多视角图像数据来预测或合成从未见过的视角。 1.2 区别 1.2.1 几何表示方式 传统视图合成:通常使用显式几何模型(如深度图、网格、点云)或其他图像处理方法(如基于图像拼接或光流的方法)来生成新的视图。这些
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis 翻译
NeRF:将场景表示为用于视图合成的神经辐射场 引言。我们提出了一种方法,该方法通过使用稀疏的输入视图集优化底层连续体场景函数来实现用于合成复杂场景的新视图的最新结果。我们的算法使用全连通(非卷积)深度网络来表示场景,其输入是单个连续的5D坐标(空间位置(x,y,z)和观察方向(θ,φ)),其输出是该空间位置处的体积密度和与观察相关的发射辐射。我们通过查询沿着相机光线的5D坐标来合成视图,并使用

拥挤场景多人姿态估计论文梗概及代码CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark
姿态估计是视频动作分析识别的基础工作,我有一篇小综述讲了姿态估计相关技术路线的发展,可以点这个链接看。 本文是MVIG大佬们发表在CVPR2019上的一篇论文,上号交通大学,基于AlphaPose思路,进一步提升了拥挤情况下准度 代码:github点这,基于Pytorch,是实时多人姿态估计系统 论文:论文点这 论文第二版点这 Abstract 多人姿态估计是大量计算机视觉任务的基础,近年来也

【论文笔记】DiL-NeRF: Delving into Lidar for Neural Radiance Field on Street Scenes
原文链接:https://arxiv.org/abs/2405.00900 1. 引言 自动驾驶等应用领域需要逼真的仿真。传统的仿真流程需要手工创建3D资产并构成虚拟环境,但其人力和专业需求使其难以具有可放缩性。 NeRF有不错的仿真能力,但需要大范围覆盖的训练数据以学习潜在的几何、材料特性和光照。在自动驾驶场景中,数据覆盖很稀疏,且相机的轨迹共线。此外,路面纹理较少,进一步引入重建的模糊性

【读论文】Gaussian Grouping: Segment and Edit Anything in 3D Scenes
Gaussian Grouping: Segment and Edit Anything in 3D Scenes 文章目录 Gaussian Grouping: Segment and Edit Anything in 3D Scenes1. What2. Why3. How3.1 Anything Mask Input and Consistency3.2 3D Gaussian Re

How browsers work--Behind the scenes of modern web browsers (前端必读)
浏览器可以被认为是使用最广泛的软件,本文将介绍浏览器的工 作原理,我们将看到,从你在地址栏输入google.com到你看到google主页过程中都发生了什么。 将讨论的浏览器 今天,有五种主流浏览器——IE、Firefox、Safari、Chrome及Opera。 本文将基于一些开源浏览器的例子——Firefox、 Chrome及Safari,Safari是部分开源的。 根据W3
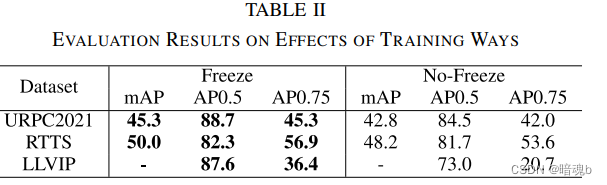
Image Enhancement Guided Object Detection in Visually Degraded Scenes
Abstract 目标检测准确率在视觉退化场景下降严重。一个普遍的解决方法就是对退化图像进行增强然后再执行目标检测。但是,这是一种次优的方案,而且未必对目标检测的准确率有提升,因为图像增强和目标检测两个任务的不同。为了解决这个问题,我们提出了一种图像增强引导目标检测的方法,以端到端的方式定义了一个检测网络和一个额外的增强分支。具体来说,增强分支和检测分支以并行的方式组织,并设计了一个特征引导模块

