本文主要是介绍Spark AQE SkewedJoin 在字节跳动的实践和优化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
动手点关注

干货不迷路
1. 概述
本文将首先介绍 Spark AQE SkewedJoin 的基本原理以及字节跳动在使用 AQE SkewedJoin 的实践中遇到的一些问题;其次介绍针对遇到的问题所做的相关优化和功能增强,以及相关优化在字节跳动的收益;此外,我们还将分享 SkewedJoin 的使用经验。
2. 背景
首先对 Spark AQE SkewedJoin 做一个简单的介绍。Spark Adaptive Query Execution, 简称 Spark AQE,总体思想是动态优化和修改 stage 的物理执行计划。利用执行结束的上游 stage 的统计信息(主要是数据量和记录数),来优化下游 stage 的物理执行计划。
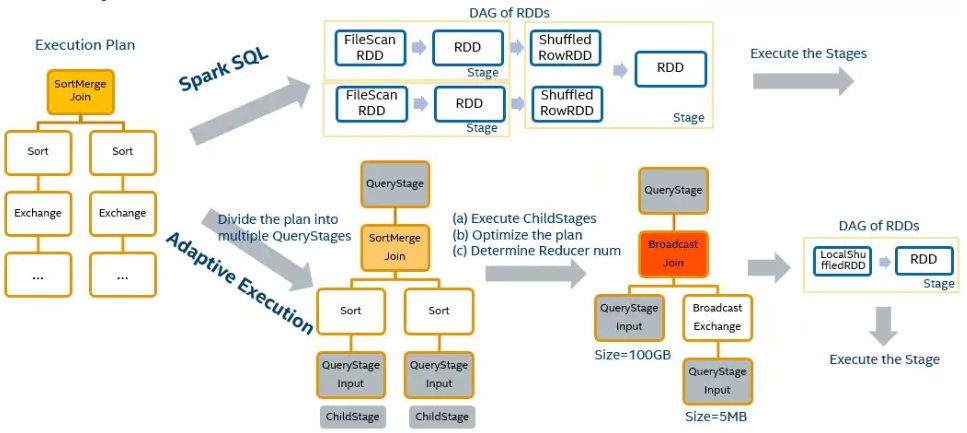
Spark AQE 能够在 stage 提交执行之前,根据上游 stage 的所有 MapTask 的统计信息,计算得到下游每个 ReduceTask 的 shuffle 输入,因此 Spark AQE 能够自动发现发生数据倾斜的 Join,并且做出优化处理,该功能就是 Spark AQE SkewedJoin。
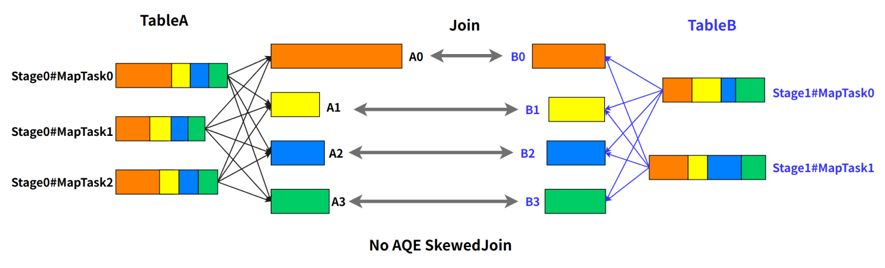
例如 A 表 inner join B 表,并且 A 表中第 0 个 partition(A0)是一个倾斜的 partition,正常情况下,A0 会和 B 表的第 0 个 partition(B0)发生 join,由于此时 A0 倾斜,task 0 就会成为长尾 task。
SkewedJoin 在执行 A Join B 之前,通过上游 stage 的统计信息,发现 partition A0 明显超过平均值的数倍,即判断 A Join B 发生了数据倾斜,且倾斜分区为 partition A0。Spark AQE 会将 A0 的数据拆成 N 份,使用 N 个 task 去处理该 partition,每个 task 只读取若干个 MapTask 的 shuffle 输出文件,如下图所示,A0-0 只会读取 Stage0#MapTask0 中属于 A0 的数据。这 N 个 Task 然后都读取 B 表 partition 0 的数据做 join。这 N 个 task 执行的结果和 A 表的 A0 join B0 的结果是等价的。
