本文主要是介绍【论文笔记】DiL-NeRF: Delving into Lidar for Neural Radiance Field on Street Scenes,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
原文链接:https://arxiv.org/abs/2405.00900
1. 引言
自动驾驶等应用领域需要逼真的仿真。传统的仿真流程需要手工创建3D资产并构成虚拟环境,但其人力和专业需求使其难以具有可放缩性。
NeRF有不错的仿真能力,但需要大范围覆盖的训练数据以学习潜在的几何、材料特性和光照。在自动驾驶场景中,数据覆盖很稀疏,且相机的轨迹共线。此外,路面纹理较少,进一步引入重建的模糊性。
本文引入激光雷达作为NeRF缺少显式几何约束的补偿。本文的方法称为DiL-NeRF,大幅提升视图合成的质量。
本文(1)使用3D稀疏卷积从激光雷达点云中提取3D网格表达的几何特征;(2)积累激光雷达点云进行深度监督,并考虑遮挡(从近到远地监督深度,并逐步过滤虚假深度);(3)使用激光雷达密集化训练视图,即将激光雷达点云投影到新训练视图上,加入训练视图中,并使用上述监督策略考虑遮挡问题。
4. 方法
4.1 概述
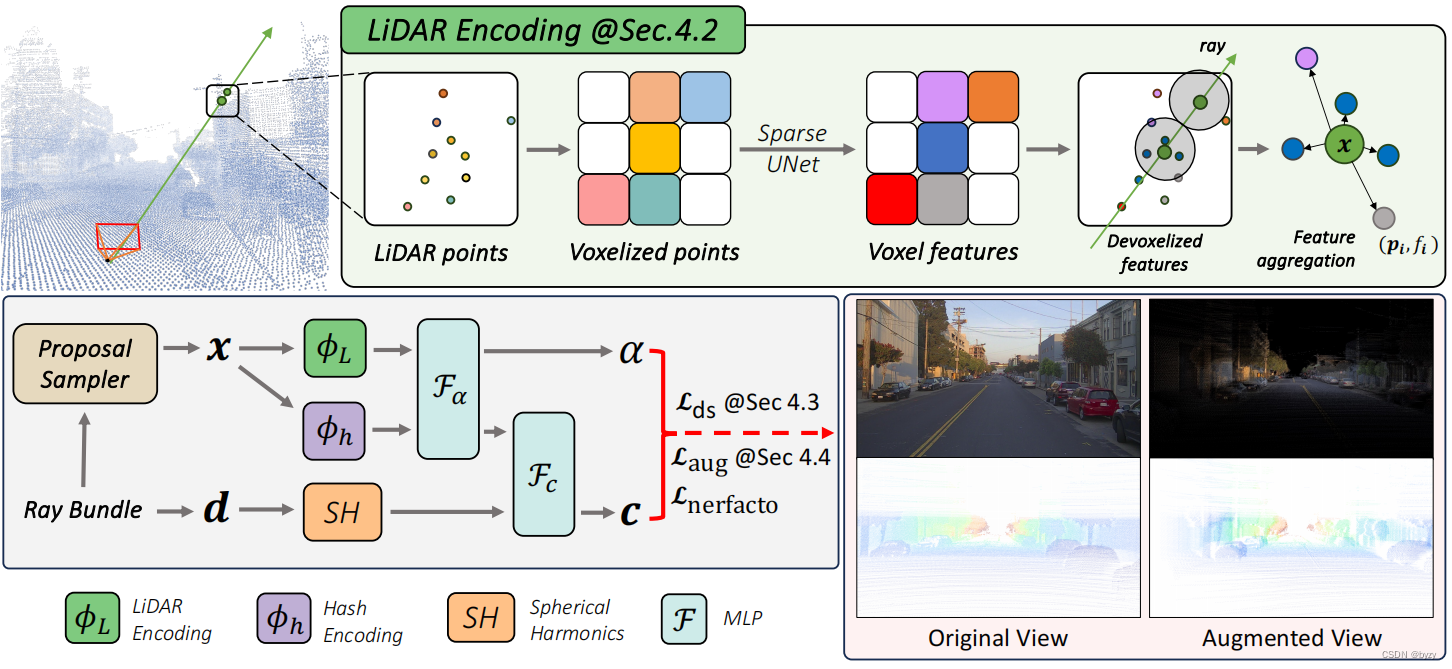 本文方法基于Nerfacto,以激光雷达点云为输入,提取其中的几何特征,并与基于哈希的特征网格融合。混合特征被送入MLP解码颜色与密度,再通过标准的体渲染。输出会使用跨帧积累的密集激光雷达点作为深度监督,同时考虑遮挡。这在原始Nerfacto损失 L Nerfacto L_\text{Nerfacto} LNerfacto的基础上引入两个额外损失 L d s L_{ds} Lds和 L a u g L_{aug} Laug:
本文方法基于Nerfacto,以激光雷达点云为输入,提取其中的几何特征,并与基于哈希的特征网格融合。混合特征被送入MLP解码颜色与密度,再通过标准的体渲染。输出会使用跨帧积累的密集激光雷达点作为深度监督,同时考虑遮挡。这在原始Nerfacto损失 L Nerfacto L_\text{Nerfacto} LNerfacto的基础上引入两个额外损失 L d s L_{ds} Lds和 L a u g L_{aug} Laug:
L = L Nerfacto + λ 1 L d s + λ 2 L a u g L=L_\text{Nerfacto}+\lambda_1 L_{ds}+\lambda_2 L_{aug} L=LNerfacto+λ1Lds+λ2Laug
其中
L Nerfacto = L r g b + λ 3 L d i s t + λ 4 L interval L_\text{Nerfacto}=L_{rgb}+\lambda_3 L_{dist}+\lambda_4 L_\text{interval} LNerfacto=Lrgb+λ3Ldist+λ4Linterval
4.2 带激光雷达编码的混合表达
动机:激光雷达点云有潜力对NeRF进行几何指导,但由于其稀疏性(即便有时间积累),其渲染分辨率也很低。此外,激光雷达无法捕捉完整的场景(如超过一定高度的建筑物)。本文将激光雷达特征与高分辨率空间网格特征融合,以利用两者的优势进行高质量且完整的场景渲染。
激光雷达特征提取:首先聚合序列所有帧的点云生成更加密集的点云。然后进行体素化,其每个体素的特征为其中所有点位置坐标的平均值。使用3D稀疏UNet编码场景几何特征,输出神经体特征( n n n维),这产生了本文的激光雷达嵌入 P = { ( p i , f i ) ∣ i = 1 , ⋯ , N } P=\{(p_i,f_i)|i=1,\cdots,N\} P={(pi,fi)∣i=1,⋯,N},其中点 i i i位于 p i p_i pi处,其对应体素的神经特征为 f i f_i fi,编码了 p i p_i pi周围的局部和全局几何。
