本文主要是介绍阿里云 RemoteShuffleService 新功能:AQE和流控,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

阿里云 EMR 自 2020 年推出 Remote Shuffle Service(RSS)以来,帮助了诸多客户解决 Spark 作业的性能、稳定性问题,并使得存算分离架构得以实施。为了更方便大家使用和扩展,RSS 在2022年初开源,欢迎各路开发者共建。RSS 的整体架构请参考[1],本文将介绍 RSS 最新的两个重要功能:支持 Adaptive Query Execution(AQE),以及流控。
一 RSS支持AQE
1 AQE简介
自适应执行(Adaptive Query Execution, AQE)是 Spark3 的重要功能[2],通过收集运行时 Stats,来动态调整后续的执行计划,从而解决由于 Optimizer 无法准确预估Stats 导致生成的执行计划不够好的问题。AQE 主要有三个优化场景: Partition合并(Partition Coalescing), Join策略切换(Switch Join Strategy),以及倾斜 Join 优化(Optimize Skew Join)。这三个场景都对 Shuffle 框架的能力提出了新的需求。
Partition 合并
Partition 合并的目的是尽量让 reducer 处理的数据量适中且均匀,做法是首先 Mapper 按较多的 Partition 数目进行 Shuffle Write,AQE 框架统计每个 Partition 的Size,若连续多个 Partition 的数据量都比较小,则将这些 Partition 合并成一个,交由一个 Reducer 去处理。过程如下所示。
