本文主要是介绍【深度学习】Transformer分类器,CICIDS2017,入侵检测,随机森林、RFE、全连接神经网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1 前言
- 2 随机森林训练
- 3 递归特征消除 RFE Recursive feature elimination
- 4 DNN
- 5 Transformer
- 5.1. 输入嵌入层(Input Embedding Layer)
- 5.2. 位置编码层(Positional Encoding Layer)
- 5.3. Transformer编码器层(Transformer Encoder Layer)
- 5.4. 解码层(Decoder Layer)(非Transformer的解码器)
- 5.5. 模型的前向传播(Forward Pass)
- 5.6. 与BERT比较
- 5.7. 多头注意力机制
- 6 Transformer模型训练
- 全部代码
代码包:
https://docs.qq.com/sheet/DUEdqZ2lmbmR6UVdU?tab=BB08J2
1 前言
随着网络攻击的日益猖獗,保护网络安全变得愈发重要。传统的入侵检测系统(IDS)在应对复杂和多变的攻击模式时显得力不从心。为了应对这一挑战,我们提出了一种基于Transformer的入侵检测系统,以提高检测精度和鲁棒性。
入侵检测系统(IDS)是一种监控网络流量、识别和响应潜在安全威胁的工具。它们通过分析流量模式来检测异常行为,从而保护网络安全。然而,随着攻击技术的不断进化,传统的IDS面临着识别新型和复杂攻击的挑战。
CICIDS2017数据集介绍:
https://blog.csdn.net/yuangan1529/article/details/115024003
CICIDS2017数据集下载:
http://205.174.165.80/CICDataset/CIC-IDS-2017/Dataset/CIC-IDS-2017/PCAPs/
下载这个即可:

解压后:
执行代码包中的x01_数据分析.py,得到数据分布:

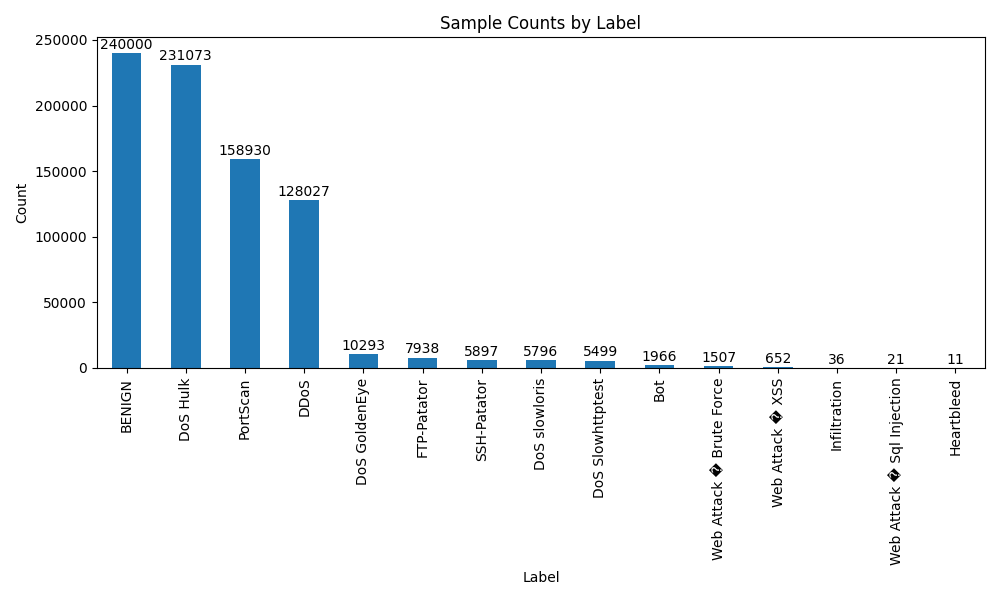
Heartbleed类别只有11个,而正常类别BENIGN有227w多个。BENIGN取24w出来用就够了。
执行程序包的x02得到一个总的csv文件combined_output.py,一个合并的csv文件。执行x03画出当前样本数量.py得到:
将我的数据文件combined_output.csv进行拆分,拆分为训练集和测试集,拆分的比例是8:2,Label列是类别(字符串形式),按照每个类别都8:2的形式拆分。对于样本数量少于500个,那么这个类别的所有数据既作为训练集,也作为测试集。
执行x05_画出训练集和测试机的样本数量直方图.py得到拆分后的数据统计:

2 随机森林训练
执行代码包的x06_0随机森林训练.py.