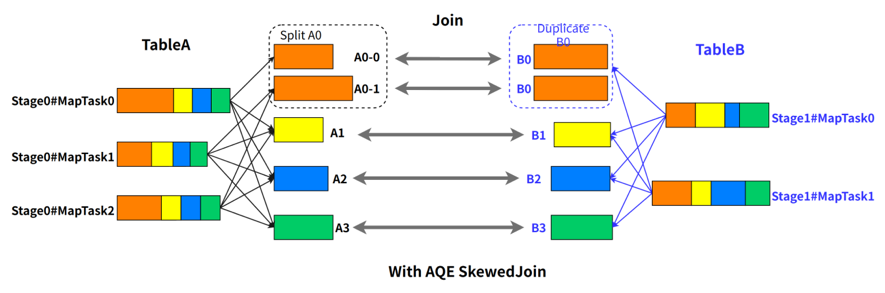
不难看出,在这样的处理中,B 表的 partition 0 会被读取 N 次,虽然这增加了一定的额外成本,但是通过 N 个任务处理倾斜数据带来的收益仍然大于这样的成本。
Spark 从3.0 版本开始支持了 AQE SkewedJoin 功能,但是我们在实践中发现了一些问题。
不准确的统计数据可能导致 Spark 无法识别数据倾斜。
切分不均匀导致优化处理效果不理想。
不支持复杂场景例如同一个字段发生连续 join。
我将在【优化增强】中详述这些问题以及我们的优化和解决方案。
3. 优化增强
3.1 提高数据倾斜的识别能力
由 Spark AQE 处理数据倾斜的原理不难发现,Spark AQE 识别倾斜以及切分数据倾斜的功能依赖于上游 Stage 的统计数据,统计数据越准确,倾斜的识别能力和处理能力就越高,直观表现就是倾斜数据被拆分的非常平均,拆分后的数据大小几乎和中位数一致,将长尾Task的影响降到最低。
MapStage 执行结束之后,每一个 MapTask 会生成统计结果 MapStatus,并将其发送给 Driver。MapStatus维护了一个 Array[Long],记录了该 MapTask 中属于下游每一个 ReduceTask 的数据大小。当 Driver 收集到了所有的 MapTask 的MapStatu之后,就能够计算得到每一个 ReduceTask 的输入数据量,以及分属于每一个上游 MapTask 的数据大小。根据每一个 ReduceTask 的数据大小,Spark AQE 能够判断出数据倾斜,并根据上游 MapTask 的统计信息,合理切分 Reducetask,尽可能保证切分的均匀性。
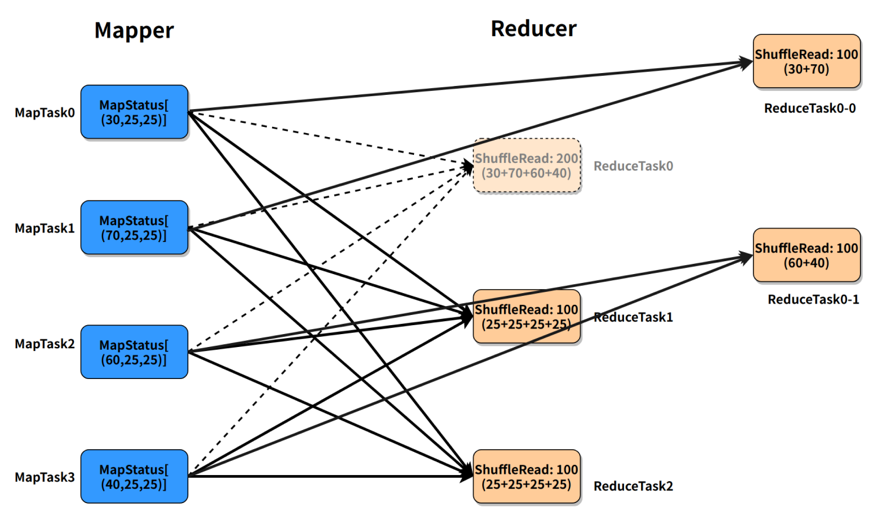
如下图描述,ReduceTask0 的 ShuffleRead(shuffle 过程中读取的数据量) 为 200,明显大于 ReduceTask1 和 ReduceTask2 的 100,发生了数据倾斜。我们可以将 ReduceTask0 拆成 2 份,ReduceTask0-0 读取 MapTask0 和 MapTask1 的数据,ReduceTask0-1 读取 MapTask2 和 MapTask3 的数据,拆分后的两个 task 的 ShuffleRead 均为 100。
