aqe专题

数据倾斜?Spark 3.0 AQE专治各种不服
Spark3.0已经发布半年之久,这次大版本的升级主要是集中在性能优化和文档丰富上,其中46%的优化都集中在Spark SQL上,SQL优化里最引人注意的非Adaptive Query Execution莫属了。 Adaptive Query Execution(AQE)是英特尔大数据技术团队和百度大数据基础架构部工程师在Spark 社区版本的基础上,改进并实现的自适应执行引擎。近些年来,S
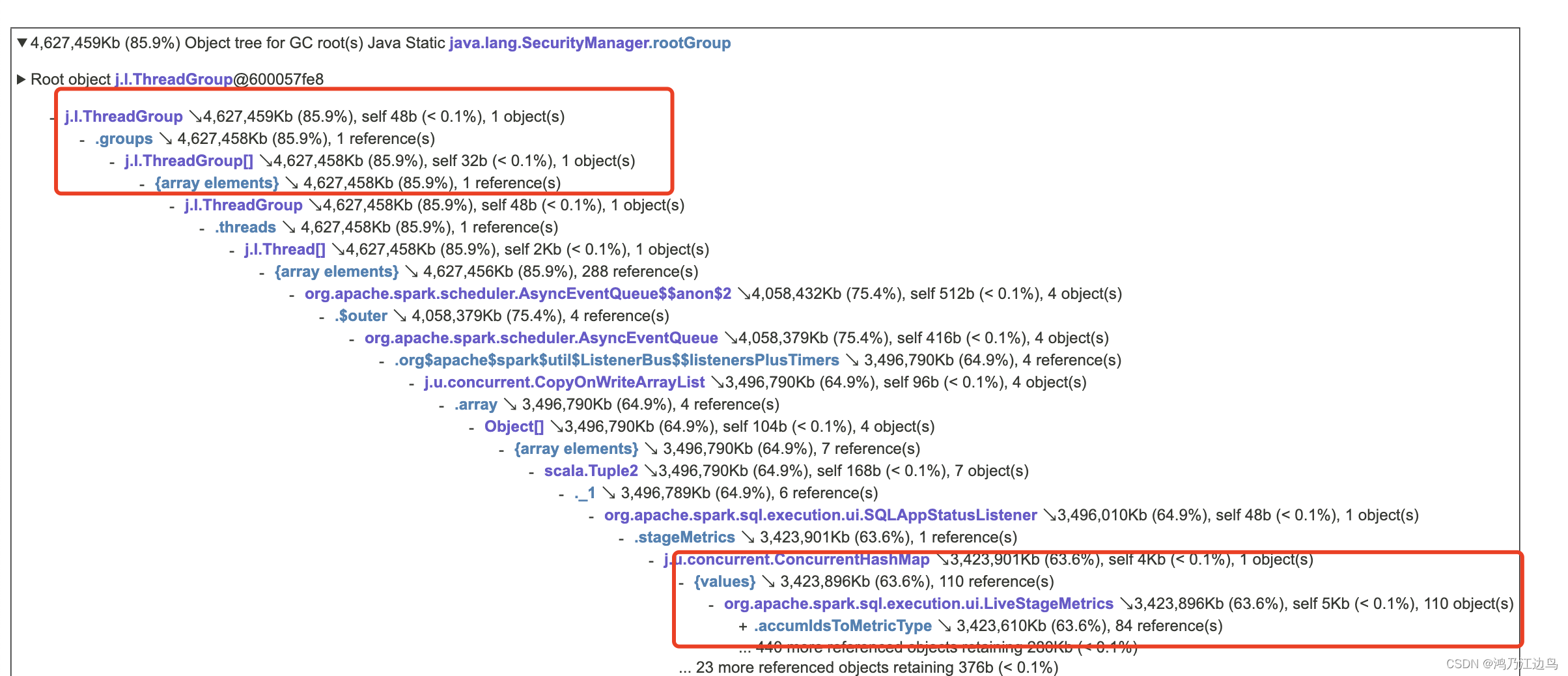
Spark AQE 导致的 Driver OOM问题
背景 最近在做Spark 3.1 升级 Spark 3.5的过程中,遇到了一批SQL在运行的过程中 Driver OOM的情况,排查到是AQE开启导致的问题,再次分析记录一下,顺便了解一下Spark中指标的事件处理情况 结论 SQLAppStatusListener 类在内存中存放着 一个整个SQL查询链的所有stage以及stage的指标信息,在AQE中 一个job会被拆分成很多job,甚
![[SPARK][SQL] 面试问题之Spark AQE新特性](https://img-blog.csdnimg.cn/img_convert/5e5d950fa49f5ea35c82bb73286a7769.webp?x-oss-process=image/format,png)
[SPARK][SQL] 面试问题之Spark AQE新特性