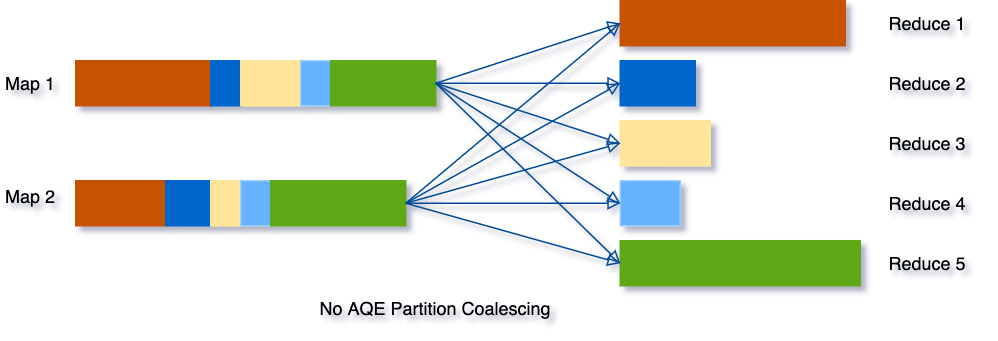

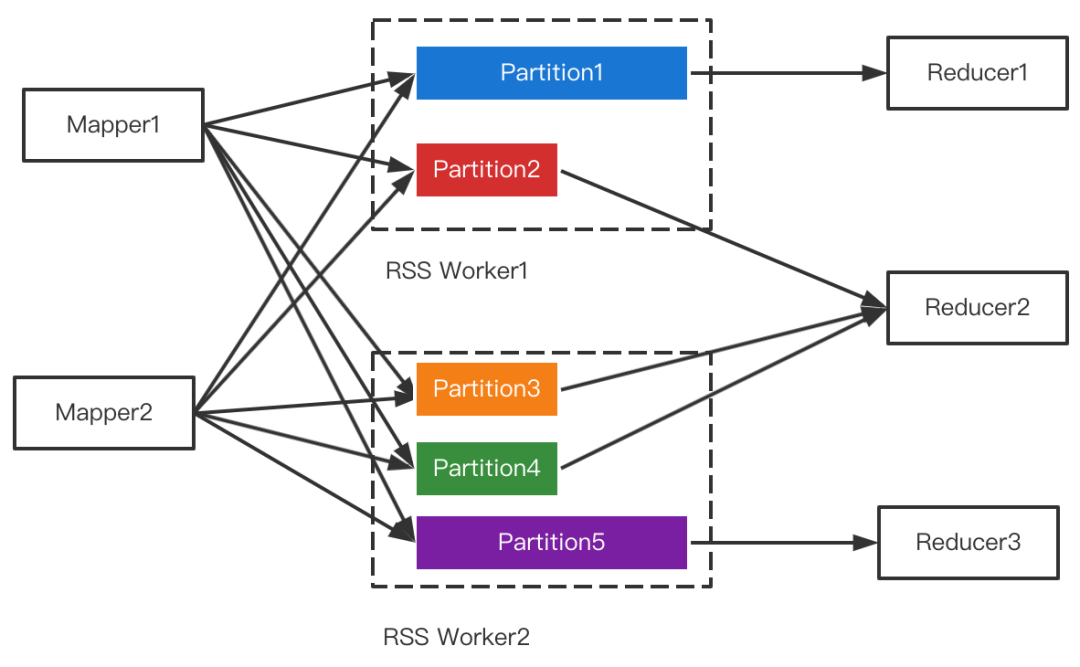
由上图可知,优化后的 Reducer2 需读取原属于 Reducer2-4 的数据,对 Shuffle 框架的需求是 ShuffleReader 需要支持范围 Partition:
def getReader[K, C](handle: ShuffleHandle,startPartition: Int,endPartition: Int,context: TaskContext): ShuffleReader[K, C]Join 策略切换
Join 策略切换的目的是修正由于 Stats 预估不准导致 Optimizer 把本应做的 Broadcast Join 错误的选择了 SortMerge Join 或 ShuffleHash Join。具体而言,在 Join 的两张表做完 Shuffle Write 之后,AQE 框架统计了实际大小,若发现小表符合 Broadcast Join的条件,则将小表Broadcast出去,跟大表的本地 Shuffle数据做Join。流程如下:
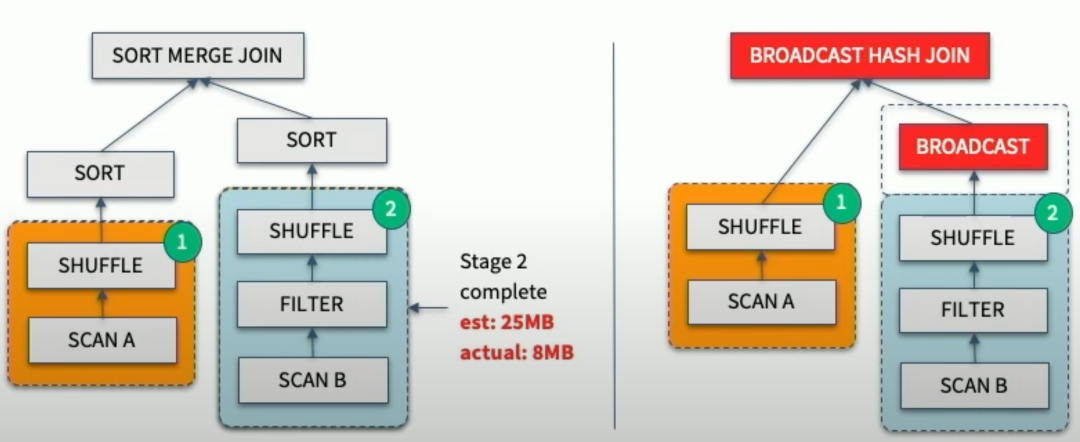
Join策略切换有两个优化:1. 改写成Broadcast Join; 2. 大表的数据通过LocalShuffleReader直读本地。其中第2点对Shuffle框架提的新需求是支持Local Read。
倾斜Join优化
倾斜Join优化的目的是让倾斜的Partition由更多的Reducer去处理,从而避免长尾。具体而言,在Shuffle Write结束之后,AQE框架统计每个Partition的Size,接着根据特定规则判断是否存在倾斜,若存在,则把该Partition分裂成多个Split,每个Split跟另外一张表的对应Partition做Join。如下所示。