# 3. 拆分数据集
X_train, X_test, y_train, y_test = X[:len(data_train)], X[len(data_train):], y[:len(data_train)], y[len(data_train):]# 4. 训练随机森林模型
rf_model = RandomForestClassifier(class_weight='balanced', n_estimators=100, random_state=42, verbose=2, n_jobs=-1)
if os.path.exists('model/RandomForest_rf_model.pkl'):rf_model = joblib.load('model/RandomForest_rf_model.pkl')
else:rf_model.fit(X_train, y_train)# 保存模型joblib.dump(rf_model, 'model/RandomForest_rf_model.pkl')
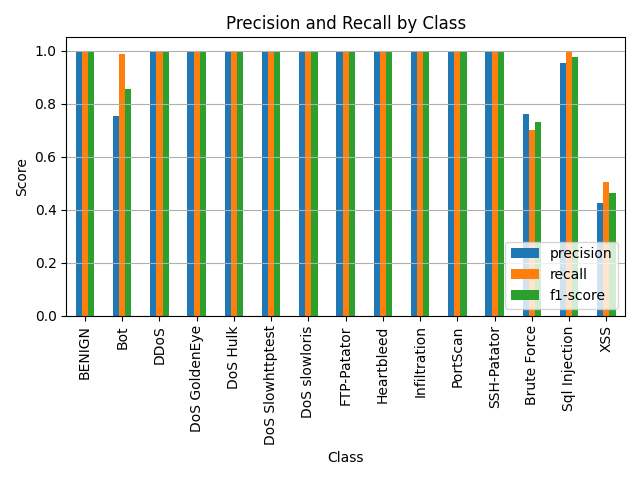
测试结果:
整体准确率: 1.00
平均准确率: 0.93, 平均召回率: 0.95
随机森林模型获取特征重要程度的方法通常是通过基于树的特征重要性计算。在随机森林中,每棵树都是基于对数据的随机子样本和随机选择的特征进行训练的。当模型训练完成后,可以根据每个特征在所有树中的分裂情况和准确度变化来评估其重要性。
可以看出有些特征很重要,有些特征就不重要:
特征重要程度:
Destination Port: 0.0785
Init_Win_bytes_backward: 0.0582
Flow IAT Mean: 0.0308
min_seg_size_forward: 0.0283
Max Packet Length: 0.0273
Init_Win_bytes_forward: 0.0271
Fwd Packet Length Max: 0.0268Fwd Avg Bytes/Bulk: 0.0000
Fwd Avg Packets/Bulk: 0.0000
Fwd Avg Bulk Rate: 0.0000
Bwd Avg Bytes/Bulk: 0.0000
Bwd Avg Packets/Bulk: 0.0000
Bwd Avg Bulk Rate: 0.0000
RF的特征选择本质上就是基于信息熵的选择,就是基于树的选择,可以看这里的参考资料:
https://scikit-learn.org/stable/modules/feature_selection.html
选取重要都大于0的特征参与训练,可以减少特征维度,计算量也就少很多了。
3 递归特征消除 RFE Recursive feature elimination
给定一个将权重分配给特征的外部估计器(例如,线性模型的系数),递归特征消除(RFE)的目标是通过递归考虑越来越小的特征集来选择特征。首先,估计器在初始特征集上进行训练,并通过任何特定属性(如coef_,feature_importances_)或可调用函数获得每个特征的重要性。然后,将当前特征集中的最不重要的特征修剪掉。该过程在修剪后的集合上递归重复,直到最终达到所需选择的特征数。
RFECV 在交叉验证循环中执行 RFE,以找到最佳特征数量。更详细地说,所选特征的数量通过在不同的交叉验证拆分上拟合 RFE 选择器来自动调整(由 cv 参数提供)。使用评分器评估所选择特征数量的 RFE 选择器的性能,并将其聚合在一起。最后,得分在交叉验证的折叠中平均,所选特征的数量被设置为最大化交叉验证得分的特征数量。
RFE类一些主要的可选参数:
-
estimator:要使用的外部估计器对象,默认为
None。如果不指定,则RFE会在内部使用estimator参数指定的算法来选择特征。 -
step:每次迭代中删除的特征数量,默认为1。较大的步长可能会加快特征选择过程,但可能会导致性能下降。
-
verbose:控制输出的详细程度,默认为0(不输出任何信息)。如果设置为1,则在特征选择过程中会输出一些信息。
-
importance_getter:一个可调用对象,用于获取特征的重要性。默认为
'auto',表示根据估计器类型自动选择合适的方法。 -
min_features_to_select:最小要选择的特征数量,默认为1。在特征数量小于此值时,特征选择过程将停止。
执行代码包中的x07_0RFE.py,挑选20个最重要的特征,挑选结果为:
Index([‘Destination Port’, ‘Flow Duration’, ‘Total Length of Bwd Packets’,
‘Fwd Packet Length Max’, ‘Bwd Packet Length Max’, ‘Flow IAT Mean’,
‘Flow IAT Std’, ‘Flow IAT Max’, ‘Fwd IAT Total’, ‘Fwd IAT Mean’,
‘Fwd IAT Max’, ‘Bwd Header Length’, ‘Max Packet Length’,
