本文主要是介绍用于深度估计的边缘增强自适应加权网络ADAPTIVE WEIGHTED NETWORK WITH EDGE ENHANCEMENT MODULE FOR MONOCULAR SELF-SUPERVIS,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
ADAPTIVE WEIGHTED NETWORK WITH EDGE ENHANCEMENT MODULE FOR MONOCULAR SELF-SUPERVISED DEPTH ESTIMATION
用于深度估计的边缘增强自适应加权网络
(个人观点)怎么说呢,看完这篇我直接狂喜好吧,传统的边缘提取加损失函数的变体构建两个创新点,指标方面R50打R18,直接上驷对下驷。咱就是说就算不是图像方面的顶会,这也会被人们看到的呀。还是大写的羡慕,不知道ICASSP在评审的时候有没有说他的论文不够novelty,有没有问他为什么没有对比最新的文献,有没有说他描述不够精炼?总不能四海之内都是兄弟的吧?
0 Abstract
自监督单目深度估计广泛的应用与其他领域,但是目前的方法不能很好的预测图像边界的深度信息,因为遮挡和纹理系数会导致光度一致性评估错误。为了解决上述问题,本文提出了EEM的边缘增强模块和基于纹理系数度的TSAW加权损失函数,其中EEM加强边界信息的深度提取,TSAM根据系数度分配不同的权重,从而更有针对性地构建几何约束。KITTI上测评优异。
1 Introduction
深度估计是计算机视觉的一个基本问题,目的是从二维图像中获得不同场景的三维信息。准确的深度估计在三维重建、自动驾驶和增强现实等方向都有着广泛的应用。随着深度学习的快速发展,一些研究人员利用监督信号来训练卷积神经网络,以便于从RGB图像中恢复深度信息。但是监督方法需要大量的标记数据来训练模型,从而限制了应用场景的灵活性。与此相反的是,自监督学习利用固有的约束方法作为监督信号,而不使用任何其他约束,具有重要的研究价值和广泛的应用前景。
单目自监督深度估计从单幅图像中预测稠密深度图,与其他方法相比,单目深度估计只需要一个摄像头即可部署,着使得它在大多数场景中都可以得到使用。2017年,Godard首次提出了从图像对中恢复深度信息的方法,zhou等人首次提出了从图像序列中恢复深度信息的方法。随后的大多数方法都以上述上述两种作为基础。 但是这些方法在深度图的边界处总是存在模糊的现象。总体贡献如下:
- 提出一个EEM的边缘增强模块,采用Sobel算子和高斯模糊输出增强边缘的特征表示。
- 提出了一种基于纹理稀疏的自适应加权损失来解决遮挡和纹理稀疏问题,通过分析相邻帧之间的差异,来为每个像素分配不同的权重。
- KITTI效果良好。
2 Methodology
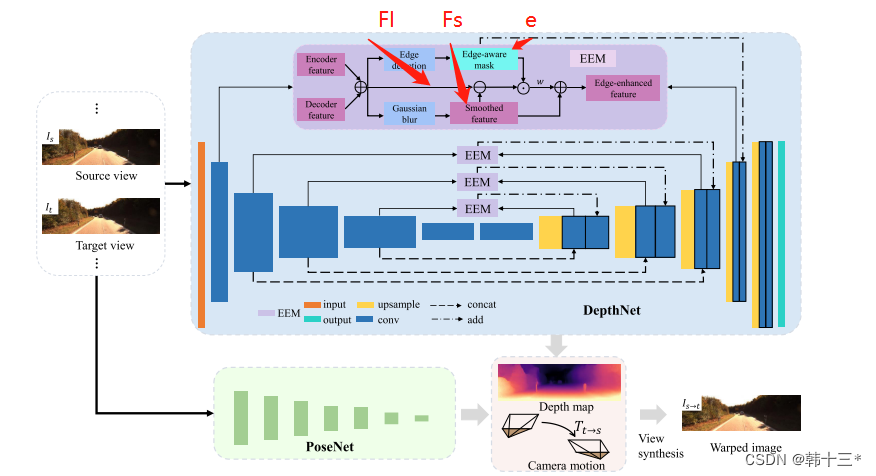
网络结构如上所示,在传统的结构上加了EEM的边缘增强模块(我真是服了,这公式符号都不标的吗)。
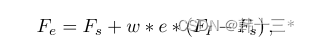
FI是编码器和解码器的特征相加,Fs是高斯模糊后的特征表示,e是Sobel算子处理过后的边缘掩膜,w是超参数为1.5,Fe为输出的边缘增强特征。