激光雷达特征的查询:对射线上的每个采样点 x x x,若其 R R R半径邻域内至少有 K K K个激光雷达点,则查询其对应的激光雷达特征(否则其激光雷达特征被设置为空,即全零)。本文使用固定半径最近邻(FRNN)方法选择 x x x的 K K K近邻激光雷达点集 S x K S_x^K SxK,并作为采样点的的分布,随训练的收敛动态地向表面集中。
根据Point-NeRF,本文使用MLP F F F将激光雷达点的特征映射为神经场景描述。对于 x x x的第 i i i个邻居点, F F F以其激光雷达特征 f i f_i fi和相对位置 x − p i x-p_i x−pi为输入,输出神经场景描述:
f i , x = F ( [ f i , x − p i ] ) f_{i,x}=F([f_i,x-p_i]) fi,x=F([fi,x−pi])
其中 [ ⋅ , ⋅ ] [\cdot,\cdot] [⋅,⋅]为拼接。为得到采样位置处的激光雷达编码 ϕ L ( x ) \phi_L(x) ϕL(x),本文使用标准的逆距离加权聚合神经场景描述 f i , x f_{i,x} fi,x:
ϕ L ( x ) = { ∑ i ∈ S x K w i f i , x ∑ i ∈ S x K w i 若 S x K ≠ ∅ 0 否则 \phi_L(x)=\begin{cases}\frac{\sum_{i\in S_x^K}w_if_{i,x}}{\sum_{i\in S_x^K}w_i}&若S_x^K\neq\emptyset\\0&否则\end{cases} ϕL(x)=⎩ ⎨ ⎧∑i∈SxKwi∑i∈SxKwifi,x0若SxK=∅否则
其中 w i = 1 ∥ p i − x ∥ w_i=\frac1{\|p_i-x\|} wi=∥pi−x∥1
特征融合进行辐射解码:本文将激光雷达编码 ϕ L ( x ) \phi_L(x) ϕL(x)与哈希编码 ϕ h \phi_h ϕh拼接,使用MLP F α F_\alpha Fα预测各样本的密度 α \alpha α和密度嵌入 h h h。最后,相应的颜色 c c c由在视线方向 d d d下的球面谐波编码 S H SH SH和密度嵌入 h h h,通过另一MLP F c F_c Fc预测:
α , h = F α ( [ ϕ L ( x ) , ϕ h ( x ) ] ) c = F c ( [ h , S H ( d ) ] ) \alpha,h=F_\alpha([\phi_L(x),\phi_h(x)])\\ c=F_c([h,SH(d)]) α,h=Fα([ϕL(x),ϕh(x)])c=Fc([h,SH(d)])
4.3 鲁棒深度监督
动机:本文将激光雷达点投影到图像平面得到深度监督信号,但激光雷达点云具有稀疏性,且对低纹理区域(如路面)的重建不充分。本文将相邻帧的激光雷达进行积累,以增加密度。但这样做需要考虑遮挡问题,即当前帧不可见的区域在相邻帧可见,会产生虚假深度。本文提出鲁棒监督方案,在训练时自动过滤虚假深度监督。
遮挡感知的鲁棒监督方案:初始时,模型用更近的、更可靠的深度数据训练(受遮挡影响小)。随着训练的进展,模型开始接收更大的深度。此时模型可以丢弃那些与预测差距很大的深度监督。所有深度点的集合记为 D = { D 1 , ⋯ , D N } D=\{D_1,\cdots, D_N\} D={D1,⋯,DN},NeRF渲染的、相应与 D i D_i Di的深度为 D ^ i \hat D_i D^i,本文按下式确定第 m m m次迭代中可靠的深度点子集 D reliable m D_\text{reliable}^m Dreliablem:
D reliable m = { D i ∣ D i ≤ ϵ t m , D i ≤ D ^ i + ϵ o m , D i ∈ D } ϵ t m = min { α t ϵ t m − 1 , ϵ t } , α t > 1 ϵ o m = max { α o ϵ o m − 1 , ϵ o } , α 0 < 1 D_\text{reliable}^m=\{D_i|D_i\leq\epsilon_t^m,D_i\leq\hat D_i+\epsilon_o^m,D_i\in D\}\\ \epsilon_t^m=\min\{\alpha_t\epsilon_t^{m-1},\epsilon_t\},\alpha_t>1\\ \epsilon_o^m=\max\{\alpha_o\epsilon_o^{m-1},\epsilon_o\},\alpha_0<1 Dreliablem={Di∣Di≤ϵtm,Di≤D^i+ϵom,Di∈D}ϵtm=min{αtϵtm−1,ϵt},αt>1ϵom=max{αoϵom−1,ϵo},α0<1
其中 ϵ t m \epsilon_t^m ϵtm为有效深度阈值, ϵ o m \epsilon_o^m ϵom为有效深度偏移量。前者过滤超出此阈值的深度,仅考虑更不可能被遮挡的近处的深度样本;该阈值随训练进展而指数增大,以包含更大范围的监督。后者过滤与渲染深度差异较大的深度,因为这些深度样本点更可能被遮挡,该阈值随训练进展而指数减小。
激光雷达深度损失:对 D reliable m D_\text{reliable}^m Dreliablem中的样本,本文使用URF中的像素级深度损失,即深度 L 2 L_2 L2损失与视线损失之和。具体来说,体渲染可归结为求射线采样点预测颜色的加权和,其理想权重集中于表面附近,故视线损失强制权重分布近似高斯分布 N ( D ^ i , ϵ n ) \mathcal N(\hat D_i,\epsilon_n) N(D^i,ϵn)(其中 D ^ i \hat D_i D^i为沿射线的真实深度):
L s i g h t = E D i ∈ D reliable m [ ∫ t n e a r t f a r ( w ( t ) − N ( D ^ i , ϵ n ) ) 2 d t ] L_{sight}=\mathbb E_{D_i\in D_\text{reliable}^m}[\int_{t_{near}}^{t_{far}}(w(t)-\mathcal N(\hat D_i,\epsilon_n))^2dt] Lsight=EDi∈Dreliablem[∫tneartfar(w(t)−N(D^i,ϵn))2dt]
其中 w w w为权重。上式可离散化为
L s i g h t = E D i ∈ D reliable m [ ∑ i ( w i − N i ) 2 ] L_{sight}=\mathbb E_{D_i\in D_\text{reliable}^m}[\sum_i(w_i-\mathcal N_i)^2] Lsight=EDi∈Dreliablem[i∑(wi−Ni)2]
其中 N i \mathcal N_i Ni为第 i i i个采样区间的概率质量,可通过区间的中值近似,如图所示。本文通过高斯分布的累积分布函数(CDF)表求取准确的概率质量。

4.4 增广的视图监督
由于视图覆盖较小,当合成偏离轨迹的视图时较为困难,本文使用激光雷达增广训练数据。首先将激光雷达点云投影到与其同步的图像上插值得到RGB值,然后将彩色点云投影到增广视图图像上,得到合成图像和深度图。增广视图为现有视图相机中心添加随机扰动 ϵ a ∈ N ( 0 , ϵ a ) \epsilon_a\in\mathcal N(0,\epsilon_a) ϵa∈N(0,ϵa)的结果。这些增广视图同样使用鲁棒深度监督训练,对应的损失项为 L a u g L_{aug} Laug。
5. 实验
5.1 实验设置
实施细节:本文关注静态场景,因此使用了边界框标注和实例分割模型过滤了所有的动态物体。
5.2 新视图合成结果
本文评估内插和外推的新视图合成结果。前者每隔一定帧数进行测试,而在其余帧上训练;后者将轨迹进行水平移动,以模拟车道变换。由于无真值,使用感知层面的FID指标。
