森林专题

Python中的随机森林算法与实战
《Python中的随机森林算法与实战》本文详细介绍了随机森林算法,包括其原理、实现步骤、分类和回归案例,并讨论了其优点和缺点,通过面向对象编程实现了一个简单的随机森林模型,并应用于鸢尾花分类和波士顿房... 目录1、随机森林算法概述2、随机森林的原理3、实现步骤4、分类案例:使用随机森林预测鸢尾花品种4.1

【异常点检测 孤立森林算法】10分钟带你了解下孤立森林算法
孤立森林(isolation Forest)算法,2008年由刘飞、周志华等提出,算法不借助类似距离、密度等指标去描述样本与其他样本的差异,而是直接去刻画所谓的疏离程度(isolation),因此该算法简单、高效,在工业界应用较多。 用一个例子来说明孤立森林的思想:假设现在有一组一维数据(如下图),我们要对这组数据进行切分,目的是把点A和 B单独切分出来,先在最大,值和最小值之间随机选择一个值
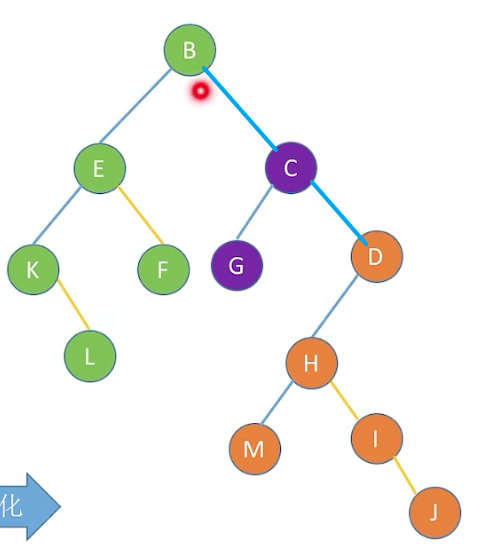
数据结构基础详解(C语言): 二叉树的遍历_线索二叉树_树的存储结构_树与森林详解
本文逻辑: 本文由二叉树的遍历起手,讲解了二叉树的三种遍历方式,以及如何构造一颗二叉树,并在此基础上,扩展了更好的二叉树-线索二叉树。树和森林的存储结构讲解中,重点就是将树与森林转换为二叉树,这样二叉树的手段就能使用到树与森林当中。最后,讲解了二叉树与森林的遍历。 文章目录 1.二叉树的遍历1.1 二叉树的前,中,后序遍历1.2 二叉树的层次遍历1.3构造二叉树 2.线索二叉树2.1

随机森林的知识博客:原理与应用
随机森林(Random Forest)是一种基于决策树的集成学习算法,它通过组合多棵决策树的预测结果来提升模型的准确性和稳健性。随机森林具有强大的分类和回归能力,广泛应用于各种机器学习任务。本文将详细介绍随机森林的原理、构建方法及其在实际中的应用。 1. 随机森林的原理 1.1 集成学习(Ensemble Learning) 在机器学习中,集成学习是一种通过结合多个模型的结果来提高预测性能的

【机器学习】梯度提升和随机森林的概念、两者在python中的实例以及梯度提升和随机森林的区别
引言 梯度提升(Gradient Boosting)是一种强大的机器学习技术,它通过迭代地训练决策树来最小化损失函数,以提高模型的预测性能 随机森林(Random Forest)是一种基于树的集成学习算法,它通过组合多个决策树来提高预测的准确性和稳定性 文章目录 引言一、梯度提升1.1 基本原理1.1.1 初始化模型1.1.2 迭代优化1.1.3 梯度计算1.1.4模型更新 1.2

mllib之随机森林与梯度提升树
随机森林和GBTs都是集成学习算法,它们通过集成多棵决策树来实现强分类器。 集成学习方法就是基于其他的机器学习算法,并把它们有效的组合起来的一种机器学习算法。组合产生的算法相比其中任何一种算法模型更强大、准确。 随机森林和梯度提升树(GBTs)。两者之间主要差别在于每棵树训练的顺序。 随机森林通过对数据随机采样来单独训练每一棵树。这种随机性也使得模型相对于单决策树更健壮,且不易在