3DGS 其二:Street Gaussians for Modeling Dynamic Urban Scenes
3DGS 其二:Street Gaussians for Modeling Dynamic Urban Scenes 1. 背景介绍1.1 静态场景建模1.2 动态场景建模 2. 算法2.1 背景模型2.2 目标模型 3. 训练3.1 跟踪优化 4. 下游任务 Reference: Street Gaussians for Modeling Dynamic Urban Sce
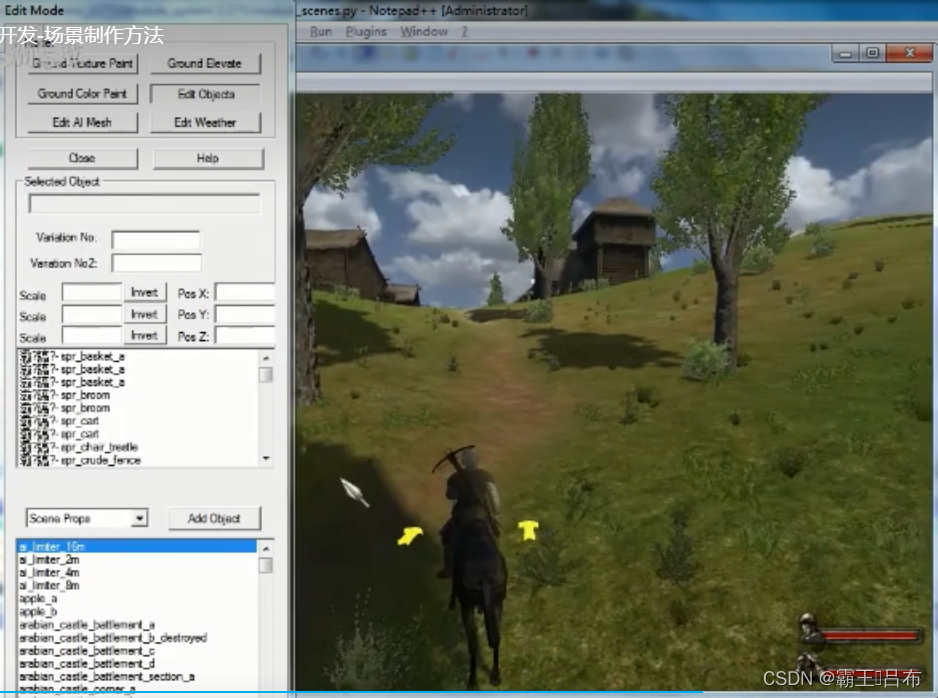
骑砍战团MOD开发(29)-module_scenes.py游戏场景
骑砍1战团mod开发-场景制作方法_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1Cw411N7G4/ 一.骑砍游戏场景 骑砍战团中进入城堡,乡村,战斗地图都被定义为场景,由module_scenes.py进行管理。 scene(游戏场景) = 天空盒(Skyboxes.py) + 地形(terrain code) + 场景

文献阅读笔记: Real-time Multiple Objects Tracking with Occlusion Handling in Dynamic Scenes ---by 香蕉麦乐迪
文献阅读笔记: Real-time Multiple Objects Tracking with Occlusion Handling in Dynamic Scenes ---by 香蕉麦乐迪 文章第一部分 摘要:强调了对于持续时间长,完全遮挡的物体,没有形态或者运动的先验知识也能比较好的处理。实测表明有良好的分割和跟踪效果,速度15-20fps,图像大小320*240 介绍: 文献【1

AssetBundle Manager Example Scenes
AssetBundle Manager & Example Scenes https://www.assetstore.unity3d.com/en/#!/content/45836 https://docs.unity3d.com/Manual/AssetBundlesIntro.html posted on 2016-12-28 21:16 jiahuafu 阅
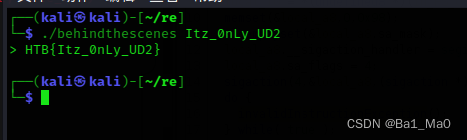
HackTheBox Behind The Scenes 逆向题目分析
题目地址: https://app.hackthebox.com/challenges/301 题目简介的意思是这个程序使用了加密来保护密码 开始 下载完程序后,我尝试使用ida来静态分析,可是ida无法打开程序 把程序拖入die分析,也没看到什么加密方式 然后我用strings查看一下程序内部的字符串 没能找到什么有用的字符串 然后我使用r2来动态分析程序,发现了

