本文主要是介绍[spark] spark SQL的AQE,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考https://zhuanlan.zhihu.com/p/533982903
https://cloud.tencent.com/developer/article/2143678
一、CBO (基于成本的优化)
例如在select(*)的时候去查询hive元数据返回结果。
CBO仅支持注册到Hive Metastore的数据表的优化,是关于表和列的优化,并且CBO是一种静态的优化策略。而AQE是是动态的优化。我们知道,每个Map Task都会输出两个文件:一个数据文件,一个索引文件。AQE是shuffle基于中间文件的统计:每个数据文件的大小、每个文件数据的条数、空文件数量与占比。
二、AQE=adaptive query executor(动态优化机制)
1.从前的处理方式
Spark SQL中,Shuffle分区数是通过spark.sql.shuffle.partition配置的,默认为200.它决定了reduce任务的数量,对查询性能影响很大。当我们配置spark.sql.shuffle.partition后会默认给所有的shuffle设置统一的分区数,这是不合适的,因为每个stage都有不同的输出数据大小。
2.什么是Spark SQL的AQE
AQE是Spark SQL的一种动态优机制,是Spark3才出现的。
总体思想是动态优化和修改物理执行计划,利用执行结束的上游Stage的统计信息(主要是数据量和记录数),来优化下游stage的物理执行计划。
3. AQE有三大特性:
1)自动分区合并
在shuffle过后,reduce task数据分布参差不齐。AQE将自动合并过小的数据分区。
2)join策略调整
如果某张表在过滤之后,尺寸小于广播变量阈值,这张表参与的数据关联会从shuffle sort merge join变为更高效的broadcast hash join。(和hive的小表join大表一个意思,大表在他的每个分区中都加载小表到内存中进行join,避免了shuffle)。
3)自动倾斜处理
在stage提交执行之前,根据上游stage的所有maptask的统计信息,计算得到下游每个reduce task的 shuffle输入,因此spark AQE能够自动发现发生数据倾斜的join,并且做出优化处理。
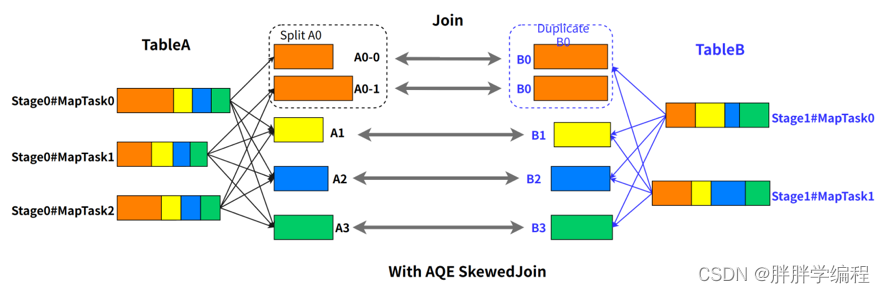
例如 A 表 inner join B 表,并且 A 表中第 0 个 partition(A0)是一个倾斜的 partition,正常情况下,A0 会和 B 表的第 0 个 partition(B0)发生 join,由于此时 A0 倾斜,task 0 就会成为长尾 task。
spark AQE在执行 A Join B 之前,通过上游 stage 的统计信息,发现 partition A0 明显超过平均值的数倍,即判断 A Join B 发生了数据倾斜,且倾斜分区为 partition A0。Spark AQE 会将 A0 的数据拆成 N 份,使用 N 个 task 去处理该 partition,每个 task 只读取若干个 MapTask 的 shuffle 输出文件,如下图所示,A0-0 只会读取 Stage0#MapTask0 中属于 A0 的数据。这 N 个 Task 然后都读取 B 表 partition 0 的数据做 join。这 N 个 task 执行的结果和 A 表的 A0 join B0 的结果是等价的。

这篇关于[spark] spark SQL的AQE的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









