本文主要是介绍spark3.1.2 AQE功能使用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景介绍
Spark2.2引入在RDBMS 世界中广泛使用多年基于成本的优化(CBO)。然而,在分布式系统中使用 CBO 是一个“极其复杂的问题”,在Spark中收集和维护一组准确和最新的统计数据是昂贵的。
Spark 3.0 在Cost基础之上增加了AQE,AQE可以收集任务在运行期间的统计信息,实现动态优化任务的执行计划。
AQE原理
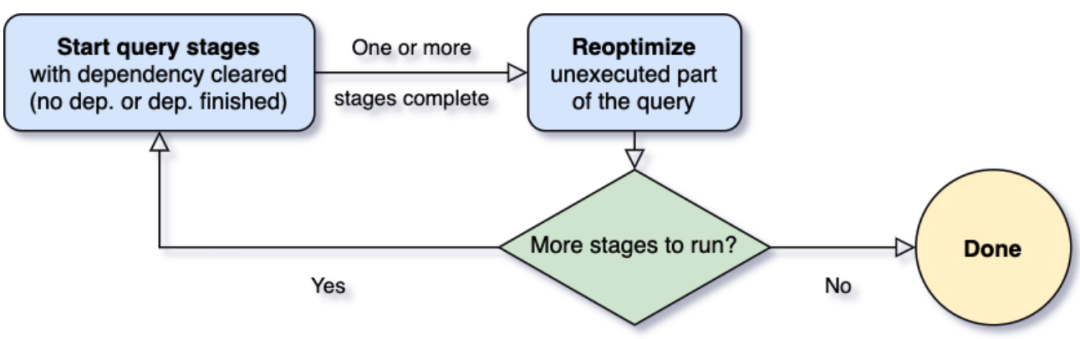
AQE 是 Spark SQL 的一种动态优化机制,在运行时,每当 Shuffle Map 阶段执行完毕,AQE 都会结合这个阶段的统计信息,基于既定的规则动态地调整、修正尚未执行的逻辑计划和物理计划,来完成对原始查询语句的运行时优化。
宏观上来看 AQE 优化执行计划的策略有两种:一是动态修改执行计划;二是动态生成 shuffle reader
AQE特性
自适应查询执行主要带来了下面这3点优化功能:
1.自适应调整Shuffle分区数量。
2.动态调整 Join 策略。
3.动态优化倾斜的 Join。
验证AQE功能
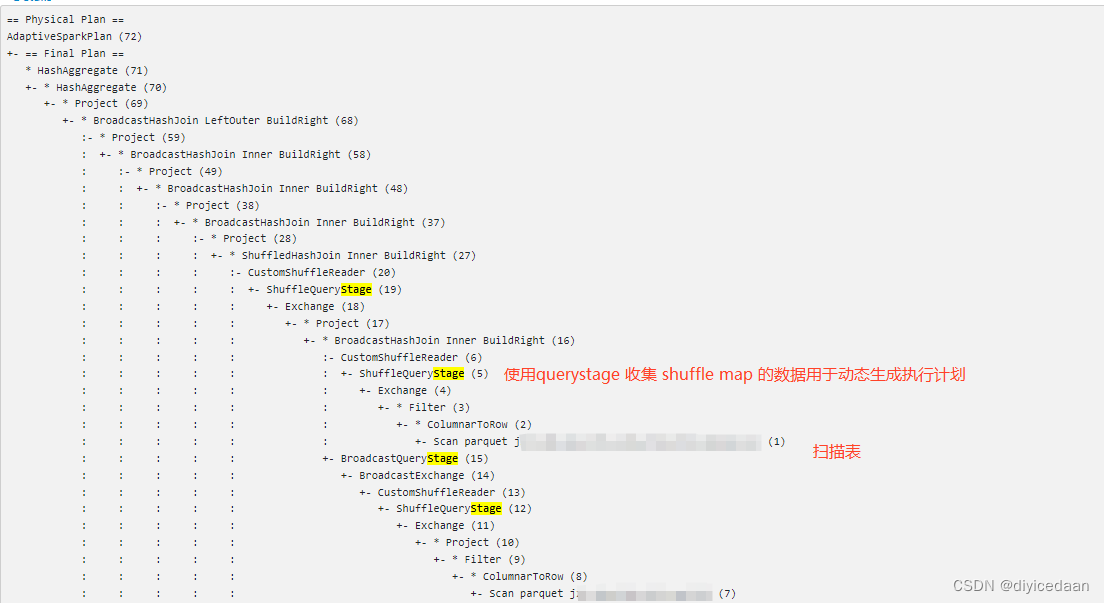
只有发生shuffle的情况下,AQE才会生效。
这篇关于spark3.1.2 AQE功能使用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