Faster Read: Deep High Dynamic Range Imaging of Dynamic Scenes
SIGGRAPH 2017, University of California, San Diego 论文名称: Deep High Dynamic Range Imaging of Dynamic Scenes keywords: High Dynamic Range Imaging, CNN(Convolutional Neural Network) 以下大意翻译是自己基于原文的理
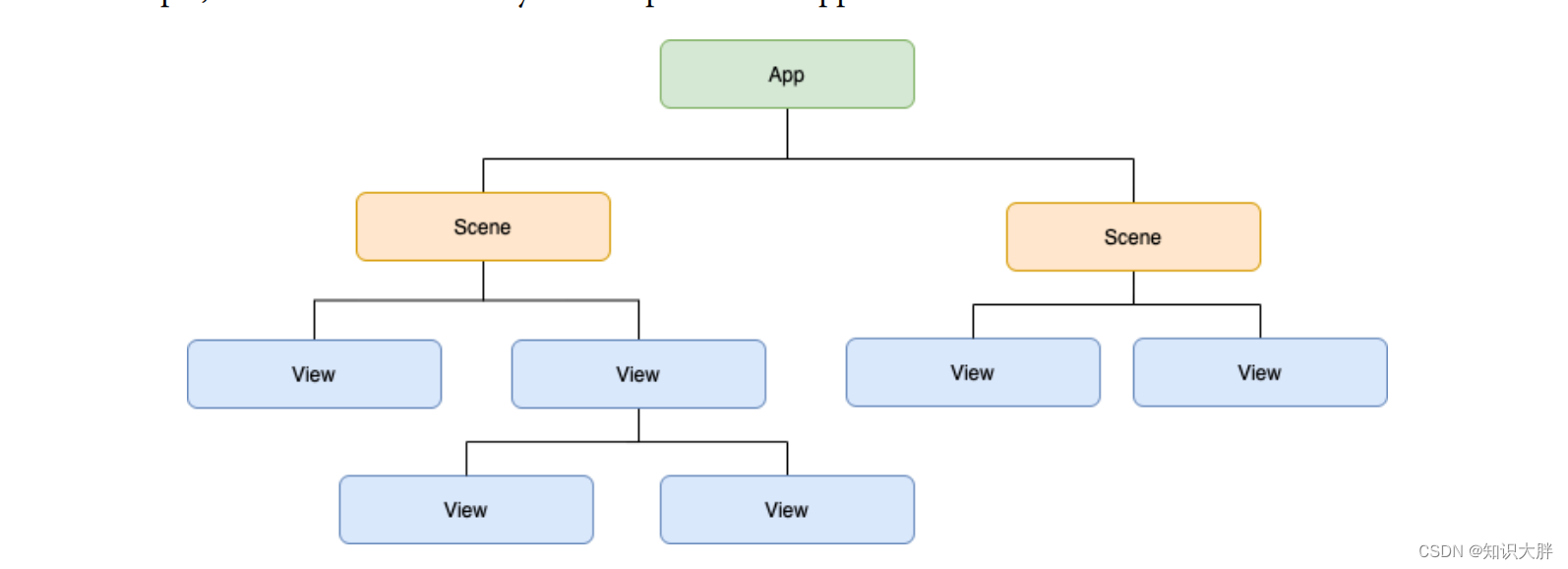
swiftui 中的app和 Scenes有什么,他们是什么关系
app和 Scenes有什么,他们是什么关系 SwiftUI 中的 app 和 Scenes 是两个相关的概念,它们都与应用程序的用户界面有关。 app 是指使用 SwiftUI 框架开发的应用程序,它包含了用户界面的所有内容和逻辑。在 SwiftUI 中,app 的界面通常由多个视图组成,每个视图都可以显示不同的内容和处理不同的用户交互。 Scenes 是指 app 中的独立的用户界面

6D Object Pose Estimation in Cluttered Scenes from RGB Images
文章目录 摘要贡献方法 摘要 本文提出一种特征融合网络,用于直接从RGB图像进行姿态估计,而无需任何深度信息。首先,我们引入一个由分割分支和回归分支组成的双流架构。分割分支处理空间嵌入特征并获得相应的图像裁剪。这些功能与融合网络中的图像裁剪进一步耦合。其次,我们在回归分支中使用高效的透视 n 点 (E-PnP) 算法来提取 3D 和 2D 关键点之间的鲁棒空间特征。最后,我们