‘Packet Length Mean’, ‘Average Packet Size’, ‘Subflow Fwd Bytes’,
‘Subflow Bwd Bytes’, ‘Init_Win_bytes_forward’,
‘Init_Win_bytes_backward’, ‘min_seg_size_forward’],
dtype=‘object’)
4 DNN
使用这20个特征训练DNN网络,执行x08_0DNN训练.py和x08_1DNN测试.py,得到DNN准确率:
整体准确率: 0.98
==============================
dnn_classification
Macro-average Precision: 0.7794444444444445
Macro-average Recall: 0.8433333333333333

特征太少了,计算量是少了,但是准确度也下降了。
5 Transformer
Transformer模型最初由Vaswani等人在自然语言处理(NLP)领域提出,以其在处理序列数据方面的优越性能而闻名。与传统的循环神经网络(RNN)和长短期记忆网络(LSTM)相比,Transformer能够更高效地捕捉序列数据中的长距离依赖关系。这一特性使其在网络流量分析中表现出色。
基于Transformer架构,包括以下几个关键部分:
- 输入嵌入:将网络流量数据转换为固定维度的向量表示,同时保留其序列信息。
- 位置编码:通过位置编码保留特征序列的顺序信息。
- 自注意力机制:应用自注意力层,捕捉特征之间的全局依赖关系。
- 编码器-解码器结构:利用堆叠的编码器和解码器层提取特征并进行分类。
- 输出层:通过softmax层输出分类概率。
5.1. 输入嵌入层(Input Embedding Layer)
输入嵌入层将原始的网络流量特征映射到一个固定维度的向量空间中。
self.embedding = nn.Linear(input_dim, model_dim)
- 公式:
E = X W e + b e E = XW_e + b_e E=XWe+be
其中,( X ) 是输入特征矩阵,( W_e ) 和 ( b_e ) 分别是嵌入层的权重矩阵和偏置向量,( E ) 是嵌入向量。
5.2. 位置编码层(Positional Encoding Layer)
位置编码层通过添加位置编码向量来保留序列信息。位置编码向量由正弦和余弦函数生成。
class PositionalEncoding(nn.Module):def __init__(self, d_model, max_len=5000):super(PositionalEncoding, self).__init__()pe = torch.zeros(max_len, d_model)position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-torch.log(torch.tensor(10000.0)) / d_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0).transpose(0, 1)self.register_buffer('pe', pe)def forward(self, x):return x + self.pe[:x.size(0), :]
- 公式:
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i / d m o d e l ) PE_{(pos, 2i)} = \sin \left( \frac{pos}{10000^{2i/d_{model}}} \right) PE(pos,2i)=sin(100002i/dmodelpos)
P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i / d m o d e l ) PE_{(pos, 2i+1)} = \cos \left( \frac{pos}{10000^{2i/d_{model}}} \right) PE(pos,2i+1)=cos(100002i/dmodelpos)
其中,( pos ) 是位置,( i ) 是维度索引。
max_len=5000中的5000表示序列的最大长度。在Transformer模型中,位置编码用于为输入序列中的每个位置添加一个向量表示其位置信息。这个向量是根据位置编码函数生成的,函数中的参数包括位置和维度索引。
位置编码的作用是为模型提供序列中各个位置的相对位置信息。这对于理解序列中的顺序和间隔是至关重要的。在自注意力机制中,序列中不同位置之间的关系是由位置编码来表示的,而不是像循环神经网络或卷积神经网络那样,通过固定的滑动窗口或循环结构来捕获序列中的顺序信息。
为什么将max_len设置为5000呢?这主要是为了应对在训练和推理过程中可能遇到的最大序列长度。通常情况下,我们会将max_len设置为训练数据集中序列的最大长度,以确保所有序列都能够被正确编码。在实际应用中,如果序列长度超过了max_len,可以通过截断或其他方法进行处理。
下面举一个例子来说明位置编码的作用:
假设有一个长度为4的序列:[ a, b, c, d ],并且我们使用一个4维的位置编码。
位置编码的生成过程如下:
- 对于每个位置 ( pos ),生成一个长度为4的位置编码向量 ( \text{PE}_{(pos)} )。
- 对于每个维度索引 ( i ),根据位置 ( pos ) 计算该维度的位置编码值。
例如,对于维度索引 ( i = 0 ) 和位置 ( pos = 1 ):
PE ( 1 , 0 ) = sin ( 1 1000 0 0 / 4 ) = sin ( 1 ) \text{PE}_{(1, 0)} = \sin \left( \frac{1}{10000^{0/4}} \right) = \sin(1) PE(1,0)=sin(100000/41)=sin(1)
PE ( 1 , 1 ) = cos ( 1 1000 0 0 / 4 ) = cos ( 1 ) \text{PE}_{(1, 1)} = \cos \left( \frac{1}{10000^{0/4}} \right) = \cos(1) PE(1,1)=cos(100000/41)=cos(1)
PE ( 1 , 2 ) = sin ( 1 1000 0 2 / 4 ) = sin ( 1 / 100 ) \text{PE}_{(1, 2)} = \sin \left( \frac{1}{10000^{2/4}} \right) = \sin(1/100) PE(1,2)=sin(100002/41)=sin(1/100)
PE ( 1 , 3 ) = cos ( 1 1000 0 2 / 4 ) = cos ( 1 / 100 ) \text{PE}_{(1, 3)} = \cos \left( \frac{1}{10000^{2/4}} \right) = \cos(1/100) PE(1,3)=cos(100002/41)=cos(1/100)
这样,每个位置都被赋予了一个唯一的位置编码向量,这些向量将会在模型的训练和推理过程中与输入的特征向量相结合,从而帮助模型更好地理解序列中各个位置的相对关系。
5.3. Transformer编码器层(Transformer Encoder Layer)
Transformer编码器层由多个自注意力层和前馈神经网络层堆叠而成。
encoder_layers = nn.TransformerEncoderLayer(d_model=model_dim, nhead=num_heads)
self.transformer_encoder = nn.TransformerEncoder(encoder_layers, num_layers)
-
自注意力机制公式:
Attention ( Q , K , V ) = softmax ( Q K T d k ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
其中,( Q, K, V ) 分别是查询矩阵、键矩阵和值矩阵,( d_k ) 是键的维度。 -
前馈神经网络公式:
FFN ( x ) = max ( 0 , x W 1 + b 1 ) W 2 + b 2 \text{FFN}(x) = \max(0, xW_1 + b_1)W_2 + b_2 FFN(x)=max(0,xW1+b1)W2+b2
其中,( W_1, W_2 ) 和 ( b_1, b_2 ) 是前馈神经网络的权重矩阵和偏置向量。
5.4. 解码层(Decoder Layer)(非Transformer的解码器)
解码层将编码器的输出转换为最终的分类结果。
self.decoder = nn.Linear(model_dim, num_classes)
- 公式:
y ^ = E W d + b d \hat{y} = EW_d + b_d y^=EWd+bd
其中,( E ) 是编码器的输出,( W_d ) 和 ( b_d ) 分别是解码层的权重矩阵和偏置向量,( \hat{y} ) 是预测的分类结果。
5.5. 模型的前向传播(Forward Pass)
def forward(self, x):x = self.embedding(x)x = self.pos_encoder(x)x = self.transformer_encoder(x)x = self.decoder(x)return x
- 嵌入层输出:
E = X W e + b e E = XW_e + b_e E=XWe+be - 位置编码输出:
E ′ = E + P E E' = E + PE E′=E+PE - 编码器输出:
Z = TransformerEncoder ( E ′ ) Z = \text{TransformerEncoder}(E') Z=TransformerEncoder(E′) - 解码层输出(非Transformer的解码器):
y ^ = Z W d + b d \hat{y} = ZW_d + b_d y^=ZWd+bd
5.6. 与BERT比较
模型bert-base-uncased的基本信息是:
12-layer, 768-hidden, 12-heads, 110M parameters.
