本文主要是介绍Image Enhancement Guided Object Detection in Visually Degraded Scenes,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Abstract
目标检测准确率在视觉退化场景下降严重。一个普遍的解决方法就是对退化图像进行增强然后再执行目标检测。但是,这是一种次优的方案,而且未必对目标检测的准确率有提升,因为图像增强和目标检测两个任务的不同。为了解决这个问题,我们提出了一种图像增强引导目标检测的方法,以端到端的方式定义了一个检测网络和一个额外的增强分支。具体来说,增强分支和检测分支以并行的方式组织,并设计了一个特征引导模块来连接这两个分支,这优化了检测分支中输入图像的浅层特征,使其与增强图像的浅部特征尽可能一致。由于增强分支在训练过程中被冻结,这样的设计起到了利用增强图像的特征来指导对象检测分支的学习的作用,从而使学习到的检测分支同时意识到图像质量和对象检测。测试时,删除了增强分支和特征引导模块,因此检测不需要额外的计算成本。
Introduction
通常,有三种方法可以将图像增强和目标检测任务结合在神经网络中。
- 首先训练图像增强网络,然后将增强后的图像作为输入来训练检测网络。
- 第二个以端到端的方式级联增强网络和检测网络
- 第三部分考虑了本文提出的两种网络并行方式。三种不同组合方式的流程图如图1所示。
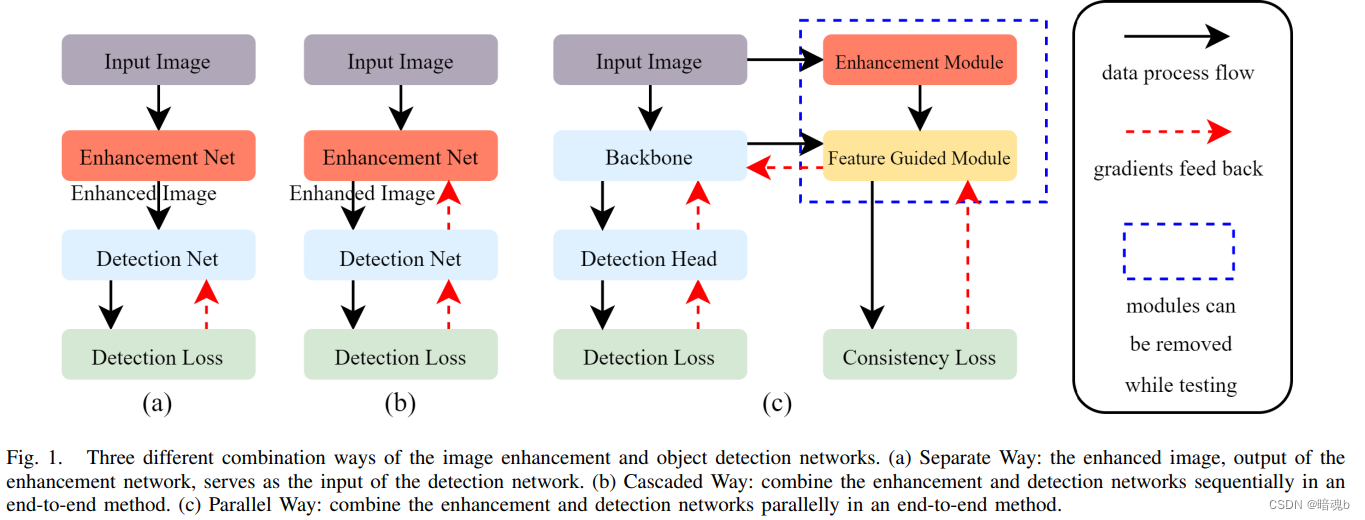
对于第一种方法:已经被证明,增强后的图像并不能总是导致高级视觉任务的效果提升,例如目标检测,因为这两个独立任务的目标不同。
更多的努力在于第二种方式,将两个任务集成到端到端的网络中,并联合优化增强网络和目标检测网络。
我们提出了一种图像增强指导目标检测的方法来提高视觉退化场景的检测性能。它由三部分组成:一个图像增强分支、一个检测分支、一个特征指导模块。更具体地说,前两个分支是以并行的方式组织的,第三个模块被设计为通过约束增强图像的低级别特征图与检测分支产生的特征图之间的一致性来桥接这两个分支,因为低级别特征图包含更多细节。尽管DSNet[17]中也采用了并行方式,但我们的方法与DSNet有很大的不同。首先,DSNet只面向模糊对象检测,而我们的方法更灵活,可以通过在我们的框架中选择不同的图像增强分支来适应不同的场景。其次,DSNet的两个子网共享用于对象分类和对象定位的公共块模块,而我们的方法使用一致性损失来约束检测分支进行训练。
本文主要贡献如下:
- 提出了一种新的框架用于视觉退化场景的目标检测。
- 设计了一个特征引导模块,通过强制其特征图与增强分支的特征图一致,提高检测分支本身的性能,使检测分支学习更多信息特征。在测试阶
- 段,只需要检测分支,并且不引入额外的计算成本。
