本文主要是介绍文本检测 论文阅读笔记之 Pixel-Anchor: A Fast Oriented Scene Text Detector with Combined Networks,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Pixel-Anchor: A Fast Oriented Scene Text Detector with Combined Networks
摘要:最近语义分割和通用对象检测框架已被场景广泛采用文本检测任务,但是他们在实践中存在明显的缺陷。在本文中,我们提出一种新颖的端到端可训练的深度神经网络框架,名为Pixel-Anchor,它结合了语义分割和SSD在一个网络中,通过特征共享和anchor 水平的注意力机制来检测自然场景下多方向文字。为了处理文字大小以及宽高比的复杂变化,在语义分割部分我们结合FPN和ASPP操作作为我们的编码器 - 解码器结构,同时在SSD中我们提出一种新的自适应预测层。Pixel-Anchor检测场景文本除了有效的融合的NMS之外没有其它复杂的后处理步骤。提出的Pixel-Anchor进行了基准数据集测试。 Pixel-Anchor在文本定位精度和运行速度方面优于竞争方法。在ICDAR 2015数据集中,对于960×1728分辨率图像提出的算法在10 FPS时达到0.8768的F分数。
1.引言.(部分主要内容)
基于语义分割的方法具有较高的精确度,但由于小文本像素级特征太稀疏,因此召回率较低。 基于锚的方法具有高召回率因为锚级功能对文本不太敏感大小,但它遭受“锚定困境”问题(在2.2节中描述),并不是那么好像基于语义分割的方法那样获得高精度。而且,现有方法对于贯穿整个图像的较长中文文本行的检测表现不佳。
为了解决这些问题,提出的网络结构分为两部分named the pixel-based module and the anchor-based module。两个部分共享ResNet50提取的特征。在pixel-based module我们结合FPN和ASPP(atrous spacial pyramid pooling)操作作为我们的编码器 - 解码器结构,通过在1/16的特征图上引入ASPP,以较低的代价获得更大的感受野 ;在anchor-based module我们提出一种新的自适应预测层(APL)来检测尺寸变化大的文字;APL可以有效地调整网络的容纳领域,以适应文本形状。 为了检测在图像上运行的长文本行,我们进一步在APL中提出了 “long anchors” and “anchor density”。
2.相关工作
2.1 The pixel-based method
文本的笔画特征是显而易见的,所以它是易于从背景中分割文本像素。基于像素的方法通过文本像素特征直接预测文本边界框。在文本像素分割阶段,每个像素的文本/非文本分数由典型的编码器 - 解码器网络进行预测。 流行的基于像素的方法,像EAST 以及Pixel-Link , 和PSENet都用FPN作为基本结构。在FPN中,U形结构被构造以保持高空间分辨率和语义信息。
在文本边界框预测阶段,EAST预测在每个文本像素的文本边界框,然后进行NMS得到最终检测结果。对EAST进行修改,FOST获得了具有竞争力的结果。然而,因为它们处理的文本实例的最大大小与网络的接受域成正比,所以在检测非常长的文本时表现不佳。Pixel-Link 和 PSENet通过链接相邻文本像素来获取文本实例,这种方法不受感受野的限制,所以它可以检测很长的文本行。然而,这种方法方法后处理步骤是复杂的。易受复杂背景的干扰。