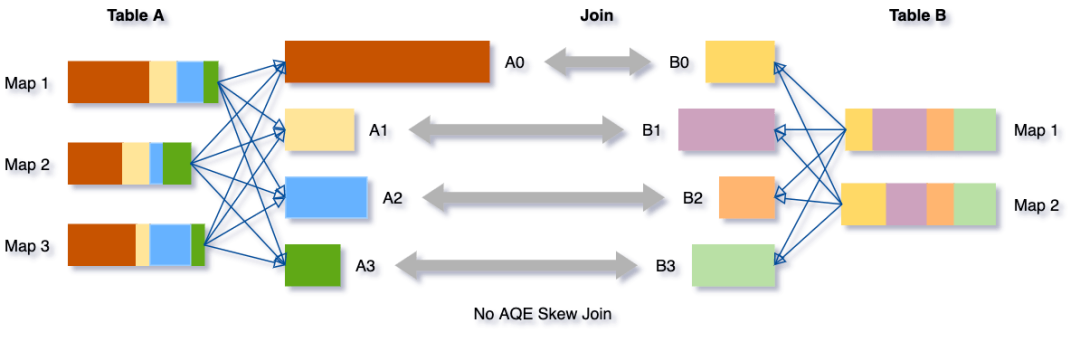
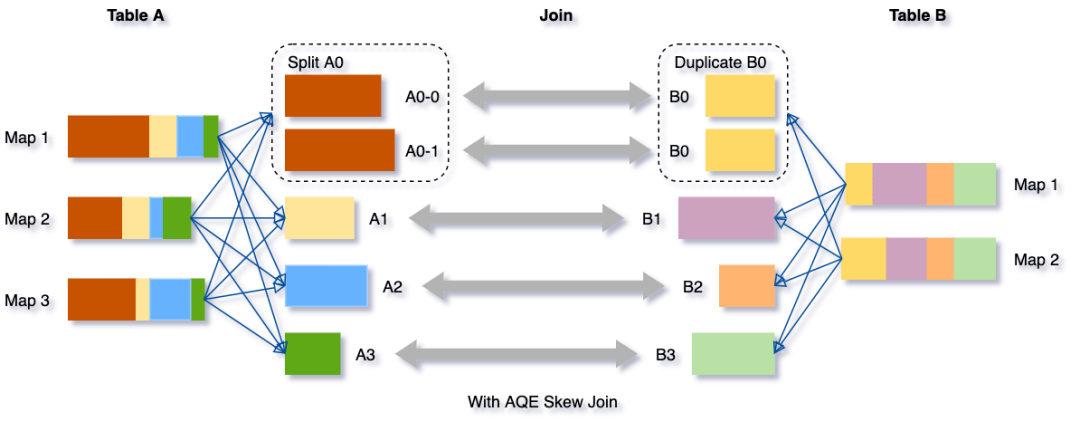
Partiton分裂的做法是按照MapId的顺序累加他们Shuffle Output的Size,累加值超过阈值时触发分裂。对Shuffle框架的新需求是ShuffleReader要能支持范围MapId。综合Partition合并优化对范围Partition的需求,ShuffleReader的接口演化为:
def getReader[K, C](handle: ShuffleHandle,startMapIndex: Int,endMapIndex: Int,startPartition: Int,endPartition: Int,context: TaskContext,metrics: ShuffleReadMetricsReporter): ShuffleReader[K, C]2 RSS架构回顾
RSS的核心设计是Push Shuffle + Partition数据聚合,即不同的Mapper把属于同一个Partition的数据推给同一个Worker做聚合,Reducer直读聚合后的文件。如下图所示。
在核心设计之外,RSS还实现了多副本,全链路容错,Master HA,磁盘容错,自适应Pusher,滚动升级等特性,详见[1]。
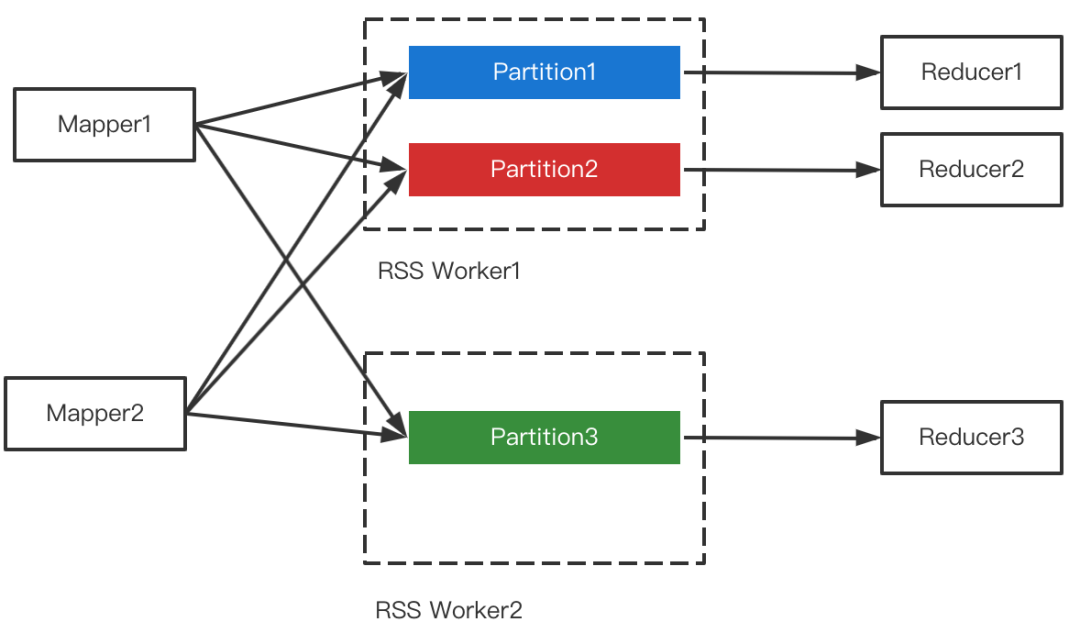
3 RSS支持Partition合并
Partition合并对Shuffle框架的需求是支持范围Partition,在RSS中每个Partition对应着一个文件,因此天然支持,如下图所示。
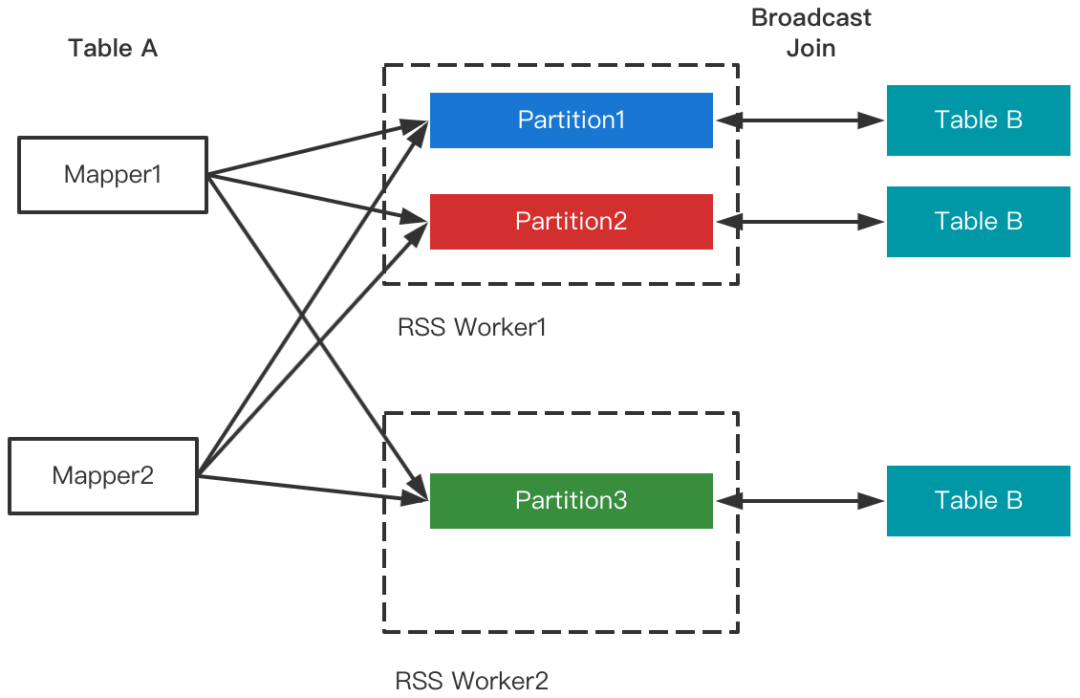