遮挡会导致几何约束失效,纹理丰富的区域在相邻帧之间的差别会变大,而原本的光度损失不能很好的约束这些区域,本文提出了TSAW loss。公式如下。
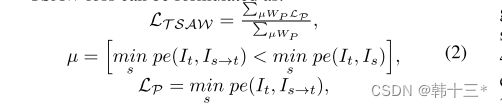
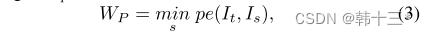
先来说µ,µ最早是由mono2提出,由于运动相机和静态世界的假设,当场景中出现运动像素时,由于视差的计算原理会导致图中出现空洞(可以理解为两幅图片中在同一个位置存在同一块像素,做差后为0),所以µ是用于剔除和相机具有相同运动速度的像素。下面是mono2的公式。在mono2中It’-t是代表了由相邻帧想投影的扭曲图片,其中It‘是代表了两幅图片,即It-1和It+1,由于以前都是在两个相邻帧做扭曲后取平均,但mono2发现,由于相邻帧之间会存在遮挡,这可能会导致It-1 的重投影损失是完全正确的即损失较小,但It+1由于遮挡损失较大,再去平均会导致网络学习到错误的投影特征,所以提出,应该在两个相邻帧中取最小值,这是min的由来。再说这个公式,小于号前面相当于是对扭曲后的图像做重投影损失计算,后面是对相邻帧进行重投影损失计算,后面的损失只要相机是运动的就一定存在,而前面的损失,当扭曲的图片在计算静止像素的重投影是是可能会与后面一致或者小于后面,但运动像素的重投影可能反而会由于网络计算位姿的误差性导致大于后面。当相机静止时,相邻帧相同,后面时刻为0,该掩膜会直接忽略全部。总体来说是通过该掩膜去选取满足运动相机,静态世界等条件的像素来进行计算。
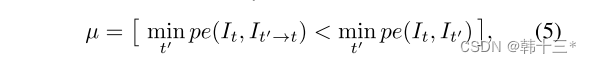
再来说LP,以下是mono2的逐像素损失,总体就是光度损失在相邻帧之间进行了最小值选择。
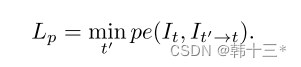
而本文多了一个WP,意思是通过计算当前帧和相邻帧之间的差异,自动生成一个权值矩阵。对于光度损失来说,是用来比较两幅图片的相似度,当输入相邻帧,近处的光流大,远处的光流小,光流大的地方损失高,损失高的地方应该对应着近处的纹理丰富区域,这些地方的约束性应该加强。
3 Experiments
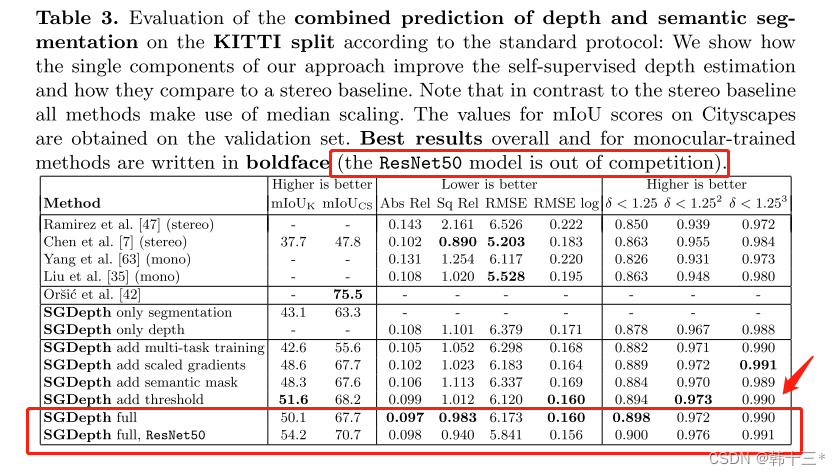
KIIIT数据集效果,本文是ResNet50框架,我只想说哥们是不是放错数据了Mono2的0.877是R18不是R50啊,还有SGD的R50已经是0.900了。

本文KITTI评估。
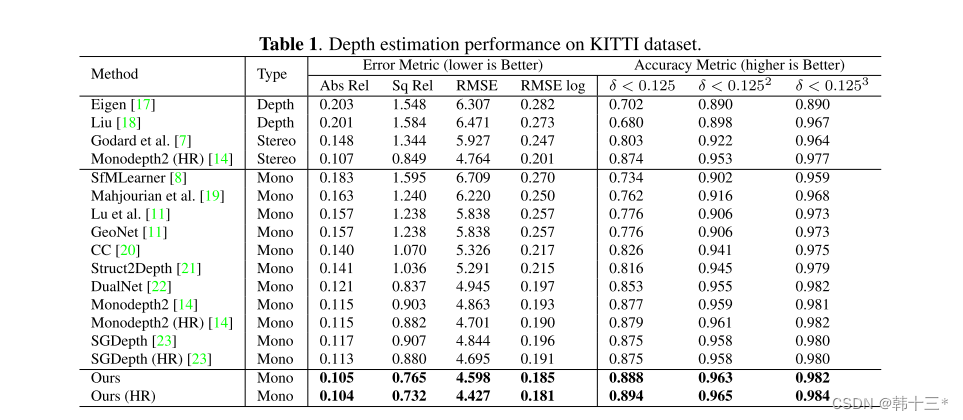
Mono2的R50。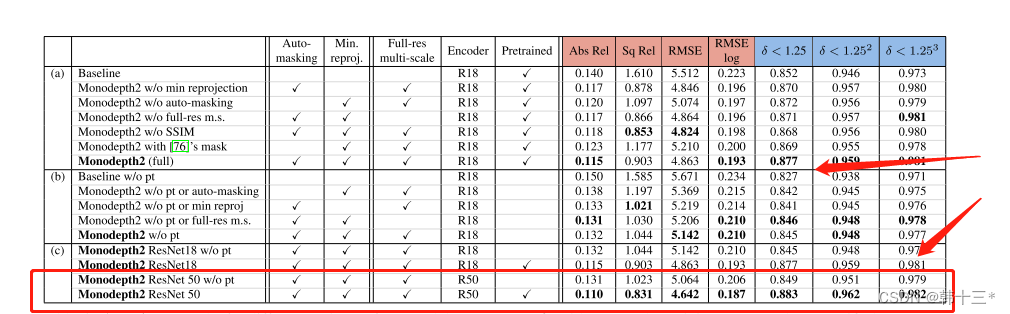
SGD用了监督语义,指标高一点就高一点吧,人家明确说了R50都out of competition了。
这篇关于用于深度估计的边缘增强自适应加权网络ADAPTIVE WEIGHTED NETWORK WITH EDGE ENHANCEMENT MODULE FOR MONOCULAR SELF-SUPERVIS的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