原文:https://zhuanlan.zhihu.com/p/533982903 SparkAQE是spark 3.0引入的一大重要功能,今天我们来聊一聊AQE的实现原理。 了解一个功能,先来了解其面临的问题。当涉及到大型集群中的复杂查询性能时,处理的并行度和正确Join策略选择已被证明是影响性能的关键因素。但Spark SQL在易用性和性能方面仍然存在极具挑战的问题: SparkSQL只能设
Spark3 新特性之AQE
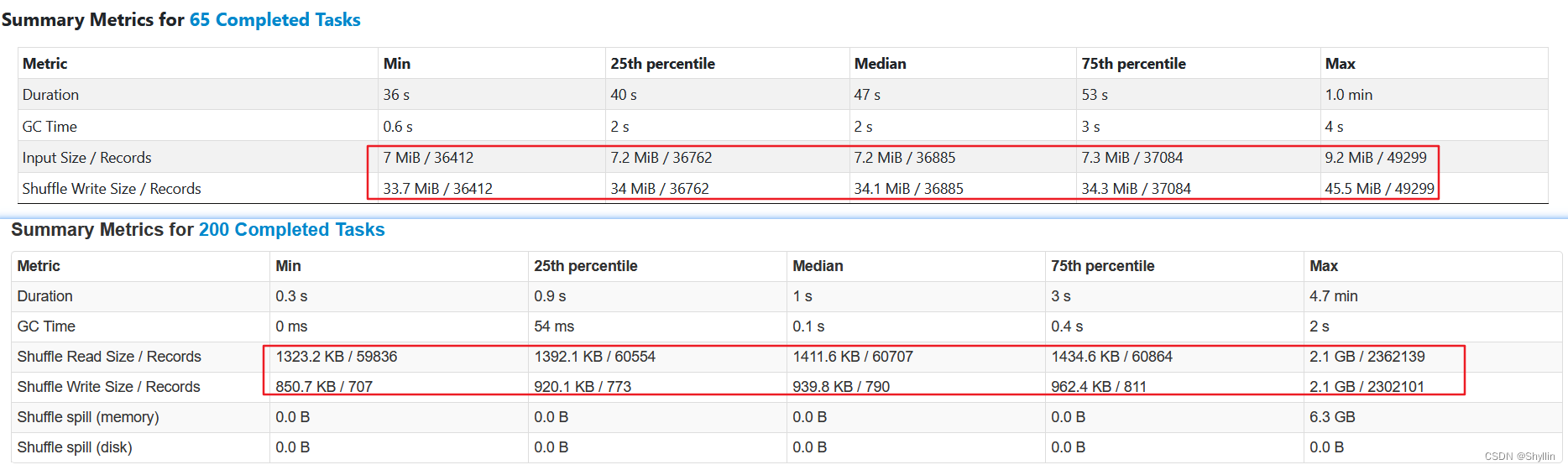
文章目录 Spark3 AQE一、 背景二、 Spark 为什么需要AQE? (Why)三、 AQE 到底是什么?(What)四、AQE怎么用?(How)4.1 自动分区合并4.2 自动数据倾斜处理4.3 Join 策略调整 五、对比验证5.1 执行耗时5.2 自动分区合并5.3 自动数据倾斜处理 六、结论 Spark3 AQE 一、 背景 Spark 2.x 在遇到有数据
Spark 3.0 - AQE浅析 (Adaptive Query Execution)
1、前言 近些年来,在对Spark SQL优化上,CBO是最成功的一个特性之一。 CBO会计算一些和业务数据相关的统计数据,来优化查询,例如行数、去重后的行数、空值、最大最小值等。 Spark根据这些数据,自动选择BHJ或者SMJ,对于多Join场景下的Cost-based Join Reorder(可以参考之前写的这篇文章),来达到优化执行计划的目的。 但是,由于这些统计数据是需要预先处理的,

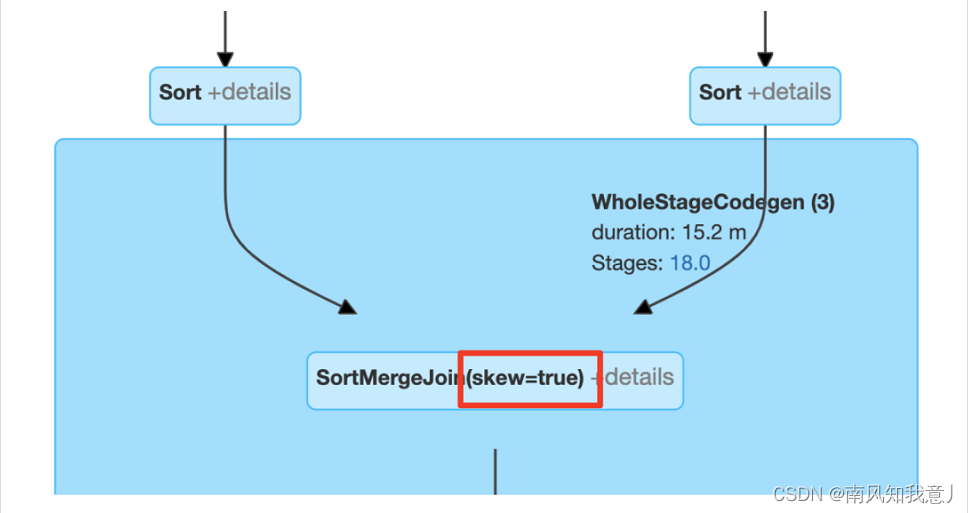