对应到我们这里可以这么初始化模型:
model = TransformerModel(input_dim=128, model_dim=768, num_heads=12, num_layers=12, num_classes=10)
model_dim、num_layers太大,会导致训练很慢。
5.7. 多头注意力机制
多头注意力机制允许模型在处理输入序列时同时关注序列中不同位置的多个方面或特征,从而提高了模型的表征能力和泛化能力。每个注意力头都可以学习到不同的注意力权重,以便捕捉输入序列中不同位置的信息,并且可以并行计算,从而加快了模型的训练速度。
公式上,多头注意力机制可以表示为:
给定一个输入序列 (X),将其通过线性变换得到查询(Query)、键(Key)、值(Value)的表示:
Q = X W Q , K = X W K , V = X W V Q = XW^Q, \quad K = XW^K, \quad V = XW^V Q=XWQ,K=XWK,V=XWV
其中 (WQ)、(WK)、(W^V) 是学习的权重矩阵。
然后,计算每个头的注意力分数 (A_i):
A i = softmax ( Q i K i T d k ) A_i = \text{softmax}\left(\frac{Q_iK_i^T}{\sqrt{d_k}}\right) Ai=softmax(dkQiKiT)
其中 (Q_i)、(K_i) 是第 (i) 个头的查询和键,(d_k) 是查询和键的维度。
最后,将每个头的注意力权重与对应的值相乘并加权求和得到最终的输出:
MultiHead ( Q , K , V ) = Concat ( head 1 , head 2 , . . . , head h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, \text{head}_2, ..., \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,head2,...,headh)WO
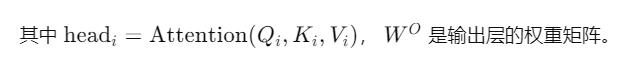
这样,通过多头注意力机制,模型可以同时关注输入序列的不同方面,更好地捕捉序列中的关键信息。
6 Transformer模型训练
训练Transformer模型,执行代码包的x09_0_trasformer训练.py,得到训练结果:
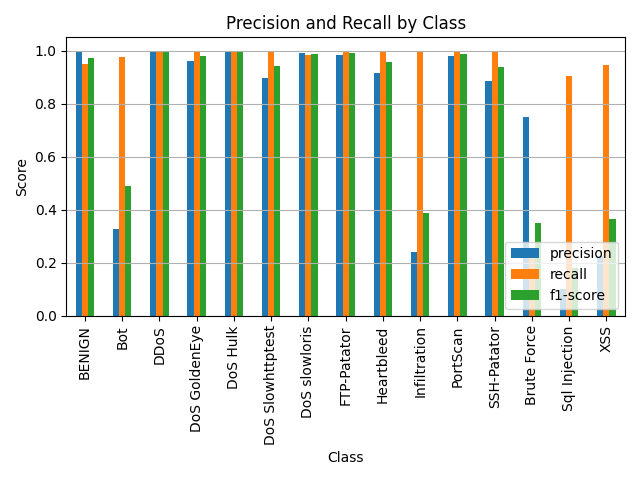
执行x10_0_trasformer训练_webattack算一类.py:
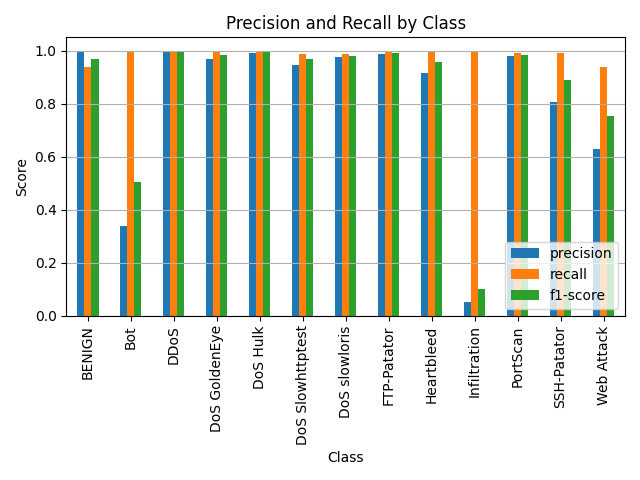
执行x11_0_trasformer训练_作为2个类别训练.py

全部代码
https://docs.qq.com/sheet/DUEdqZ2lmbmR6UVdU?tab=BB08J2
这篇关于【深度学习】Transformer分类器,CICIDS2017,入侵检测,随机森林、RFE、全连接神经网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