为了辨别非常接近文本实例,通常基于像素的方法使用“缩小多边形”来分配真实文本标签。由于真实标签已经缩小了很多,所以输入图像必须保持高分辨以检测小文本在时间上相应地提高成了成本。
2.2 The anchor-based method
anchor的概念起源于更快的Faster-RCNN,这是两步通用对象检测框架。首先,它用默认的boxs生成候选框(proposal);其次预测相对于anchors的偏移量而不是直接预测bounding boxs,这种策略在物体检测上得到普遍的应用像SSD,YOLO,SSD是在速度与精度之间的权衡,在自然场景下文字的检测得到广泛的应用。
Textboxes [13] 和 Textboxes++ [14] 修改SSD应用到自然场景文字检测,Textboxes 在三个方面优化了SSD以适应水平文字检测。1.增加anchor的长宽比以更好地适应文本框的形状。明确地,文本框将anchor的纵横比设置为1, 2, 3,5, 7,10;2.增加垂直方向上的anchor密度;3.使用1*5的卷积核而不是标准的3*3的卷积核,1*5的卷积核更加适用长文本的检测。而Textboxes++进一步扩大anchor的纵横比为1, 2, 3、5, 1/2, 1/3, 1/5;使用3×5卷积滤波器进行多方向文本的检测。Textboxes++虽然在公开数据集上获得了很好的效果,但它无法处理密集和大倾斜角度的文本。Textboxes++使用水平矩形作为锚,如果有两个邻近的大倾斜角度文本实例,那么很难确定哪个文本实例应该与anchor匹配。我们称为“Anchor Matching Dilemma”现象。为了克服上述问题,DMPNET〔22〕和RRPN(23)使用不同的四边形锚来检测多方向文本。然而,它极大地增加锚的数量。这种方法计算交叉点之间的两个任意的四边形时会很耗时,特别是当锚数量较大时。除了“锚匹配困境”之外,Textboxes++也遭受场景限制。1×5或3×5卷积滤波器的接收场不足以检测贯穿图像的文本行,即使锚的纵横比扩大到1:10,也不能匹配长宽比超过1:30的中文文行。
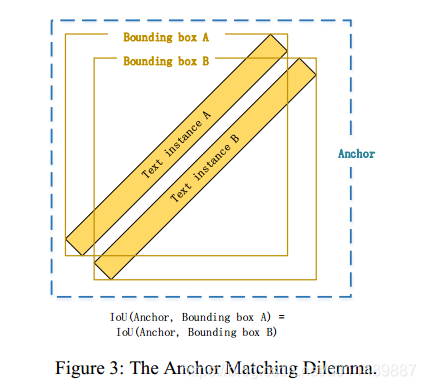
与基于像素的方法相比,基于锚的方法直接学习锚级文本实例的抽象特征,而不是像素级笔划特征。锚定水平抽象的特征必须面对更多的多样性,因此通常有更多的假阳性。基于锚的方法学习的锚级抽象特征对文本大小更具有鲁棒性,并有效地检测小文本。根据我们的实验,当使用小图像时基于锚的方法通常具有更高的召回分数。
3.本文方法
3.1 整体框架
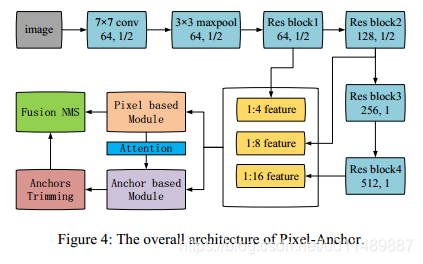
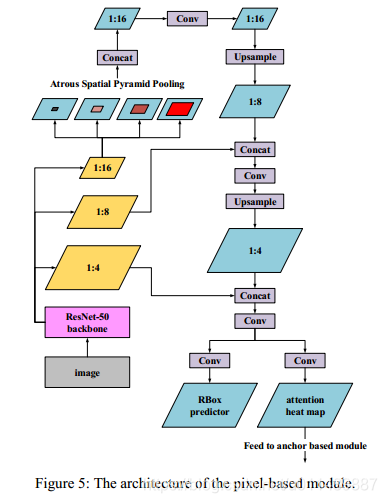
基本框架如图4所示,
我们将基于像素的方法和基于锚的方法结合起来通过特征共享和anchor 水平的注意力机制。RESNET-50作为特征提取器,分类之前输出步幅为32。
基于像素的模块的语义分割的任务,为了密集特征提取通过去除最后一个Res-block的步幅和应用空洞卷积(rate=2),将输出步幅设置为16。相应地,1/4、1/8和1/16特征图是从RESNET-50骨干网络提取并共享的特征图。将基于像素的模块中的分割热图输送到基于注意机制的锚级模块。在推理阶段,除了融合的NMS没有其它复杂的后处理操作。
3.2 The pixel-based module
大多数基于像素的文本检测器,如EAST和Pixel-Link采用FPN作为编码器解码器模块。为了增加我们网络的感受野,我们将FPN和ASPP操作结合起来作为我们的编码器解码器结构,用空洞率{ 3, 6, 9,12, 15, 18 }修改ASPP(原论文DeLPABV3+[ 7 ]中使用{ 6, 12, 18 })以获得更好的感受野。在解码阶段,编码特征首先2倍上采样(bilinearly upsampled)然后与相应的低级特征级联。解码的特征图同时保持高空间分辨率和语义信息。