4 RSS支持Join策略切换
Join策略切换对Shuffle框架的需求是能够支持LocalShuffleReader。由于RSS的Remote属性,数据存放在RSS集群,仅当RSS和计算集群混部的场景下才会存在在本地,因此暂不支持Local Read(将来会优化混部场景并加以支持)。需要注意的是,尽管不支持Local Read,但并不影响Join的改写,RSS支持Join改写优化如下图所示。
5 RSS支持Join倾斜优化
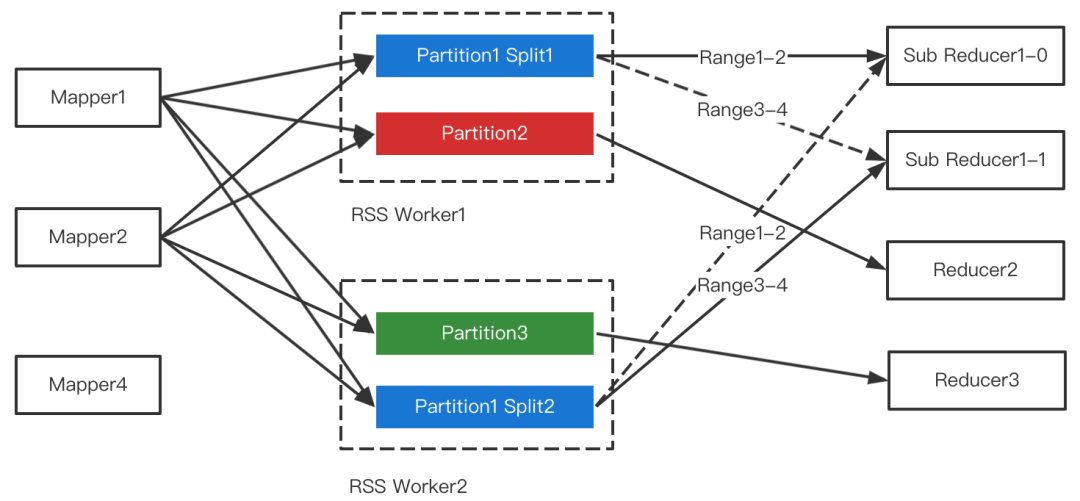
在AQE的三个场景中,RSS支持Join倾斜优化是最为困难的一点。RSS的核心设计是Partition数据聚合,目的是把Shuffle Read的随机读转变为顺序读,从而提升性能和稳定性。多个Mapper同时推送给RSS Worker,RSS在内存聚合后刷盘,因此Partition文件中来自不同Mapper的数据是无序的,如下图所示。

Join倾斜优化需要读取范围Map,例如读Map1-2的数据,常规的做法有两种:
读取完整文件,并丢弃范围之外的数据。
引入索引文件,记录每个Block的位置及所属MapId,仅读取范围内的数据。
这两种做法的问题显而易见。方法1会导致大量冗余的磁盘读;方法2本质上回退成了随机读,丧失了RSS最核心的优势,并且创建索引文件成为通用的Overhead,即使是针对非倾斜的数据(Shuffle Write过程中难以准确预测是否存在倾斜)。
为了解决以上两个问题,我们提出了新的设计:主动Split + Sort On Read。
主动Split
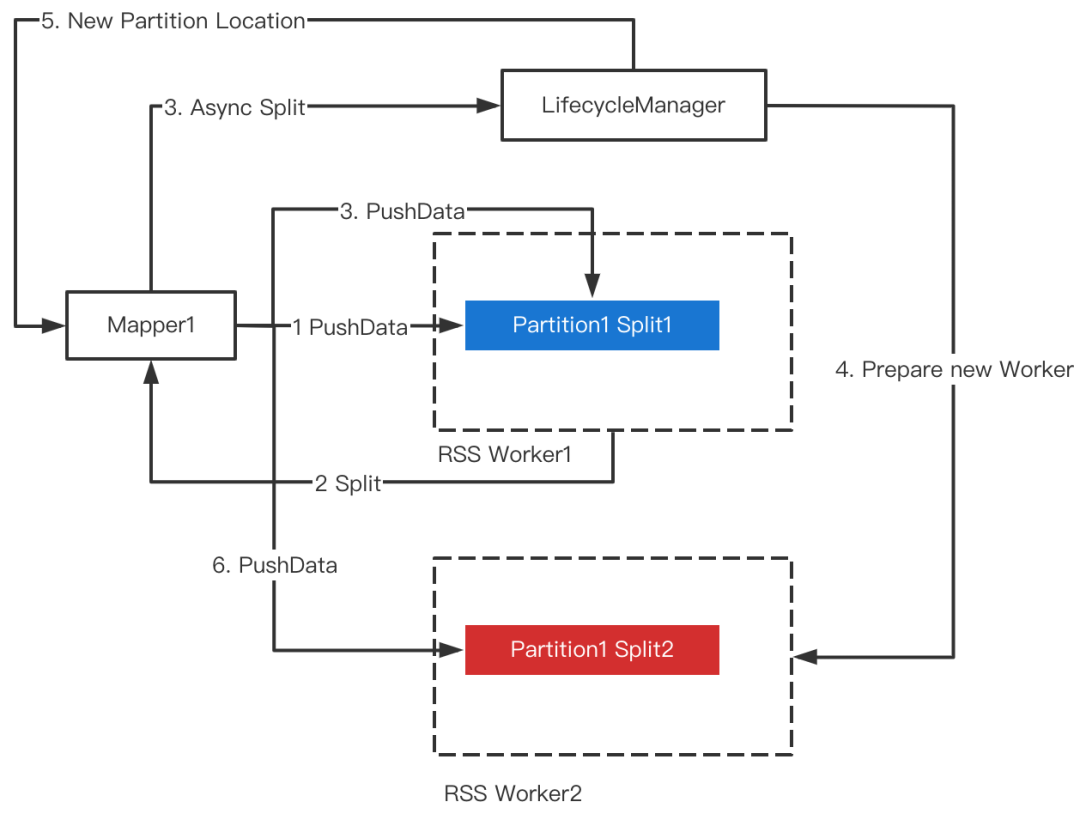