Spark AQE SkewedJoin 在字节跳动的实践和优化
动手点关注 干货不迷路 1. 概述 本文将首先介绍 Spark AQE SkewedJoin 的基本原理以及字节跳动在使用 AQE SkewedJoin 的实践中遇到的一些问题;其次介绍针对遇到的问题所做的相关优化和功能增强,以及相关优化在字节跳动的收益;此外,我们还将分享 SkewedJoin 的使用经验。 2. 背景 首先对 Spark AQE SkewedJoin 做一个简单的介绍。S

Spark SQL 的 AQE 机制
原文 本文翻译自 Spark SQL AQE 机制的原始 JIRA 和官方设计文档 《New Adaptive Query Execution in Spark SQL》 背景 SPARK-9850 在 Spark 中提出了自适应执行的基本思想。 在DAGScheduler中,添加了一个新的 API 来支持提交单个 Map Stage。 DAGScheduler请参考我的这篇博客——D
![[spark] spark SQL的AQE](https://img-blog.csdnimg.cn/img_convert/c9801549d7a944b38950e5ec3a576ce1.png)
[spark] spark SQL的AQE
参考https://zhuanlan.zhihu.com/p/533982903 https://cloud.tencent.com/developer/article/2143678 一、CBO (基于成本的优化) 例如在select(*)的时候去查询hive元数据返回结果。 CBO仅支持注册到Hive Metastore的数据表的优化,是关于表和列的优化,并且CBO是一种静态的优化策略。而A