- 在2021年水下机器人采摘大赛(URPC2021)、1 ChinaMM[27]、RTTS[28]、LLVIP[29]和ExDark[30]上的大量实验表明,与原始网络相比,我们的增强引导检测网络可以显著提高性能。据我们所知,这是第一次用通用框架来处理这三种视觉退化场景(水下、朦胧和微光场景)中的物体检测。
Method
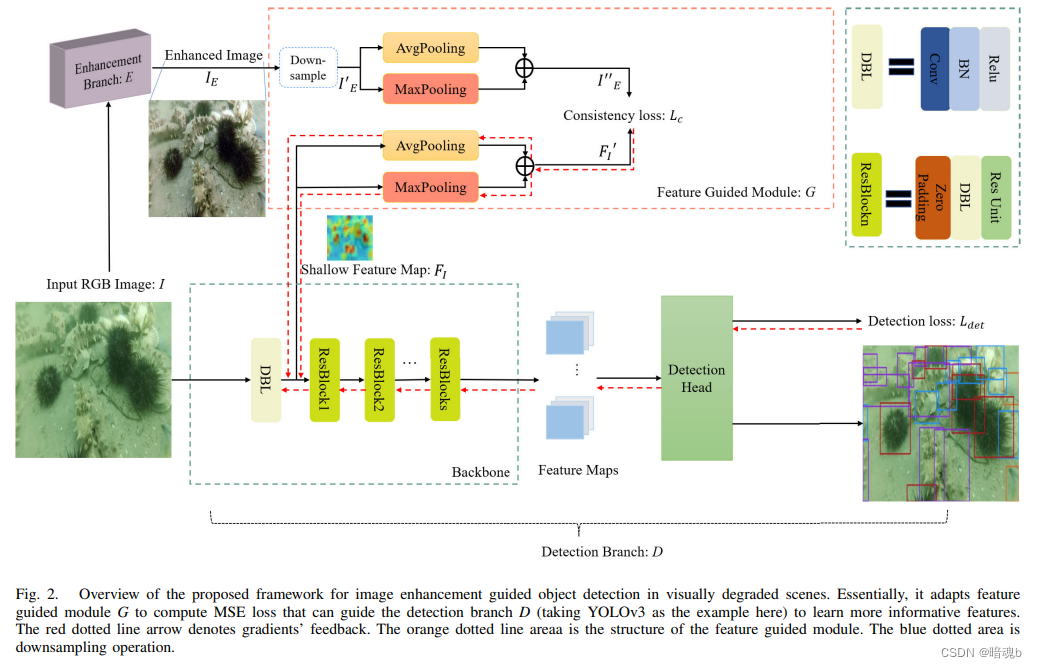
原始图像I作为E和D的输入。然后浅层特征FI作为G的输入。IE通过下采样操作得到IE’,IE’的尺寸将与FI一样,由于增强分支的参数在训练过程中是固定的,IE’因此保持不变,在Lc的损失下,FI将倾向于IE’,Lc测量IE’'和FI’的相似性。我们固定了增强分支的参数,以防止它被检测分支同化,因此可以使检测分支学到更多目标细节。我们强调,尽管增强分支E可以生成清晰的图像,但我们的目的是监督检测分支学习更好的特征表示,用于对象定位和分类。
Overview of the Method
针对缺乏处理视觉退化场景中对象检测的通用框架的问题,我们提出了一种模块化网络设计方法,该方法由检测分支、增强分支和特征引导模块组成。前两个分支以并行的方式组织,第三个分支用于引导检测分支的低层学习对象的丢失细节。由于在视觉退化场景下获得的对象的特征退化,如何更好地提取低级别特征对于检测很重要,一些工作[17],[55]对此进行了研究,其中将增强图像中的特征输入到以下检测分支。为了提高检测网络提取特征的能力,本文使用图像增强的特征作为指导,并且使检测分支的低级特征图倾向于图像增强。由于物体的特征在增强图像中引人注目,该指导可以强制检测分支学习物体的更详细信息,从而提高视觉退化场景中的检测性能。应该注意的是,在不增加网络计算成本的情况下,在测试阶段删除了增强分支和特征引导模块。
Detection Branch
对于在不利条件下拍摄的图像,对象的特征通常会退化或淹没在背景中,使对象从一开始就被网络忽略。因此,提升检测性能,增强特征提取能力是至关重要的,尤其是对于底部卷积层。如图2所示,以YOLOv3为检测分支的例子,对浅DBL层的特征图进行了细化,它由三个部分组成:卷积层、批量归一化层和RELU激活。输出的特征图FI流到两个地方:特征引导模块G和以下检测网络。输出特征图流向两个地方:特征指导模块G和检测网络。对于提出的指导模块G,FI会倾向于IE’。同时,这些明显的特征被传播到下面的检测分支,从而提高了最终的检测性能。
Enhancement Branch
增强分支实际上是一个预训练的图像增强模型,它输入原始图像并输出增强图像,并且应该根据所研究的成像场景进行选择。也就是说,对于水下目标检测,选择水下图像增强网络作为增强分支,对于雾天条件下的目标检测,考虑去雾模型。
这里,从增强模型输出增强图像而不是增强特征图主要基于以下两个考虑:
- 首先,在不知道其内部结构的情况下,整个增强网络可以很容易地作为黑匣子插入到我们的框架中,从而为将任何其他增强网络纳入我们的框架带来了灵活性,因此我们的方法可以用于各种视觉退化场景中的对象检测。