我们可以看出,统计信息的大小的空间复杂度是 O(M*R),对于大任务而言,会占据大量的 Driver 内存,所以 Spark 原生做了限制,对于 MapTask,当下游 ReduceTask 个数大于某一阈值(spark.shuffle.minNumPartitionsToHighlyCompress,默认 2000),就会将MapStatus进行压缩,所有小于 spark.shuffle.accurateBlockThreshold(默认100M)的值都会被一个平均值所代替填充。
举个例子,下图是我们遇到的一个 SkewedJoin 没有生效的作业,从运行 metrics 来看,ShuffleRead 发生了很严重的倾斜,符合 SkewedJoin 生效的场景,但实际运行时并没有生效。
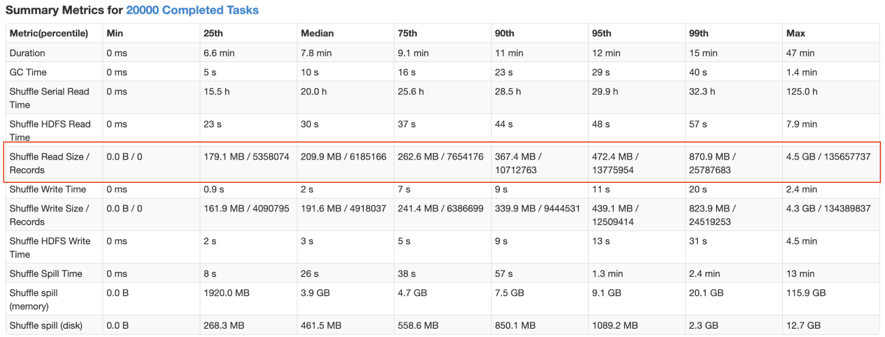
通过阅读日志,可以看到,Spark AQE 在运行时,获取的 join 两侧的 shuffle partitions 的中位数和最大值都是一样的,所以没有识别到任何的倾斜。这就是由于压缩后 MapStatus 的统计数据的不准确造成的。

我们在实践中,遇到很多大作业由于统计数据不准确,无法识别倾斜。而当我们尝试提高这一阈值之后,部分大作业由于 Driver 内存使用上涨而失败,为了解决这一问题,我们做了以下优化:
Driver 收到详细的 MapStatus之后,先将数据用于更新每个 ReduceTask 的累计输入数据,然后将 MapStatus压缩,这样就不会占用太多内存。此时,虽然压缩后的 MapStatus无法让我们获得 ReduceTask 准确的上游分布,但是能够获得准确的 ReduceTask 的输入数据总大小,这样我们就能够准确的识别发生倾斜的 ReduceTask。
上述优化增加了一次 MapStatus 的解压操作,而 MapStatus 的解压是一个比较耗CPU的操作,对于大作业可能出现 Driver CPU 被打满,无法处理 Executor 心跳导致作业失败的情况。对此,我们使用缓存保证Driver端在消费 MapStatus 时,每个 MapStatus 只会被解压一次,大大降低了优化带来的 Overhead。