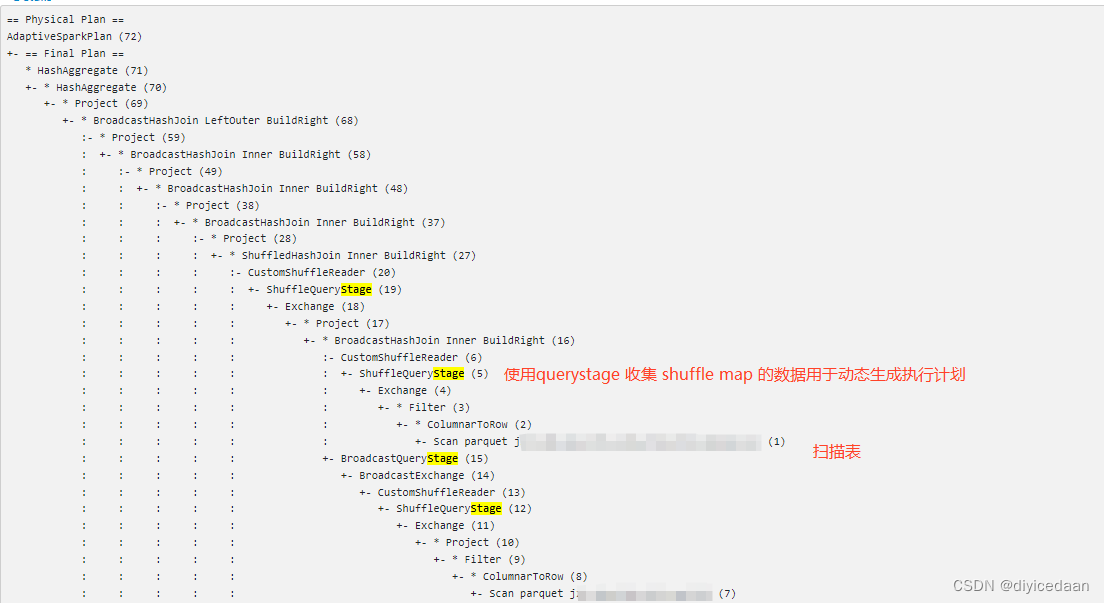
spark3.1.2 AQE功能使用
背景介绍 Spark2.2引入在RDBMS 世界中广泛使用多年基于成本的优化(CBO)。然而,在分布式系统中使用 CBO 是一个“极其复杂的问题”,在Spark中收集和维护一组准确和最新的统计数据是昂贵的。 Spark 3.0 在Cost基础之上增加了AQE,AQE可以收集任务在运行期间的统计信息,实现动态优化任务的执行计划。 AQE原理 AQE 是 Spark SQL 的一种动态
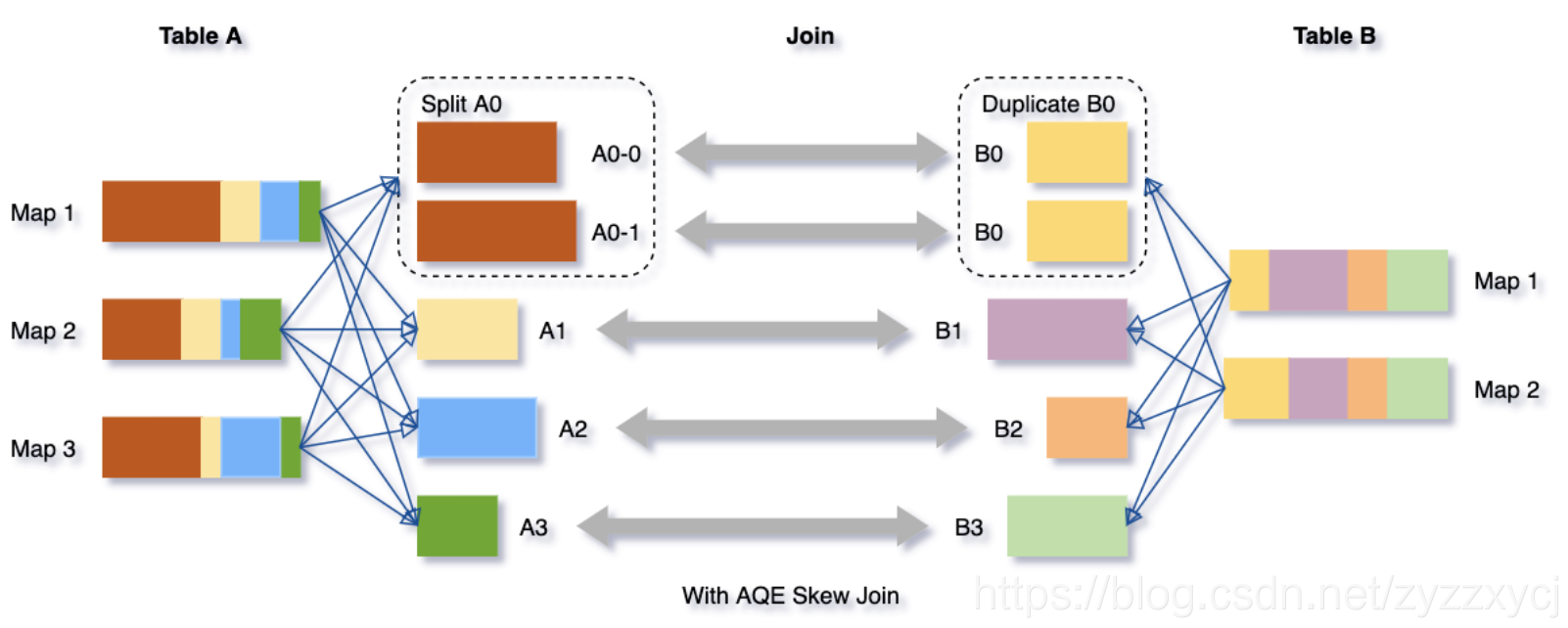
Spark 3.0 AQE 专治各种数据倾斜
1、前言 近些年来,在对Spark SQL优化上,CBO是最成功的一个特性之一。 CBO会计算一些和业务数据相关的统计数据,来优化查询,例如行数、去重后的行数、空值、最大最小值等。Spark根据这些数据,自动选择BHJ或者SMJ,对于多Join场景下的Cost-based Join Reorder,来达到优化执行计划的目的。但是,由于这些统计数据是需要预先处理的,会过时,所以我们在用过时的数据进
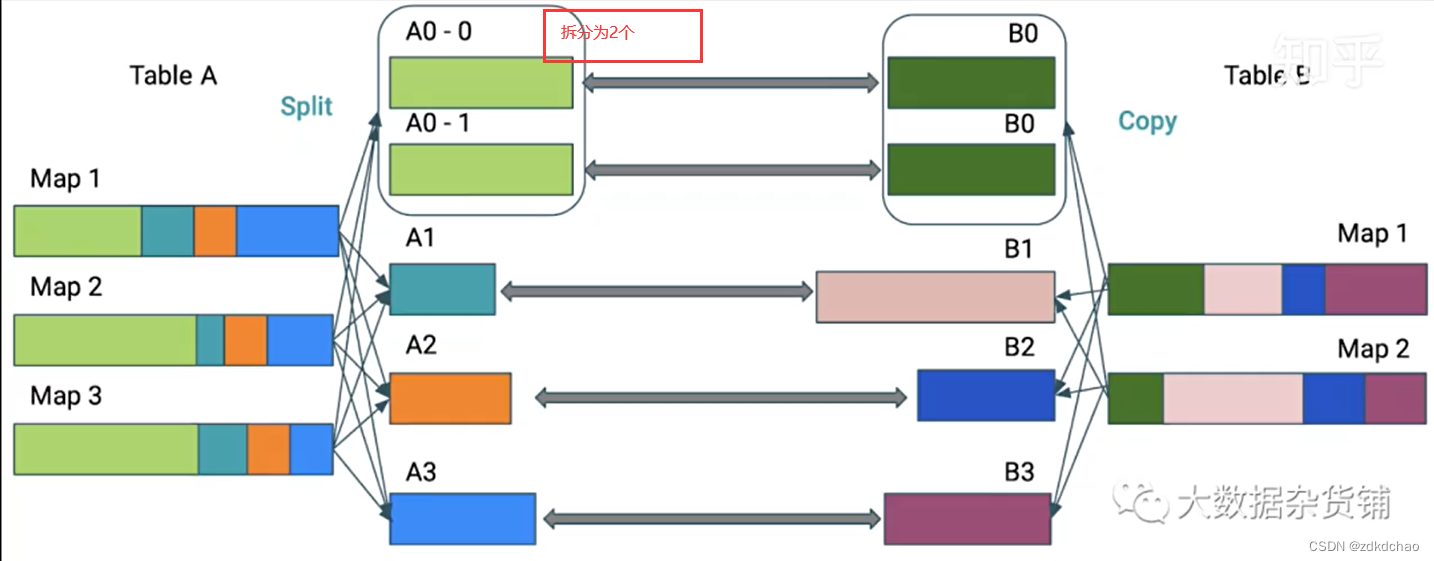
spark-3.0-AQE(Adaptive Query Execution)自适应查询