- 其次,由于不同增强网络的多样性,很难选择合适的特征图来提供足够的引导信息。
例如,UIEC∧2-Net由两个具有不同角色的连续块组成,它们相互协作以输出最终结果。提取任一块的特征图可能会丢失有用的信息。即使由于数据间隙,使用增强图像来引导低级别特征图也是不可能的。
为了解决这种不匹配,提出了一种特征引导模块,并将在下文中进行描述。
Feature Guided Module
图2显示了特征引导模块的结构。有两个输入:增强图像IE和浅层特征图FI。然后,对于它们中的每一个,分别沿着通道轴进行最大池化和平均池化,以获得两个压缩的特征图。将这两个特征图连接起来,生成仅具有两个通道的特征描述符。沿通道轴应用池化操作可以有效地突出显示信息区域。我们相信,最大池和平均池操作可以使模块学习对象的主要特征。
Loss function
我们提出的方法的损失函数包含两个主要成分,检测损失Ldet和一致性损失Lc
测量F’I和I’'E的一致性损失函数MSE
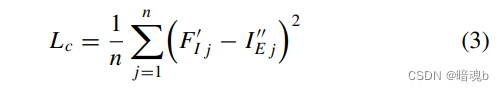

λc设置为0.5
experiments
Details
batch size:4,没有使用数据增强,RTX3090,
DATASETS
haze image datasets
在RTTS里抽了3673张图片作为训练集,保留649张图片作为测试集。
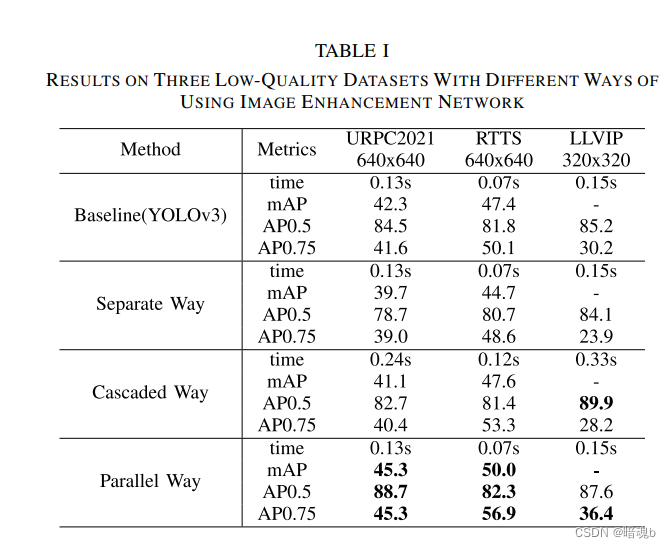 * 与微调方法YOLOv3相比,增强和检测任务的分离(Separate Way)降低了物体检测性能,尽管增强后的图像更符合人类的视觉感知。仅用于视觉增强的变化似乎干扰了检测网络的特征提取
* 与微调方法YOLOv3相比,增强和检测任务的分离(Separate Way)降低了物体检测性能,尽管增强后的图像更符合人类的视觉感知。仅用于视觉增强的变化似乎干扰了检测网络的特征提取
- 级联方式(cascaded way)并没有带来显著的性能提升,许多指标,如AP0.75,甚至略有下降。同时,由于获得增强图像的额外过程,检测时间显著增加。
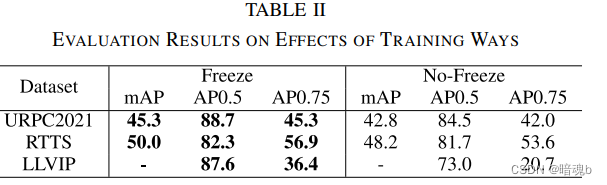
- 对于并行方式(parallel way),在保持相同计算成本的同时,观察到显著的性能改进。在URPC2021中,与基线相关的mAP增加了3%(从42.3%增加到45.3%)。在RTTS上,获得了2.6%的增量(从47.4%到50.0%)。在LLVIP上,Parallel Way的AP0.5提高了2.4%,AP0.75提高了8.2%(从28.2%提高到36.4%)。
这篇关于Image Enhancement Guided Object Detection in Visually Degraded Scenes的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