通过上述优化,我们成功在线上将默认阈值从 2000 调整为 5000,保证了线上 96.6% 的 Spark 作业能够准确的识别数据倾斜(如果存在)。
3.2 提高倾斜数据的切分均匀程度
由于 HighlyCompressMapStatus 用平均值填充所有低于 spark.shuffle.accurateBlockThreshold 的值,每个 ReduceTask 通过压缩后的 MapStatus 累加计算得到的总数据大小和数据分布,就和实际差距很大。
举个简单的例子:我们得到 ReduceTask0 的实际总数据是 1G,而中位数是 100M,因此我们的期望是将 ReduceTask0 拆成 10 份,每一份是 100M。此时上游的 MapStage 一共有 100 个 MapTask,除了 MapTask0 中属于 ReduceTask0 的数据是 100M,其他 99 个 MapStak 的数据都是 10M。当我们将所有的 MapStatus 压缩之后,AQE 获取的 ReduceTask0 的上游分布,就是 MapTask0 有 100M (因为大块数据所以被保留),其他 99 个 MapTask 的数据都是 1M(在压缩时使用平均值填充)。这时,Spark AQE 按照 100M 的期望值来切分,只会切分成两个 ReduceTask:ReduceTask0-0(读取MapTask0)和 ReduceTask0-1(读取剩下99个MapTask)。
基于此,我们改进后的方法是利用精确的 ReduceTask 数据量来反推每个 MapperTask 对应的数据量,得到尽可能准确的数据分布。同样是刚才的例子,我们已知 ReduceTask0 的实际总数据是 1G,MapStatus 压缩的阈值是 100M,那么可以确定的是,MapTask0 关于 ReduceTask0 的数据 100M 是准确被保留的(因为大于等于阈值),而其他 99 个 MapTask 的数据都是不准确的。此时 AQE 就不会使用被压缩的数据,而是通过 1G 的总数据反推得到其他 99 个 MapTask 中属于 ReduceTask0 的数据是 10M,虽然同样是存在误差的平均值,但是相比压缩数据,通过准确的总量反推得到的平均值会更加准确。这个时候 Spark 按照 100M 的期望值来切分,就会切成 10 个 ReduceTask,符合我们的预期。