前置 AQE是一个运行时SQL优化框架,旨在解决由于优化器统计信息不足、不准确或过时而导致的查询执行计划的低效和缺乏灵活性的问题。 可以理解成是 Spark Catalyst 之上的一层,它可以在运行时修改 Spark plan,之前的物理执行计划不再是最终的计划,而是在每个query stage完成之后,动态的根据数据统计的情况,动态调整后续计划, 动态合并shuffle分区,自动调整SQL
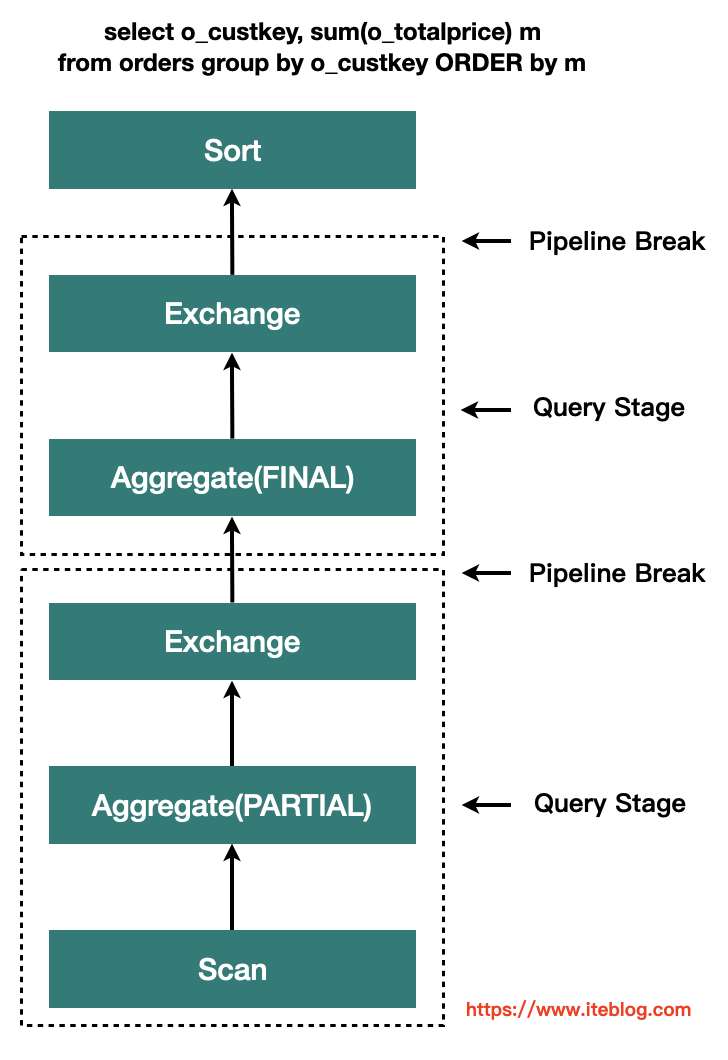
Spark 3.0自适应查询执行框架(AQE)
1. AQE设计原理 AQE 可以理解成是 Spark Catalyst 之上的一层,它可以在运行时修改 Spark plan。 AQE 完全基于精确的运行时统计信息进行优化,引入了 Query Stages 的概念 ,并且以 Query Stage 为粒度,进行运行时的优化,其工作原理如下所示: Query Stage 是由 Shu

Spark AQE DataSkew 处理过程中考虑的一些Case
Spark AQE 在 DataSkew 处理过程中,需要考虑一些边界条件,否则可能会引入一些额外的Shuffle。 EnsureRequirements 在开始今天的Topic之前,需要先回顾一下 EnsureRequirements, 熟悉的同学请跳过。 EnsureRequirements 是为了保证Spark 算子的数据输入要求,在算子之间引入Shuffle的核心工具。 outpu

阿里云 RemoteShuffleService 新功能:AQE和流控