倾斜的Partition大概率Size非常大,极端情况会直接打爆磁盘,即使在非倾斜场景出现大Partition的几率依然不小。因此,从磁盘负载均衡的角度,监控Partition文件的Size并做主动Split(默认阈值256m)是非常必要的。
Split发生时,RSS会为当前Partition重新分配一对Worker(主副本),后续数据将推给新的Worker。为了避免Split对正在运行的Mapper产生影响,我们提出了Soft Split的方法,即当触发Split时,RSS异步去准备新的Worker,Ready之后去热更新Mapper的PartitionLocation信息,因此不会对Mapper的PushData产生任何干扰。整体流程如下图所示。
Sort On Read
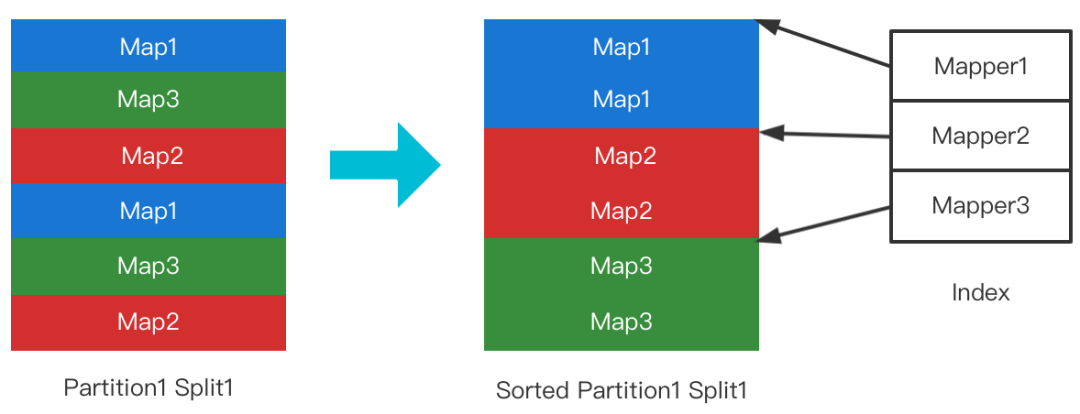
为了避免随机读的问题,RSS采用了Sort On Read的策略。具体而言,File Split的首次Range读会触发排序(非Range读不会触发),排好序的文件连同其位置索引写回磁盘。后续的Range读即可保证是顺序读取。如下图所示。
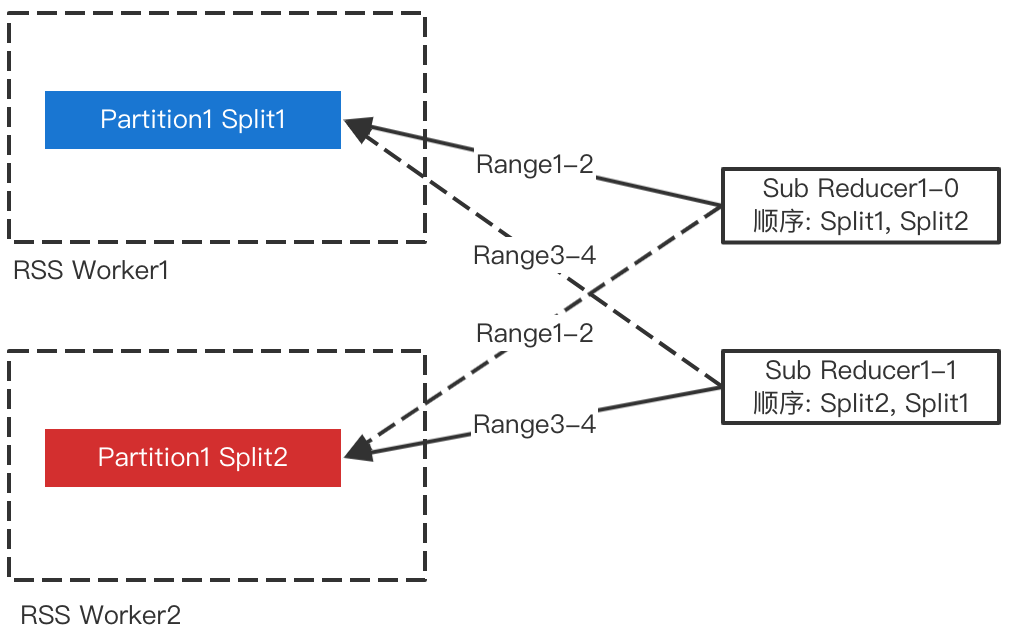
为了避免多个Sub-Reducer等待同一个File Split的排序,我们打散了各个Sub-Reducer读取Split的顺序,如下图所示。
Sort优化
Sort On Read可以有效避免冗余读和随机读,但需要对Split File(256m)做排序,本节讨论排序的实现及开销。文件排序包括3个步骤:读文件,对MapId做排序,写文件。RSS的Block默认256k,Block的数量大概是1000,因此排序的过程非常快,主要开销在文件读写。整个排序过程大致有三种方案:
预先分配文件大小的内存,文件整体读入,解析并排序MapId,按MapId顺序把Block写回磁盘。
