本文主要是介绍6D Object Pose Estimation in Cluttered Scenes from RGB Images,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 摘要
- 贡献
- 方法
摘要
本文提出一种特征融合网络,用于直接从RGB图像进行姿态估计,而无需任何深度信息。首先,我们引入一个由分割分支和回归分支组成的双流架构。分割分支处理空间嵌入特征并获得相应的图像裁剪。这些功能与融合网络中的图像裁剪进一步耦合。其次,我们在回归分支中使用高效的透视 n 点 (E-PnP) 算法来提取 3D 和 2D 关键点之间的鲁棒空间特征。最后,我们采用端到端机制进行迭代细化,以提高估计性能。我们对YCB视频和具有挑战性的遮挡线MOD的两个公共数据集进行了实验。结果表明,我们的方法在速度和准确性方面都优于最先进的方法。
贡献
• 额外的定性和定量实验,以证明我们的姿态估计方法的优越性;
• 改进了损失函数和其他详细的描述,具有进一步的高级性能;
• 扩展应用:广告更换和墙面装饰建议
方法
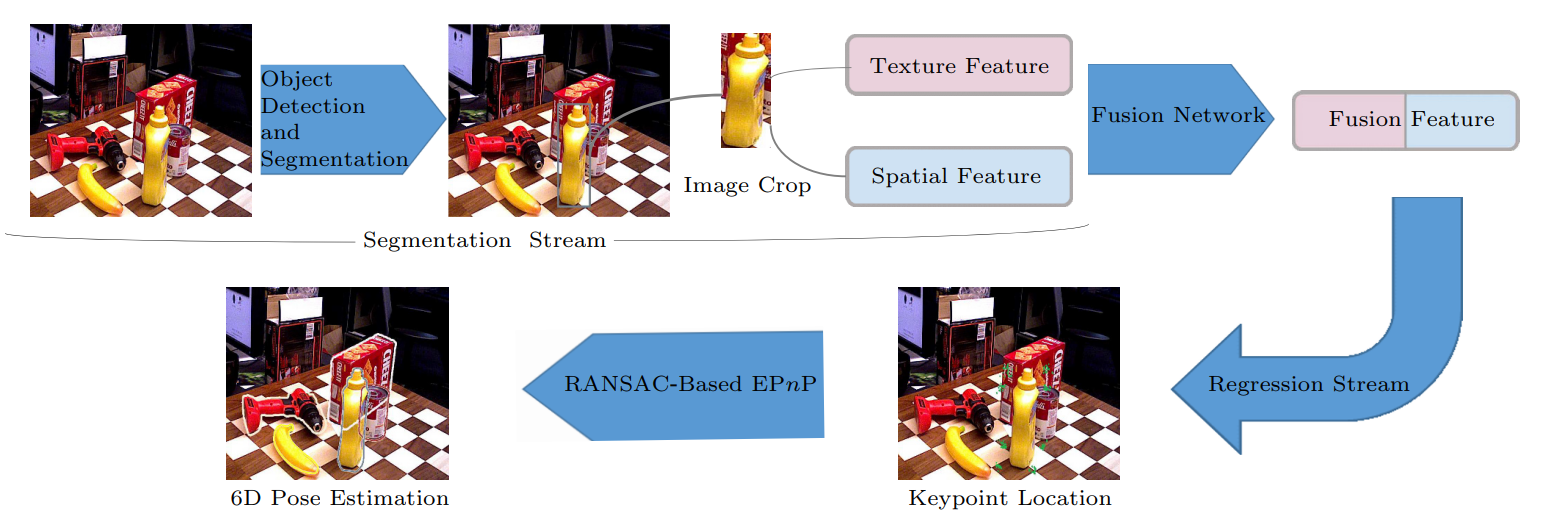
图 2 描述了我们方法的整体工作流程。
分割分支包括以下步骤:在每个输入帧中执行语义分割和裁剪。现有技术可以对已知物体实现出色的性能。然后,我们为每个分段的局部RGB patch提供分段标签,将每个裁剪图像的边界框和具有不同大小的整个原始图像与融合网络相结合,将分割后的空间特征与图像本身的纹理特征耦合。

