本文主要是介绍spark-3.0-AQE(Adaptive Query Execution)自适应查询,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前置
AQE是一个运行时SQL优化框架,旨在解决由于优化器统计信息不足、不准确或过时而导致的查询执行计划的低效和缺乏灵活性的问题。
可以理解成是 Spark Catalyst 之上的一层,它可以在运行时修改 Spark plan,之前的物理执行计划不再是最终的计划,而是在每个query stage完成之后,动态的根据数据统计的情况,动态调整后续计划,
动态合并shuffle分区,自动调整SQL JOIN策略;动态优化数据倾斜。默认关闭,可以更改配置 “spark.sql.adaptive.enabled”: true 以打开
https://blog.csdn.net/lovetechlovelife/article/details/114744270
AQE分了3个方面来优化
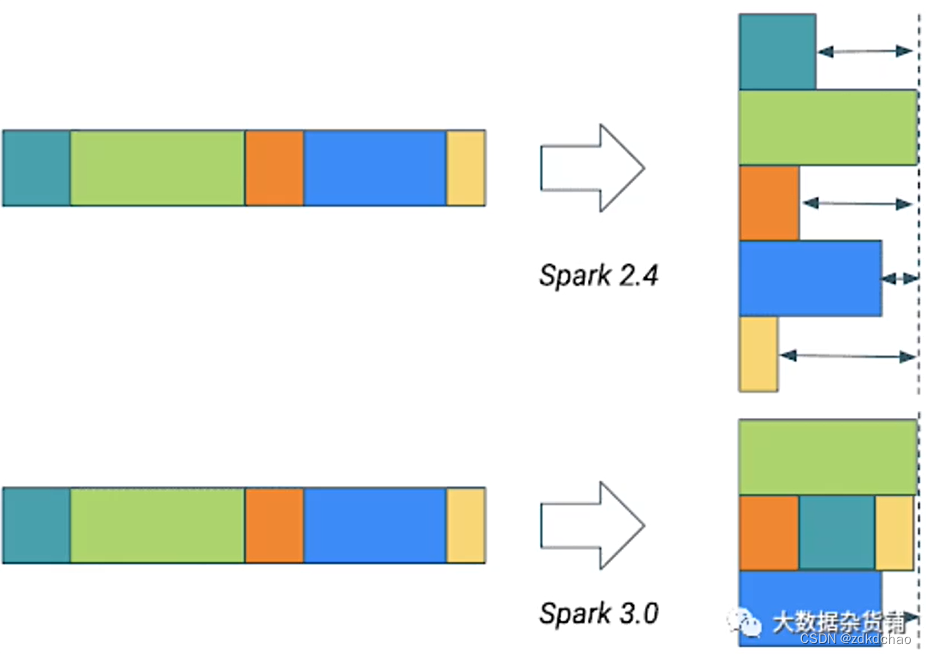