实验表明,本文方法在所有指标上超过其余方法。可视化证明,本文方法因为激光雷达编码这种对激光雷达更深层次的使用,在细粒度结构和低纹理区域上能合成更真实的图像。
5.3 消融研究
鲁棒深度监督的作用:实验表明,使用激光雷达深度能大幅提高外推性能,且内插性能仅有略微下降。使用本文的鲁棒深度监督能提高所有指标的性能。使用预处理方式移除遮挡点的性能低于本文自适应处理遮挡的方法。可视化表明,使用单帧激光雷达进行深度监督,能在高纹理区域进行精确渲染,但由于缺乏丰富的几何指导,在薄结够区域精度较低。使用多帧积累激光雷达点云进行监督,会导致渲染深度图有大量噪声,这是因为数据的深度噪声。使用本文的鲁棒深度监督后,可得到更密集的深度图,在更复杂的结构上能精确重建,且能排除被遮挡的深度。
激光雷达编码的作用:激光雷达编码能提高所有指标。可视化表明,使用激光雷达编码后,可以合成更清晰的纹理。这归因于本文基于卷积的结构,对激光雷达点云的噪声和密度变化有弹性。
增广视图监督的作用:虽然定量结果的提升有限,但其能一致地提高外推性能。
补充材料
7. 额外消融结果
激光雷达编码:在不使用激光雷达编码的情况下,若使用更大的哈希网格特征,可以在内插情况下提高性能,但其外推性能因为过拟合略有下降。
使用MLP或PointNet++替换3D卷积编码激光雷达,性能均低于本文方法,这表明使用3D卷积进行全局上下文学习的好处。
本文的激光雷达编码引入的时空开销很低。
增广视图监督:在一定数量的增广视图监督下,性能有所提升,但超过这一数量会导致性能下降,因增广视图主导了训练。改变朝向的影响很小,可能是因为车辆多朝前运动。
CDF和中点近似:实验表明,在单帧激光雷达监督下,使用CDF比中值近似有略高的性能。
8. 按距离的定量结果
实验表明,本文方法在所有距离划分上均比UniSim有更高的性能。
9. Argoverse上的结果
实验表明,与仅依赖激光雷达解码辐射的方法相比,本文方法结合了激光雷达编码和高分辨率哈希网格,能渲染完整(无空像素)且分辨率更高的图像。
10. 额外的实施细节
10.1 数据处理
过滤动态物体:给定2D边界框标注,本文使用Mask-RCNN得到相应的掩膜,在训练时不采样掩膜内的像素,测试时也不计算其中的指标。3D边界框中的激光雷达点也被移除,剩余点被用于生成深度图和增广数据。
激光雷达深度生成:使用当前帧最近的10帧点云变换到世界坐标系并投影到图像上。多个点落入同一像素时,使用投影深度的最小值作为像素的深度。
场景归一化:为处理无界场景,需要通过场景归一化进行场景收缩。具体来说,本文使用球来建模感兴趣的场景,其直径为训练时任意两个相机的最大距离加50m。
10.2 网络结构
本文的网络可分为4部分:提案采样器,激光雷达编码,密度网络和色彩网络。
提案采样器:由两个连续的神经密度场(由“融合”MLP)组成,这些MLP使用哈希编码处理3D位置,后续输入密度网络预测密度。两个融合MLP有相同的超参数(最小哈希分辨率、哈希编码级数、各级哈希编码特征维度、MLP层数和隐特征维度),区别在于最大哈希分辨率。
激光雷达编码:以激光雷达点云为输入,输出各点的高维特征,并根据采样位置查询。具体来说,将体素化后的激光雷达数据输入稀疏UNet(编码器-解码器结构、含有跳跃连接和多尺度融合;仅在非零元素处进行卷积);输出特征为激光雷达特征。
密度网络:计算哈希编码,与激光雷达编码拼接融合,输入MLP,得到采样点的密度和密度嵌入,后者会输入色彩网络。
色彩网络:以密度嵌入和球面谐波编码的射线方向为输入,使用MLP预测各采样位置的RGB值。
这篇关于【论文笔记】DiL-NeRF: Delving into Lidar for Neural Radiance Field on Street Scenes的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