机器学习项目——基于机器学习(决策树 随机森林 朴素贝叶斯 SVM KNN XGBoost)的帕金森脑电特征识别研究(代码/报告材料)
完整的论文代码见文章末尾 以下为核心内容和部分结果 问题背景 帕金森病(Parkinson’s Disease, PD)是一种常见的神经退行性疾病,其主要特征是中枢神经系统的多巴胺能神经元逐渐丧失,导致患者出现运动障碍、震颤、僵硬等症状。然而,除运动症状外,帕金森病患者还常常伴有一系列非运动症状,其中睡眠障碍是最为显著的非运动症状之一。 脑电图(Electroencephalogram, E


5.sklearn-朴素贝叶斯算法、决策树、随机森林
文章目录 环境配置(必看)头文件引用1.朴素贝叶斯算法代码运行结果优缺点 2.决策树代码运行结果决策树可视化图片优缺点 3.随机森林代码RandomForestClassifier()运行结果总结 环境配置(必看) Anaconda-创建虚拟环境的手把手教程相关环境配置看此篇文章,本专栏深度学习相关的版本和配置,均按照此篇文章进行安装。 头文件引用 from sklear

Spark Mllib之集成算法:梯度提升树和随机森林
微信公众号:数据挖掘与分析学习 集成算法是将其他基础模型进行组合的一中算法。spark.mllib支持两种主要的集成算法:GradientBoostedTrees和RandomForest。 两者都使用决策树作为基础模型。 1.梯度提升树和随机森林 Gradient-Boosted Trees(GBTs)和Random Forest都是用于学习树集成的算法,但训练过程是不同的。 有几个

6.0 —随机森林原理(RF)和集成学习(Bagging和Pasting)
我们这边先介绍集成学习 什么是集成学习 我们已经学习了很多机器学习的算法。比如KNN,SVM.逻辑回归,线性回归,贝叶斯,神经网络等等,而我们的集成学习就是针对某一个问题,我们使用多个我们已经学过的算法,每个算法都会得出一个结果。然后采用投票的方法,少数服从多数,得出最终结果。这就是voting classifier 我们看下代码: 我们手写的集成学习方法,和scikit-learn

决策树和随机森林介绍
hello大家好,俺是没事爱瞎捣鼓又分享欲爆棚的叶同学!!!今天我来给大家介绍一下决策树与随机森林,说起随机森林俺还有件很久远的丑事,之前有关课的结课作业就是用模型训练并预测,那时我比较天真,想着先玩,然后随便在网上找个代码糊弄糊弄就行了,然后到答辩那天我站在讲台上说出:“本次预测用了随机森林”,讲的绘声绘色,那自信的差点把自己都骗了哈哈哈哈,然后俺讲完,老师点评时,望着手中的报告笑着说了句:“你
基于Python的机器学习系列(14):随机森林(Random Forests)
简介 在上一节中,我们探讨了Bagging方法,并了解到通过构建多个树模型来减少方差是有效的。然而,Bagging方法中树与树之间仍然可能存在一定的相关性,降低了方差减少的效果。为了解决这个问题,我们引入了随机森林(Random Forests),这是一种基于Bagging的增强技术,通过在每个树的每个分割点上随机选择特征来进一步减少树之间的相关性。 1. Out of Bag

孤立森林 Isolation Forest 论文翻译(上)
README 自己翻译的+参考有道,基本是手打的可能会有很多小问题。 括号里的斜体单词是我觉得没翻译出那种味道的或有点拿不准的或翻译出来比较奇怪的地方,尤其是profile、swamping和masking这三个词不知道怎样更准确。 欢迎指正和讨论,需要Word版可以留言。 孤立森林 摘要 大多数现有的基于模型的异常检测算法构建了一个正常实例的特征轮廓(profil

森林防火隔离带开辟车的特点_鼎跃安全
在森林火灾发生时,防火隔离带为救援人员和物资提供了一条通往火灾现场的快速通道,使得救援工作能够更加迅速和有效地展开。隔离带的设置不仅简化了灭火作业,还显著提高了效率。借助隔离带,消防人员可以在相对安全的环境中开展灭火行动,而无需担心火势的蔓延,从而大大提升了灭火效果。 森林隔离带开辟车是一种集成多种功能的重型机械设备,专门设计用于在森林、草原和灌木丛中快速开辟防火隔离带。 隔离带森林开辟车