动态合并shuffle分区
shuffle分区数量3.0之前默认200
分区数量太小
- io效率低
- 任务启动/调度耗时占比高
分区数量太大 - GC压力
- 溢写到磁盘
不同stage分区数量不一样,无法自适应数据规模调整
AQE在初始时设置较大的分区数,每个query stage结束后,合并较小的数据分区
动态调整join策略
spark join 有3种不同的join策略
每个query stage结束后,自动检测join的表大小,并判断是否调整为broadcast hash join,进行mapjoin
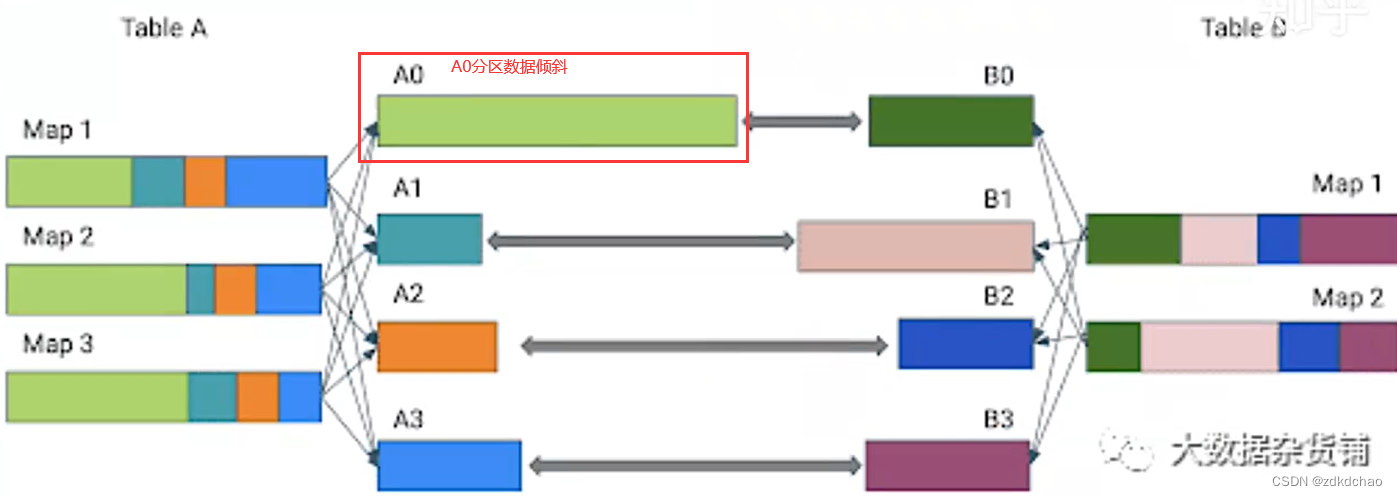
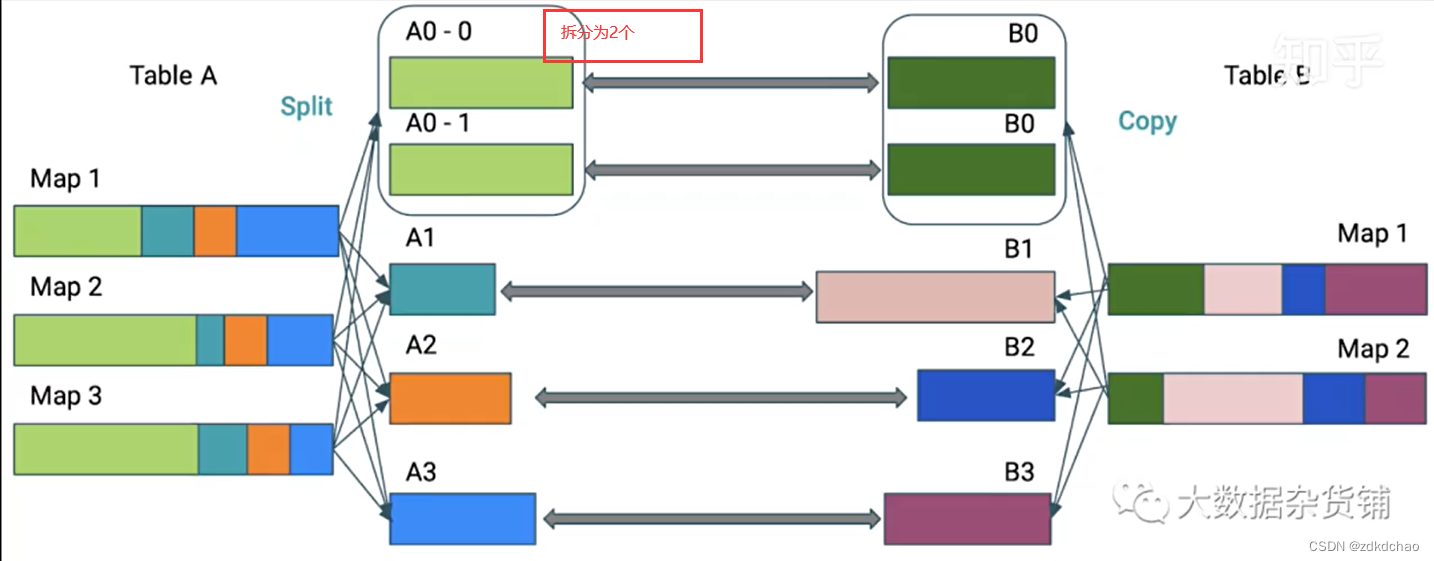
动态优化数据倾斜
这篇关于spark-3.0-AQE(Adaptive Query Execution)自适应查询的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