我们使用经典的backbone,它由两个分割分支和回归分支组成。我们使用高效高效的YOLOv3和YOLOv4进行初始目标检测,并在分割中获得许多区域。然后,我们裁剪分割分支中原始输入图像上的每个检测到的区域。由于物体之间的遮挡,在分割的部分中可能会发生重叠。此外,我们用对象或背景信息标记n×n网格的每个单位。具体来说,在训练模型时,我们可以使用真实的3D模型和数据集中原来包含的相应深度信息生成准确的语义标签,从而大大减少遮挡对图像的影响。在实践中,正样本和负样本的分布不均匀是由于被研究对象占用的面积明显小于背景。因此,我们利用焦点损失[42]来解决样本分布对模型训练的负面影响。此外,我们应用了像素级的中值频率平衡技术 [ 38 ] ^{[38]} [38],因为目标对象表现出不同的大小并改变裁剪后的图像将影响姿势估计任务的性能。
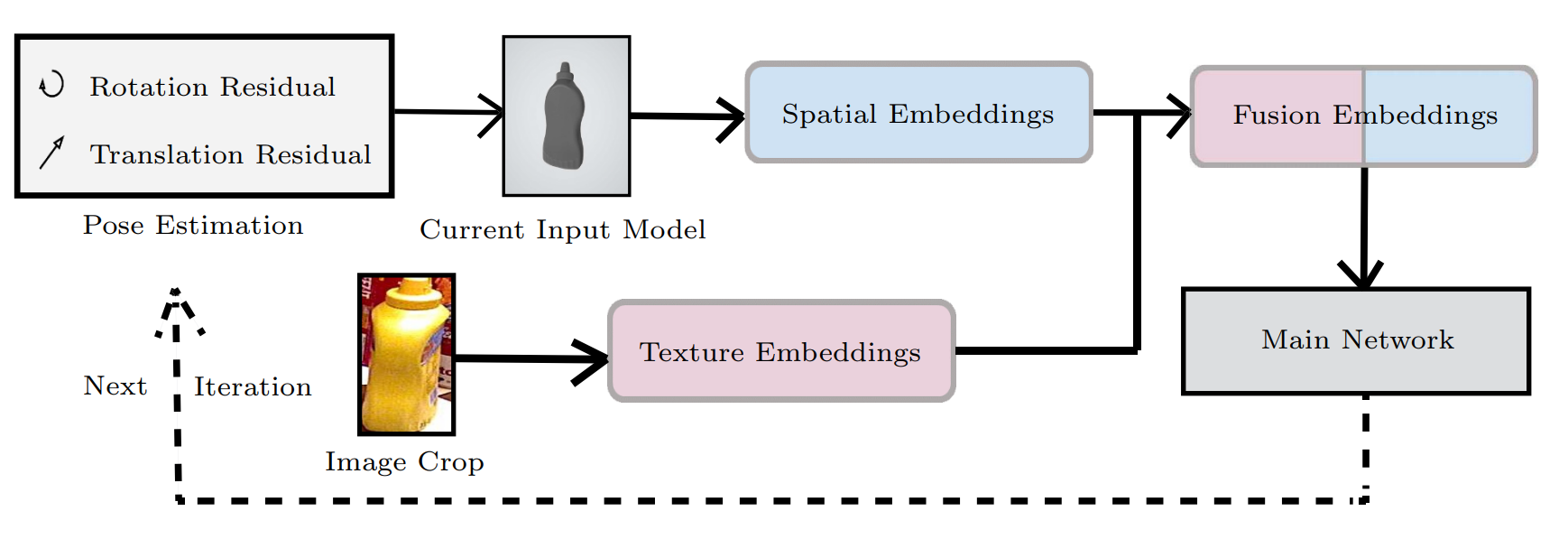
回归分支在所获得融合特征的空间通道 (XYZ) 上执行高效的 PnP (EPnP) 解,返回的 2D-3D 对应关系(旋转 R 和平移 t)和纹理通道 (RGB) 共同参与置信度计算。 我们可以根据置信度的大小将这些对应关系视为粗略的姿态估计值,并设计后续的细化迭代以提高性能,如图 3 所示。
融合网络
我们将融合各种尺寸的不同检测物体的单个多维信息。 现有的方法DenseFusion还考虑了特征的融合,并通过多层感知器(MLP)将裁剪图像上的密集深度和颜色特征链接起来,形成新的全局特征。但是,这种方法保留了上一步中特征提取产生的不必要错误,例如由于遮挡和重叠而引起的其他对象的像素信息或由于分割精度引起的背景信息。因此,未设计的融合特征将降低姿态估计的性能。 在我们的实现中使用了一种新颖的像素级策略来实现高效的融合网络,特别是在严重遮挡和不完全分割的情况下。