不分配内存,Seek到每个Block的位置,解析并排序MapId,按MapId顺序把原文件的Block transferTo新文件。
分配小块内存(如256k),顺序读完整个文件并解析和排序MapId,按MapId顺序把原文件的Block transferTo新文件。
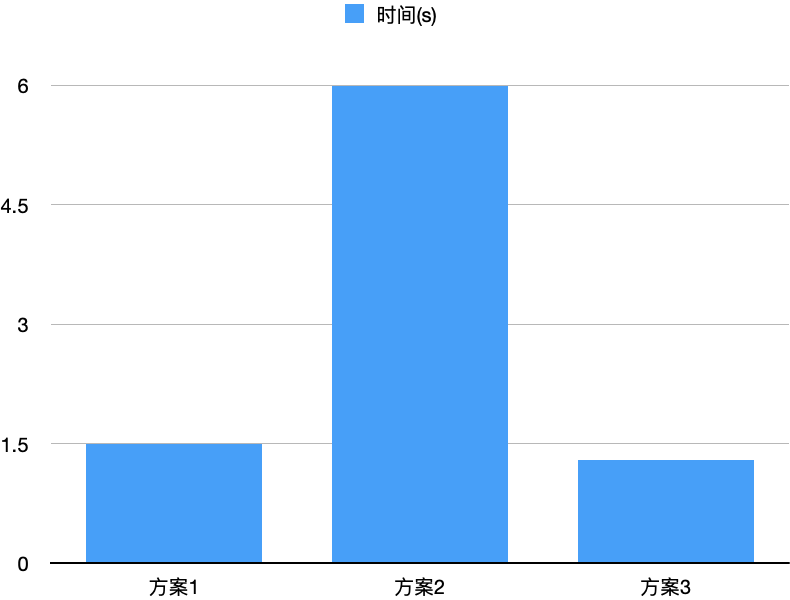
从IO的视角,乍看之下,方案1通过使用足量内存,不存在顺序读写;方案2存在随机读和随机写;方案3存在随机写;直观上方案1性能更好。然而,由于PageCache的存在,方案3在写文件时原文件大概率缓存在PageCache中,因此实测下来方案3的性能更好,如下图所示。
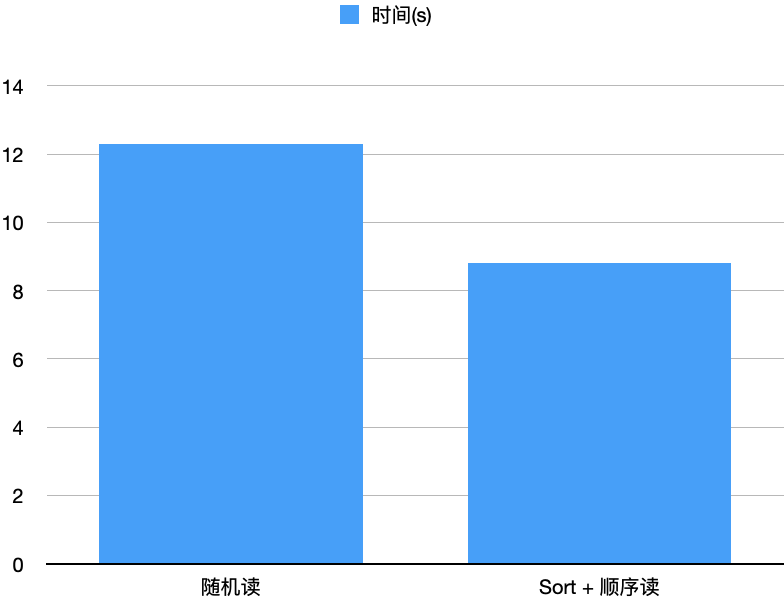
同时方案3无需占用进程额外内存,故RSS采用方案3的算法。我们同时还测试了Sort On Read跟上述的不排序、仅做索引的随机读方法的对比,如下图所示。
整体流程
RSS支持Join倾斜优化的整体流程如下图所示。
二 RSS流控
流控的主要目的是防止RSS Worker内存被打爆。流控通常有两种方式:
Client在每次PushData前先向Worker预留内存,预留成功才触发Push。
Worker端反压。
由于PushData是非常高频且性能关键的操作,若每次推送都额外进行一次RPC交互,则开销太大,因此我们采用了反压的策略。以Worker的视角,流入数据有两个源:
Client推送的数据
主副本发送的数据
如下图所示,Worker2既接收来自Mapper推送的Partition3的数据,也接收Worker1发送的Partition1的副本数据,同时会把Partition3的数据发给对应的从副本。
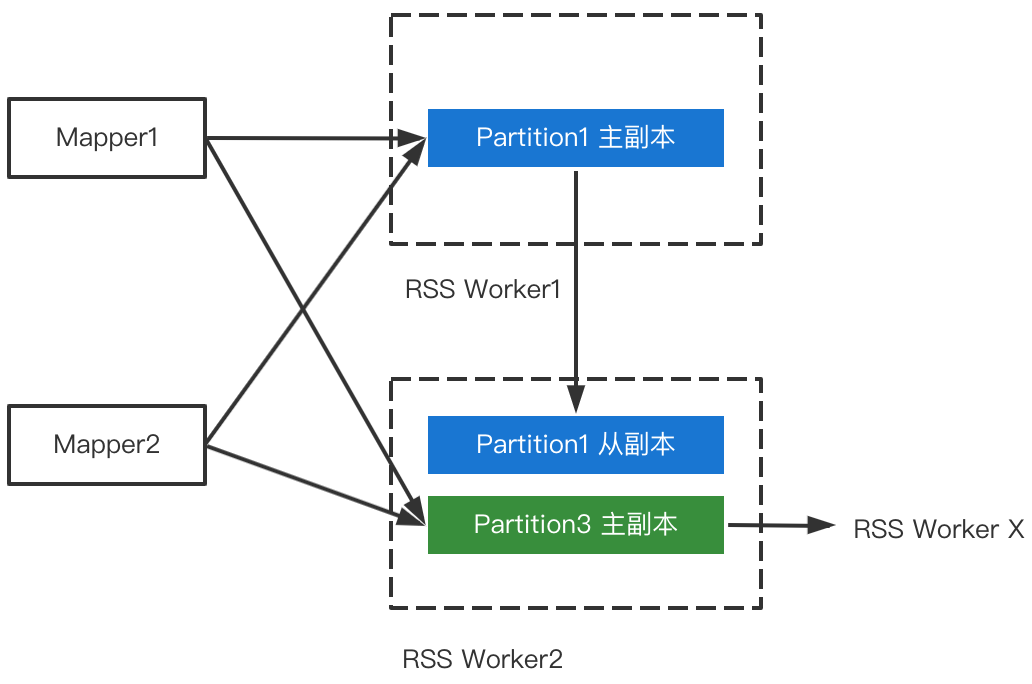
其中,来自Mapper推送的数据,当且仅当同时满足以下条件时才会释放内存:
Replication执行成功
数据写盘成功
来自主副本推送的数据,当且仅当满足以下条件时才会释放内存:
数据写盘成功
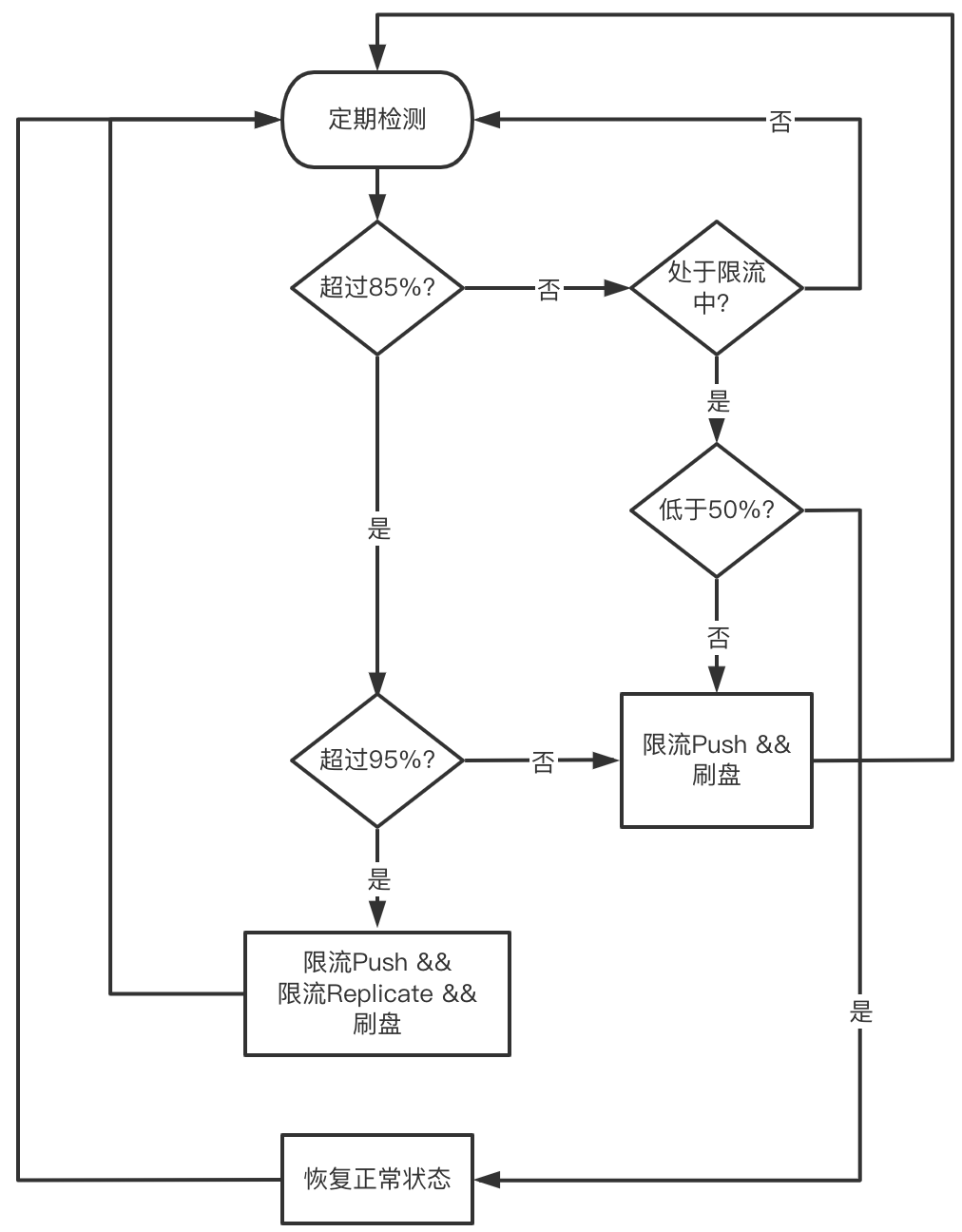
我们在设计流控策略时,不仅要考虑限流(降低流入的数据),更要考虑泄流(内存能及时释放)。具体而言,高水位我们定义了两档内存阈值(分别对应85%和95%内存使用),低水位只有一档(50%内存使用)。达到高水位一档阈值时,触发流控,暂停接收Mapper推送的数据,同时强制刷盘,从而达到泄流的目标。仅限制来自Mapper的流入并不能控制来自主副本的流量,因此我们定义了高水位第二档,达到此阈值时将同时暂停接收主副本发送的数据。当水位低于低水位后,恢复正常状态。整体流程如下图所示。
三 性能测试
我们对比了RSS和原生的External Shufle Service(ESS)在Spark3.2.0开启AQE的性能。RSS采用混部的方式,没有额外占用任何机器资源。此外,RSS所使用的内存为8g,仅占机器内存的2.3%(机器内存352g)。具体环境如下。
1 测试环境
硬件:
header 机器组 1x ecs.g5.4xlarge
worker 机器组 8x ecs.d2c.24xlarge,96 CPU,352 GB,12x 3700GB HDD。
Spark AQE相关配置:
spark.sql.adaptive.enabled true
spark.sql.adaptive.coalescePartitions.enabled true
spark.sql.adaptive.coalescePartitions.initialPartitionNum 1000
spark.sql.adaptive.skewJoin.enabled true