与FPN模块相比,ASPP操作是更简单更有效。这是一种增大感受野额低成本操作,因为它的大部分操作是在1/16个特征图上进行的。所以网络具有较大的接受域,同时保持高效率。基于像素的模块的输出由两个模块组成部分:旋转盒子和注意力热图。这个旋转框(RBOX)预测器包含6个通道(类似EAST)。第一通道计算每一个像素为正文本的概率,以下4个通道预测其与文本边界的顶部、底部、左侧、右侧的距离,最后一个通道预测文本边界框的方向。注意热图包含指示每个像素作为文本的概率的一个通道,并将被送入the anchor-based module。对于RBOX预测器,为了区分非常接近文本实例,使用“缩小多边形”方法(类似FOTS)。仅收缩部分原文区域被认为是文本区域,而包围盒与收缩多边形之间的区域被忽略。对于注意热图不使用“缩小多边形”方法,所有原始文本区域被认为是正文本区域。
我们采用online hard example mining(OHEM)计算像素分类损失。对于每个图像,512 hard negative non-text pixels,512 random negative non-text pixels,所有正文本像素被选择用于分类培训。像素分类损失函数如下:
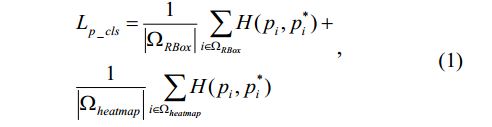
H(pi, pi*)是交叉熵损失。
我们还使用OHEM计算文本回归框,这一点与FOTS相同。我们从每张图片选择128 hard positive
text pixels 和 128 random positive text pixels 进行回归训练,回归框损失函数如下:
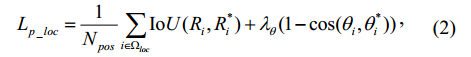
IoU(Ri, Ri*) 是第i个像素的预测回归框与真实回归框(between the predicted text bounding box Ri at the i-th pixel and its ground truth Ri*)的IoU 损失 ,第二项是方向损失,λθ是平衡IOU损失和角度损失的权重,在我们的实验中设定为10。因此pixel-based module损失如下所示:
![]()
αp是来平衡分类损失和位置损失,在我们的实验中设置为1。
3.3 the anchor-based module
此模块是我们修改SSD来检测尺寸变化大的文本,结构如下图:
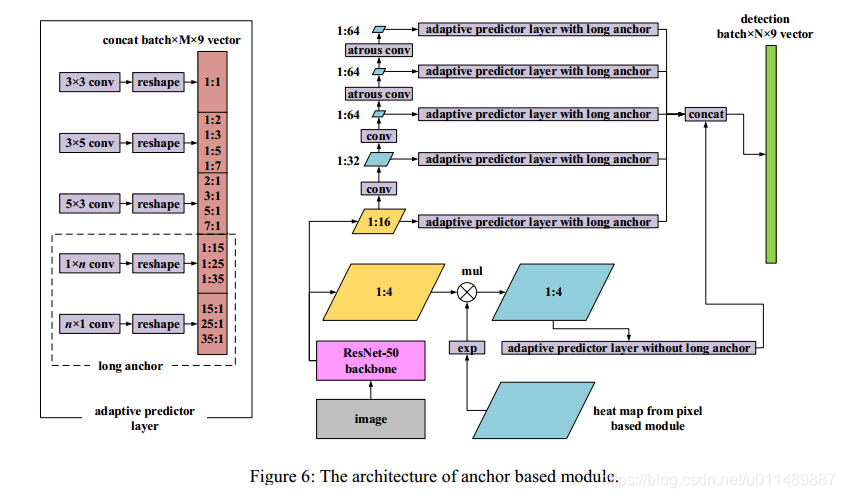
从Resnet-50基本骨架得到1/4和1/16的热力图是共享特征层。1/32、1/64、1/64、1/64特征图在1/16的特征图之后通过全卷积操作被附加。为了避免生成太小的特征图,最后两个特征图的分辨率保持不变,并且应用相应的空洞卷积(atrous convolution rate=2)。使用1/4的特征图代替在原始SSD中的1/8个特征图以增强网络检测小文本的能力。在feat1也就是来自于the pixel-based 模块热力图,注意力监督信息被应用。热力图(图6右下角蓝色方块,这个图从哪来?)先进行指数操作然后与feat1进行点乘。使用指数运算,将每个像素作为正文本的概率映射到范围[1,e],因此能够保留背景信息同时凸显检测信息。以这种方式减少了小文本的假阳性检测。