而在实际应用中,利用新方案,AQE SkewedJoin 切分倾斜数据更加平均,优化效果有明显的提升。
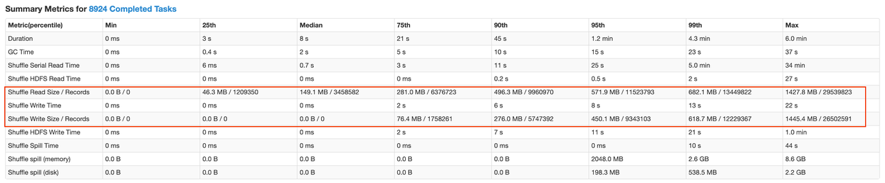
下图是某个倾斜处理效果不理想的作业,SkewedJoin 生效后,该 Stage ShuffleReadSize 的中位数和最大值分别为 4M 和 9.9G。
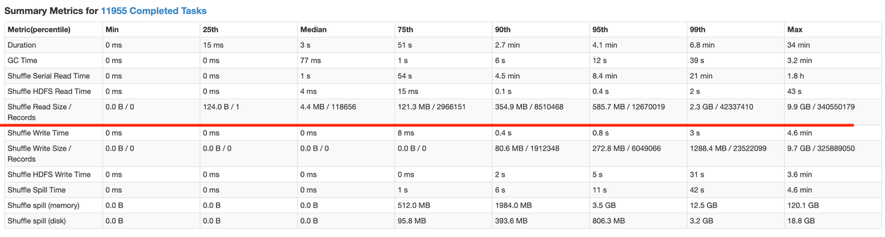
经过我们的优化后,该 Stage 的 ShuffleReadSize 的中位数和最大值分别为 149M 和 1427M,倾斜分区的切分更加均匀,该 Stage 的运行时间也由原来的 2h 降为 20m。
3.3 支持更多的场景
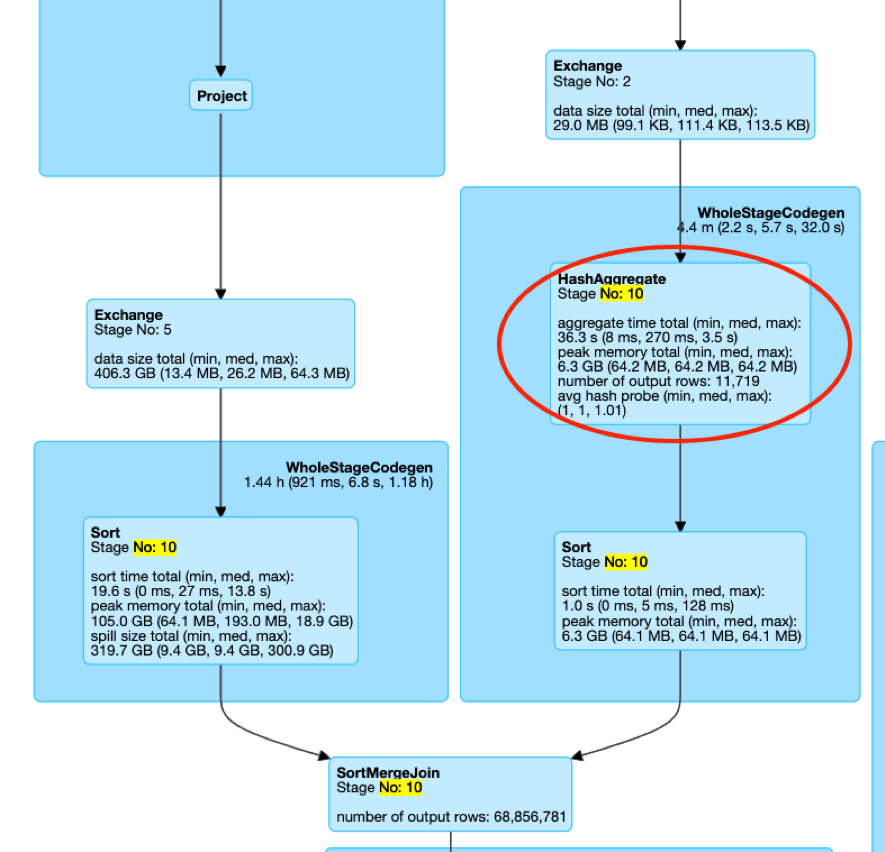
场景1:JoinWithAggOrWin
以下图为例,Stage10 虽然只有一个 SortMergeJoin,但是 join 的一边并不是 Sort+Exchange 的组合,而是存在 Aggregate 算子或者 Window 算子,因此不属于社区实现的范围内。
场景2:MultipleSkewedJoin
在用户的业务逻辑中,经常出现这样一种场景:一张表的主键需要连续的 join 多张表,这种场景体现在 Spark 的具体执行上,就是连续的 join 存在于同一个 Stage 当中。如下图所示 Stage21 中存在连续的多个 SortMergeJoin,而这种场景也是社区的实现无法优化的。
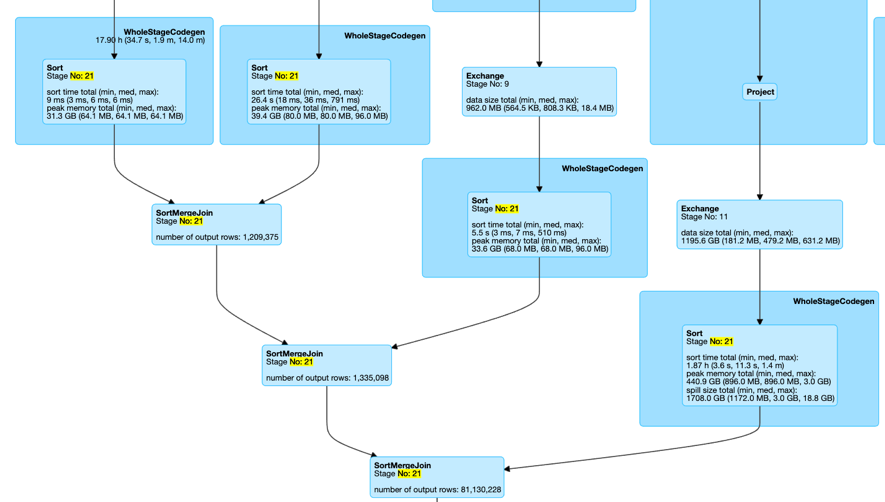
场景3:JoinWithUnion
Stage 中有 Union 算子,且 Union 的 children 中有 SMJ。
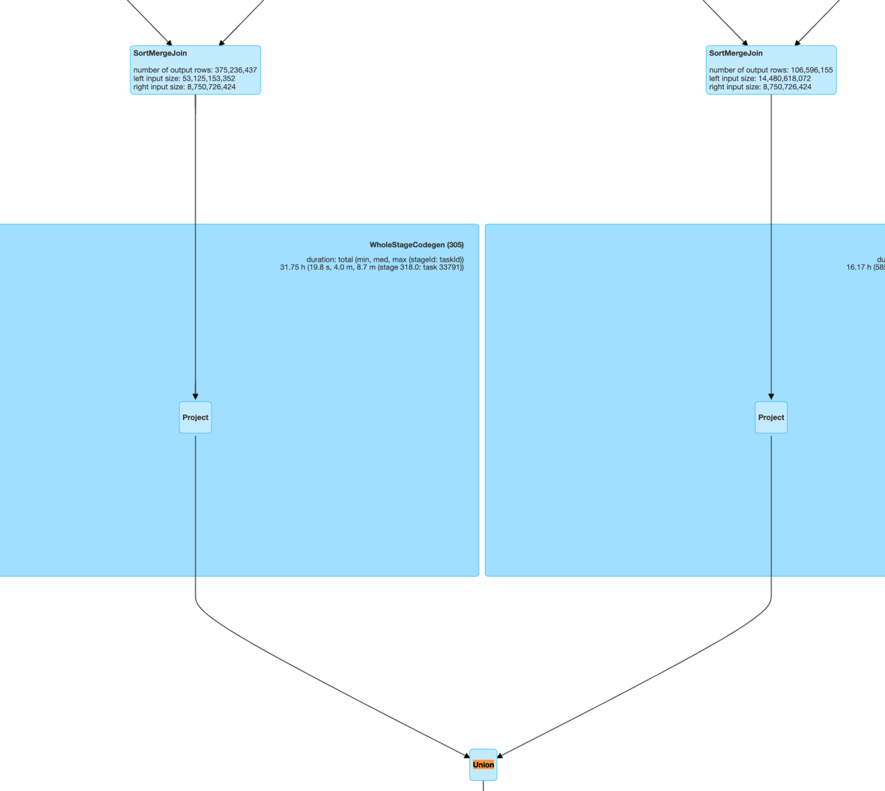
此外,我们还支持了 ShuffleHashJoin、 BucketJoin、MultipleJoinWithAggOrWin 等更多场景。
4. 字节的实践
上面介绍的 LAS 对 Spark AQE SkewedJoin 的优化功能在字节跳动内部已使用 1 年左右,截止 2022年8月,优化日均覆盖1.8万+ Spark 作业,优化命中作业平均性能提升 35% 左右,其中 30% 被优化的 Spark 作业所属于的场景是 LAS 自研支持的,大家可以通过火山引擎开通 LAS 服务并体验这些优化功能。