spark.sql.adaptive.localShuffleReader.enabled falseRSS相关配置:
RSS_MASTER_MEMORY=2g
RSS_WORKER_MEMORY=1g
RSS_WORKER_OFFHEAP_MEMORY=7g2 TPCDS 10T测试集
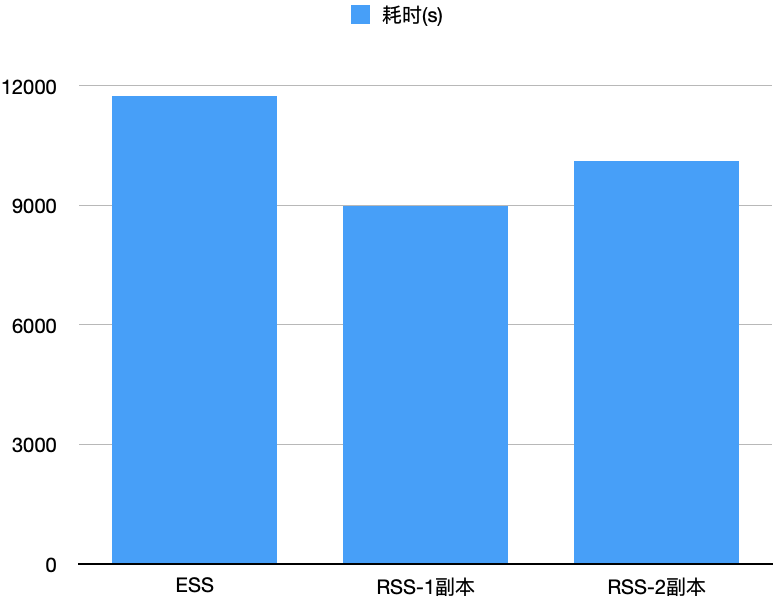
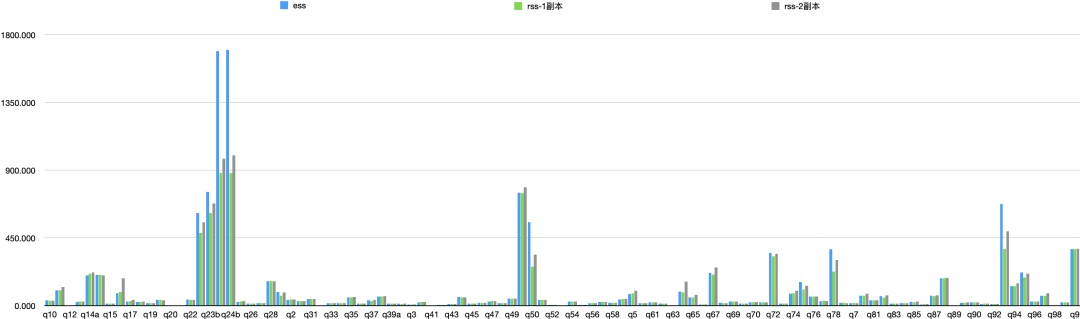
我们测试了10T的TPCDS,E2E来看,ESS耗时11734s,RSS单副本/两副本分别耗时8971s/10110s,分别比ESS快了23.5%/13.8%,如下图所示。我们观察到RSS开启两副本时网络带宽达到上限,这也是两副本比单副本低的主要因素。
具体每个Query的时间对比如下:
相关链接
欢迎各位开发者参与讨论和共建!
github地址:
https://github.com/alibaba/RemoteShuffleService
Reference
[1]阿里云EMR Remote Shuffle Service在小米的实践,以及开源.
https://developer.aliyun.com/article/857757
[2]Adaptive Query Execution: Speeding Up Spark SQL at Runtime.
https://databricks.com/blog/2020/05/29/adaptive-query-execution-speeding-up-spark-sql-at-runtime.html
欢迎钉钉扫码加入RSS用户群

这篇关于阿里云 RemoteShuffleService 新功能:AQE和流控的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