阿里云 EMR 自 2020 年推出 Remote Shuffle Service(RSS)以来,帮助了诸多客户解决 Spark 作业的性能、稳定性问题,并使得存算分离架构得以实施。为了更方便大家使用和扩展,RSS 在2022年初开源,欢迎各路开发者共建。RSS 的整体架构请参考[1],本文将介绍 RSS 最新的两个重要功能:支持 Adaptive Query Execution(AQE),以

8.spark自适应查询-AQE之自适应调整Shuffle分区数量
目录 概述主要功能自适应调整Shuffle分区数量原理默认环境配置修改配置 结束 概述 自适应查询执行(AQE)是 Spark SQL中的一种优化技术,它利用运行时统计信息来选择最高效的查询执行计划,自Apache Spark 3.2.0以来默认启用该计划。从Spark 3.0开始,AQE有三个主要功如下 自适应查询AQE(Adaptive Query Execution)

行人reid,检索角度AQE Rerank,提升检索精度
采用该方法的必要性: 由于实际场景图像的复杂性,仅仅利用VLAD向量的相似并不能取得很好的精度,通常先利用VLAD向量从图像库中快速的检索出最相似的K幅图像,然后再进一步筛选。 图像检索(7):取得更好的检索结果 从图像检索角度提升最终距离排序结果,目前常用的有两种: AQE 扩展查询的方法有很多,简单有效的就是均值扩展查询(Average Query Expansion,AQE) 初始检索,
自适应查询执行AQE:在运行时加速SparkSQL