所提出的基于 PointNet 的融合网络补充了与处理对象上的空间特征相对应的纹理特征。我们的融合网络在每个 n×n 网格上执行局部融合和预测。因此,我们根据目标的可见和不可见部分设计不同的预测权重,以最小化和减少重度遮挡和不完美分割噪声的负面影响。
我们使用投影变换,根据真实 3D 模型、ground-truth姿势标签和原始数据集中包含的 uv 纹理,结合已知的内部相机参数,耦合每个网格上的空间特征和纹理特征。然后,我们希望在通过融合网络后生成具有均匀大小的密集特征向量。图4详细显示了融合网络的架构。当裁剪后的图像(调整为 128 × 128)通过异构神经网络时,将生成两个具有不同维度的特征结果。上层网络将根据背景和遮挡获得(m+ 1)通道的空间信息,而下层网络将根据纹理和外观获得纹理信息,然后将它们耦合以获得128×6个融合特征,包括XYZ和RGB固有属性。
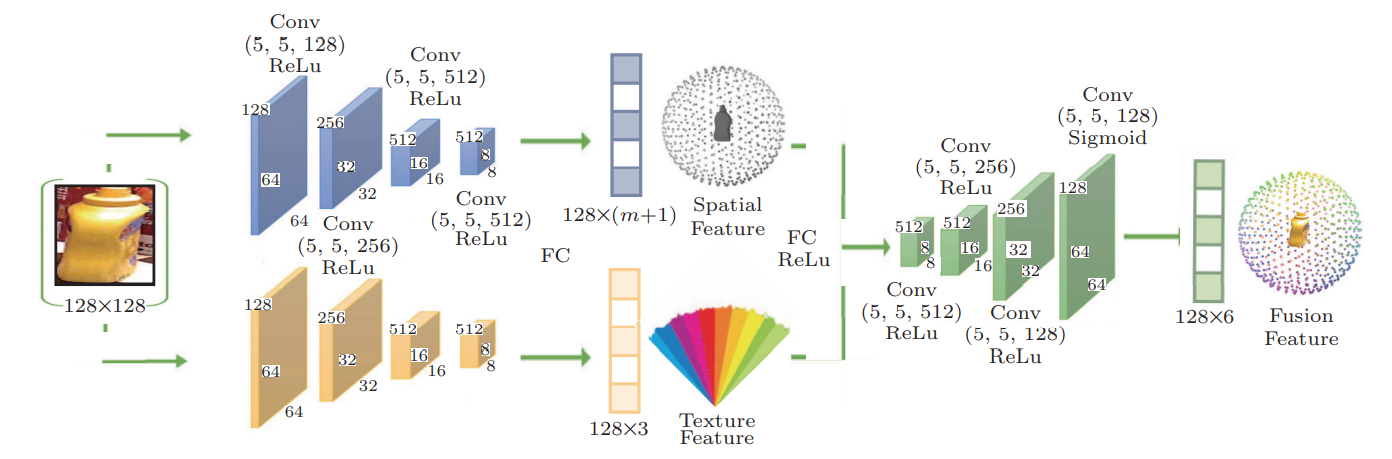
融合网络的架构。这个详细的流程图解释了在异构CNN的基础上提取空间和纹理信息的过程,然后将它们馈送到另一个中获取融合特征。m+ 1 是指第 3.2 小节中的 (m+ 1) 通道语义分割映射,包括 XYZ 和 RGB
回归分支
回归分支在利用高效PnP算法从特征向量获取空间特征并链接2D和3D关键点的位置信息方面起着重要作用。在 Seg-Driven之后,我们将关键点设置为每个目标的有界框的八个顶点,如图 5 所示。我们专注于中心在边界立方体中的锚点,并计算每个顶点的中心和角点的偏移矢量和纹理信息偏差。
C 表示每个锚点的 2D 坐标。提出第i个顶点的偏移估计 f i ( C ) f_i(C) fi(C)。因此,我们可以将顶点表示为 C + f i ( C ) C + f_i(C) C+fi(C),具有来自原始数据集的精确2D坐标 C i G T C_i^{GT} CiGT。锚点 T 的纹理、相应的偏移 f i ( T ) f_i(T) fi(T)和精确的纹理 T i G T T_i^{GT} TiGT表示如下:


新颖的损失函数表示如下:

在这里,我们使用L1损失函数而不是L2函数,因为前者对不良姿势样本的敏感性低于后者。我们设置相等的权重,因为空间(x,y,z)和纹理(r,g,b)特征都呈现相同的维度。
我们使用预测的多组 EPnP 结果(下标 i)、旋转矩阵 R 和平移矩阵 t 及其相应的真实值(上标 GT)来构造重构误差:

其中 p n p_n pn表示从真实 3D 模型中选定的第 n 个 3D 角点。但是,我们要确定哪种姿态估计可能是最佳假设,因为PnP算法可能导致多组近似解。因此,我们需要使用RANSAC来平衡每个预测之间的置信度。基于 sigmoid 的函数 w 用作激活函数,以生成任何一组 EPnP 算法结果的置信度 C o n i Con_i Coni。由于(2),最小化的损失函数变为:

其中 C o n i Con_i Coni表示我们的姿态估计与真正的三维变换之间的近似分数。在 (3) 中获取 C o n i Con_i Coni后,我们设计一个新的损失惩罚项,如下所示:

其中 Θ 是一个权衡参数。最后,将 (1) 和 (4) 放在一起,回归损失变为:

其中 ω p o s ω_{pos} ωpos和 ω p r o ω_{pro} ωpro加权了这两种损失的影响。
迭代算法为每个目标生成的大量候选结果将消耗不必要的计算资源。因此,我们使用具有RANSAC机制(n = 10)[43]的EPnP算法来获得考虑效率的6D姿态。图6说明了图像和3D模型之间的2D-3D对应过程。
迭代细化
我们提出了一种具有网络架构的迭代最优过程,该过程显然以稳健有效的方式提高了姿态估计性能。
优化调整旨在通过迭代形式尽可能广泛地减少计算和权重引起的噪声,并改进姿态估计的性能。从一开始就做出新的预测是不必要的,因为我们已经获得了令人满意的结果。但是,我们在主网络后面添加了一个模块来完善之前的结果。 因此,我们使用主网络的结果作为初始值,执行细化迭代,然后利用迭代结果作为新输入并重复此步骤。迭代优化的重要操作旨在将原始数据集中的3D模型与获得的姿态估计相结合,从而提供最大的置信度,并进行投影变换以输出相应的图像。由于分割分支,图像继续在主网络中迭代,以提高性能的准确性。
此模块如图 3 所示。我们在 K(在我们的实验中 K = 2)迭代后获得姿态估计值,如下所示:

其中 M R K , t K M_{RK,tK} MRK,tK 表示第 K 个欧几里得变换,包括旋转和平移。
这篇关于6D Object Pose Estimation in Cluttered Scenes from RGB Images的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