GIRAFFE: Representing Scenes as Compositional Generative Neural Feature Fields(CVPR2021 Best paper)
目录 1. 简介1.1 参考资料1.2 课题研究背景(个人理解)1.3 文章发展脉络 2. NeRF2.1 解决的问题2.2 解决方法2.2.1 场景表示2.2.2 渲染成图像2.2.3 优化2.2.3.1 位置编码2.2.3.2 分层采样 3. GRAF3.1 简介3.2 方法3.2.1 NeRF相关公式3.2.2 GRAF框架3.2.2.1 ray sampling3.2.2.2 C
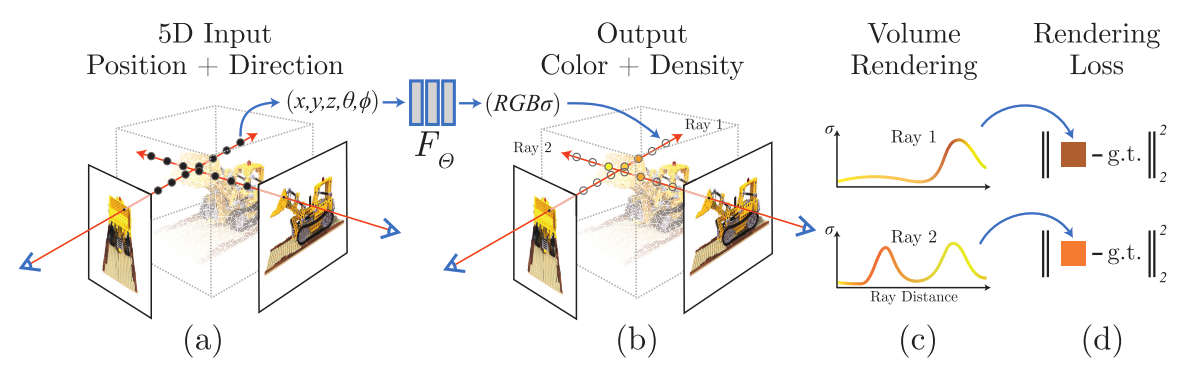
NeRF:Representing Scenes as Neural Radiance Fields for viem Synthesis(用于视图合成的神经辐射场的场景表示)
NeRF:Representing Scenes as Neural Radiance Fields for viem Synthesis(用于视图合成的神经辐射场的场景表示)|2020年 Fig. 1:通过场景的一些图片作为输入,我们提出一种优化连续的 5D 神经辐射场表示的方法 摘要 我们提出一种方法,使用较少的视图(view)作为输入,对一个连续、隐含的体积场景函数(volumet
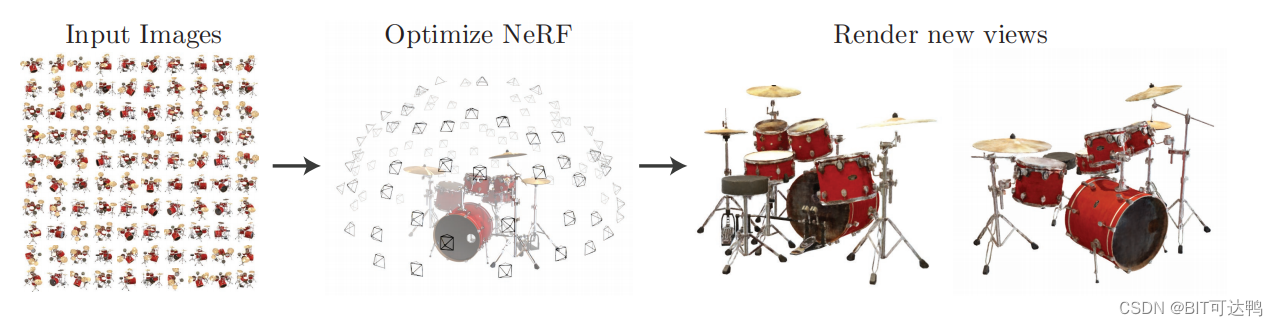
【ECCV 2020】NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
Representing Scenes as Neural Radiance Fields for View Synthesis 论文简介:论文介绍:Neural Radiance Field Scene Representation:Volume Rendering with Radiance Fields:Optimizing a Neural Radiance Field:Positi