演讲嘉宾简介:王道远,阿里巴巴技术专家 以下内容根据演讲视频以及PPT整理而成。 点击链接观看精彩回放: https://developer.aliyun.com/live/43188 自适应查询执行AQE简介 关于自适应查询执行,在数据库领域早有充分研究。在Spark社区,最早在Spark 1.6版本就已经提出发展自适应执行(Adaptive Query Execution,下文简称AQE
Spark_调优_Spark3.0之SparkSQL_AQE( adaptive query execution)自适应查询_参数讲解
参考文章:Spark SQL 自适应执行优化引擎_DataFlow范式的博客-CSDN博客 在本篇文章中,笔者将给大家带来 Spark SQL 中关于自适应执行引擎(Spark Adaptive Execution)的内容。 参数配置基于社区版 :Performance Tuning - Spark 3.4.0 Documentation 在之前的文章中,笔者介绍过 Flink SQL,
8.spark自适应查询-AQE之自适应调整Shuffle分区数量
概述 自适应查询执行(AQE)是 Spark SQL中的一种优化技术,它利用运行时统计信息来选择最高效的查询执行计划,自Apache Spark 3.2.0以来默认启用该计划。从Spark 3.0开始,AQE有三个主要功如下 自适应查询AQE(Adaptive Query Execution) 自适应调整Shuffle分区数量 原理默认环境配置修改配置 动态调整Join策略动态优化倾斜的 Jo