随机森林算法的简单总结及python实现
随机森林是数据挖掘中非常常用的分类预测算法,以分类或回归的决策树为基分类器。算法的一些基本要点: *对大小为m的数据集进行样本量同样为m的有放回抽样; *对K个特征进行随机抽样,形成特征的子集,样本量的确定方法可以有平方根、自然对数等; *每棵树完全生成,不进行剪枝; *每个样本的预测结果由每棵树的预测投票生成(回归的时候,即
随机森林 python
转自:http://blog.csdn.net/lulei1217/article/details/49583287 这几天一直在看随机森林。可以说遇到任何一个有关预测的问题。都可以首先随机森林来进行预测,同时得到的结果也不会太差。在这篇文章里我首先会向大家推荐几篇写的比较好的博客。接着会将我觉得比较好的例子使用python+scikit-learn包来实现出来。 首先推荐的就是:随机森林入

代谢组数据分析(十九):随机森林构建代谢组预后模型
介绍 建立胃癌(GC)预后模型时,从队列3中的181名患者中,使用右删失结果数据进行了随机分层抽样,分为训练数据集(n = 121)和测试数据集(n = 60)。训练了一个包含1000棵树的随机生存森林(RSF)模型,根据它们基于排列的特征重要性来选择突出的特征。通过再次训练随机生存模型,并选取28种代谢物,建立了显示出色预测能力(AUROC = 0.832,95% CI:0.697-0.9

25版王道数据结构课后习题详细分析 第五章 树与二叉树 5.4 树、森林
一、单项选择题 ———————————————————— ———————————————————— 解析: 正确答案: ———————————————————— ———————————————————— 解析: 正确答案: ———————————————————— ———————————————————— 解析: 正确答案: ———————————————————— —

机器学习:随机森林决策树学习算法及代码实现
1、概念 随机森林(Random Forest)是一种集成学习方法,它通过构建多个决策树来进行分类或回归预测。随机森林的核心原理是“集思广益”,即通过组合多个弱学习器(决策树)的预测结果来提高整体模型的准确性和健壮性。 2、集成学习(Ensemble Learning): 集成学习是一种机器学习方法,它结合多个学习器的预测结果来提高整体模型的性能。随机森林是集
探索C#的随机森林:内置随机数生成器的深度指南
标题:探索C#的随机森林:内置随机数生成器的深度指南 在编程世界中,随机数生成器是一种常用工具,它在模拟、游戏开发、加密、科学计算等领域发挥着重要作用。C#提供了强大的内置随机数生成器,使得生成随机数变得简单而高效。本文将深入探讨如何在C#中使用内置的随机数生成器,并通过实际代码示例展示其应用。 1. 随机数生成器简介 随机数生成器用于生成不可预测的数字序列。在C#中,System.Rand

【软考】树、森林和二叉树之间的相互转换
目录 1. 说明2. 树、森林转换为二叉树2.1 树转成二叉树2.1 森林转成二叉树 3. 二叉树转换为树和森林 1. 说明 1.树、森林和二叉树之间可以互相进行转换,即任何一个森林或一棵树可以对应表示为一棵叉树,而任何一棵二叉树也能对应到一个森林或一棵树上。 2. 树、森林转换为二叉树 2.1 树转成二叉树 1.用树的孩子兄弟表示法可导出树与二叉树的对应关系,在树
【机器学习】朴素贝叶斯 决策树 随机森林 线性回归
机器学习分类算法 朴素贝叶斯 条件概率公式 P ( A ∣ B ) = P ( A ∩ B ) P ( B ) P(A \mid B)=\frac{P(A \cap B)}{P(B)} P(A∣B)=P(B)P(A∩B) 在B条件发生的情况下,A发生的概率。 事件 A 发生的概率定义为事件 A 发生的情况数除以所有可能情况的总数。 P(A) =(事件 A 发生的情况数)/(所有可能情况
Google Earth Engine(GEE)——随机森林函数的监督分类使用案例分析
函数: ee.Classifier.smileRandomForest(numberOfTrees, variablesPerSplit, minLeafPopulation, bagFraction, maxNodes, seed) Creates an empty Random Forest classifier. Arguments: numberOfTrees (Integer):

机器学习 之 决策树与随机森林的实现
引言 随着互联网技术的发展,垃圾邮件过滤已成为一项重要的任务。机器学习技术,尤其是决策树和随机森林,在解决这类问题时表现出色。本文将介绍随机森林的基本概念,并通过一个具体的案例——筛选垃圾电子邮件——来展示随机森林的实际应用。 随机森林简介 随机森林是一种基于决策树的集成学习方法,它通过构建多个决策树并综合它们的预测结果来提高准确性和防止过拟合。随机森林的工作原理主要包括以下几个步骤: 自