此外,我们提出了“自适应预测器层”(APL),附加到每个特征图以获得最终文本框。在APL中,anchor根据不同的纵横比被分组,每个组使用不同大小的滤波器。具体来说anchor被分为5组:a.正方形anchor 宽高比1:1,卷积核大小3*3;b.中等水平anchor, aspect ratios = {1:2, 1:3, 1:5,1:7},卷积核大小3*5;c.中等垂直anchor,aspect ratios = {2:1, 3:1, 5:1,7:1},卷积核大小5*3 d.较长水平anchor,aspect ratios = {1:15, 1:25,1:35},卷积核大小1*n ;e较长垂直anchor,aspect ratios = {15:1, 25:1, 35:1},卷积核大小n*1。对于长anchor,每一层的特征图的参数n是不同的,这取决于检测的文本行的长度。在feat1的APL中剔除长anchor,在feat2-feat6中,n被设置为{33, 29, 15, 15, 15}。通过使用APL,卷积核的感受野可以更好地拟合不同长宽比的文本。
为了检测密集文本,我们提出了“anchor density”,如下图所示:
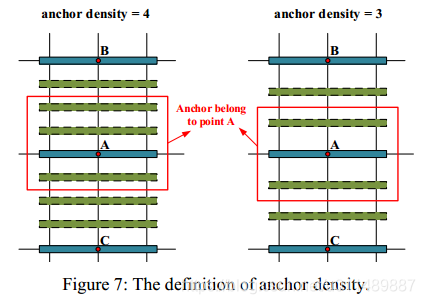
在Textboxes++中,anchors只在垂直方向复制一次,在我们的框架里,方形锚在水平方向上和垂直方向上重复。水平锚是在垂直方向上重复,垂直锚在水平方向上重复。anchor密度在每个特征层单独的被指定。在我们实验中,对于中等anchor,feat1-feat6,
anchor密度是{1, 2, 3, 4, 3, 2},对于长的anchor,feat2-feat6,anchor 密度是{4, 4, 6,4, 3}。
真实标签分配策略及基于锚的模块的损失函数与Textboxes ++类似。任意方向的文本是以四边形表示,四边形的最小包围矩形(MBRS)用于匹配锚。具体而言,锚定为文本四边形(正文本锚)IOU最大值大于0.5,如果最高IOU小于0.5则认为是背景。基于锚的模块的输出与Textboxes++相同,每个anchor对应输出9通道的预测向量,第一个通道是每个锚为正文本四边形的概率,剩下的8个通道是预测文本四边形坐标相对于锚的偏移量。
我们采用OHEM计算分类损失,并设置负例与正例之比为3:1,分类损失如下:
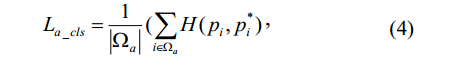
Ωa是被选择来分类训练的anchor集合(negative text anchors and positive text anchors),| • |操作表示anchor集合里positive anchor 的数量。
四边形的回归损失函数如下:

pos(Ωa)表示postive anchor,SL表示smooth L1函数。因此对于the anchor-based module,损失函数计算为:
![]()
αa在实验中设置为0.2。
3.4 训练
整个训练器使用ADAM优化器,损失函数如下:
![]()
αall是3.0来平衡两者之间的损失。
对于数据扩增,我们均匀地从原图采样640×640小图像块,batchsize为32。在ImageNet数据集上训练的模型,作为我们的预训练模型,同时使用SynthText 方法合成80w文本图像预训练模型,然后在基准数据集上进行训练。第一阶段学习率设置为0.0001第二阶段设置为0.0001.
这篇关于文本检测 论文阅读笔记之 Pixel-Anchor: A Fast Oriented Scene Text Detector with Combined Networks的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