5. 用户指南
5.1 哪些场景 AQE SkewedJoin 不支持
AQE SkewedJoin 功能并不能处理所有发生数据倾斜的 Join,这是由它的实现逻辑所决定的。
第一,如果倾斜的分区的大部分数据来自于上游的同一个 Mapper,AQE SkewedJoin 无法处理,原因是 Spark 不支持 Reduce Task 只读取上游 Mapper 的一个 block 的部分数据。
第二,如果 Join 的发生倾斜的一侧存在 Agg 或者 Window 这类有指定 requiredChildDistribution 的算子,那么 SkewedJoin 优化无法处理,因为将分区切分会破坏 RDD 的 outputPartitioning,导致不再满足 requiredChildDistribution。
第三,对于 Outer/Semi Join,AQE SkewedJoin 是无法处理非 Outer/Semi 侧的数据倾斜。比如,对于 LeftOuter Join,SkewedJoin 无法处理右侧的数据倾斜。
第四,AQE 无法处理倾斜的 BroadcastHashJoin。
5.2 AQE SkewedJoin 优化效果不明显时的措施
如果遇到了符合应用场景但是 SkewedJoin 没有生效或者倾斜处理效果不理想的情况,有以下调优手段:
提高
spark.shuffle.minNumPartitionsToHighlyCompress,保证值大于等于 shuffle 并发(当开启 AQE 时,即为spark.sql.adaptive.coalescePartitions.initialPartitionNum)。
调小
spark.shuffle.accurateBlockThreshold,比如 4M。但是需要注意的是,这会增加 Driver 的内存消耗,需要同步增加 Driver 的 cpu 和内存。
降低
spark.sql.adaptive.skewJoin.skewedPartitionFactor,降低定义发生倾斜的阈值。
6. 总结
本文首先简单介绍了 Spark AQE 的基本思想以及 SkewedJoin 功能的原理,接着提出了我们在应用 SkewedJoin的过程中遇到的一些问题。针对这些问题,我们介绍了对 AQE SkewedJoin 做的优化和增强——提高统计的准确度;提高倾斜数据的切分均匀程度;支持了更多的场景。接着,本文介绍了 AQE SkewedJoin 在字节跳动的使用情况,包括日均优化覆盖作业和优化效果,其中30%被优化的 Spark 作业所属于的场景是字节自研支持的。最后分享了我们关于 AQE SkewedJoin 的用户指南:哪些场景 AQE SkewedJoin 不支持;当 AQE SkewedJoin 效果不明显时,可以采取哪些措施。
7. 附录A :本文涉及的关于 AQE SkewedJoin 优化的相关参数配置
| 参数配置名 | 默认值 | 参数意义 |
|---|---|---|
| spark.shuffle.minNumPartitionsToHighlyCompress | 2000 | 决定 Mapstatus 使用 HighlyCompressedMapStatus还是 CompressedMapStatus 的阈值,如果 huffle partition 大于该值,则使用 HighlyCompressedMapStatus。 |
| spark.shuffle.accurateBlockThreshold | 100M | HighlyCompressedMapStatus 中记录 shuffle blcok 准确大小的阈值,当 block 小于该值则用平均值代替。 |
| spark.sql.adaptive.skewJoin.skewedPartitionFactor | 10 | 如果一个 partition 大于该因子乘以分区大小的中位数,那么它就是倾斜的 partition。 |
8. 关于我们
火山引擎湖仓一体分析服务 LAS
支持构建开源Hadoop生态的企业级大数据分析系统,完全兼容开源,提供 Hadoop、Spark、Hive、Flink集成和管理,帮助用户轻松完成企业大数据平台的构建,降低运维门槛,快速形成大数据分析能力。点击阅读原文立即体验产品!
欢迎加入字节跳动数据平台官方群,进行数据技术交流、获取更多内容干货。

点击阅读原文,了解火山引擎湖仓一体分析服务LAS
这篇关于Spark AQE SkewedJoin 在字节跳动的实践和优化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


