本文主要是介绍Spark 3.0 - AQE浅析 (Adaptive Query Execution),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、前言
近些年来,在对Spark SQL优化上,CBO是最成功的一个特性之一。
CBO会计算一些和业务数据相关的统计数据,来优化查询,例如行数、去重后的行数、空值、最大最小值等。
Spark根据这些数据,自动选择BHJ或者SMJ,对于多Join场景下的Cost-based Join Reorder(可以参考之前写的这篇文章),来达到优化执行计划的目的。
但是,由于这些统计数据是需要预先处理的,会过时,所以我们在用过时的数据进行判断,在某些情况下反而会变成负面效果,拉低了SQL执行效率。
AQE在执行过程中统计数据,并动态地调节执行计划,从而解决了这个问题。
2、框架
对于AQE而言,最重要的问题就是什么时候去重新计算优化执行计划。Spark任务的算子如果管道排列,依次并行执行。然而,shuffle或者broadcast exchange会打断算子的排列执行,我们称其为物化点(Materialization Points),并且用"Query Stages"来代表那些被物化点所分割的小片段。每个Query Stage会产出中间结果,当且仅当该stage及其并行的所有stage都执行完成后,下游的Query Stage才能被执行。所以当上游部分stage执行完成,partitions的统计数据也获取到了,并且下游还未开始执行,这就给AQE提供了reoptimization的机会。
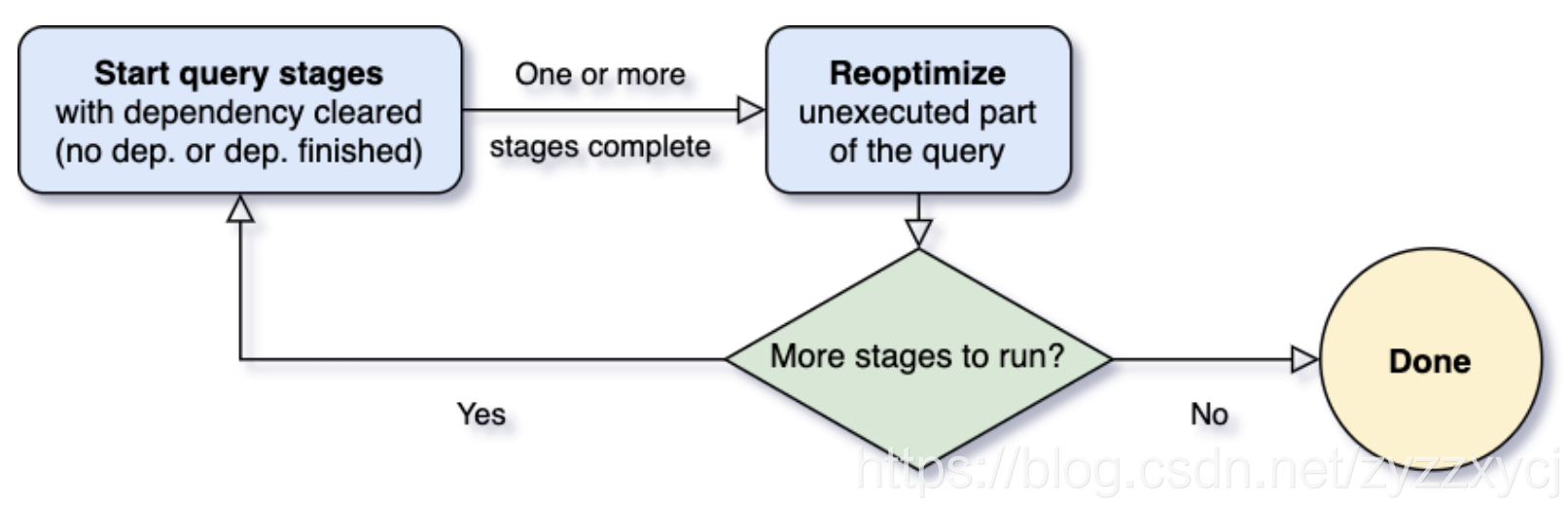
在查询开始时,生成完了执行计划,AQE框架首先会找到并执行那些不存在上游的stages。一旦这些stage有一个或多个完成,AQE框架就会将其在physical plan中标记为完成,并根据已完成的stages提供的执行数据来更新整个logical plan。基于这些新产出的统计数据,AQE框架会执行optimizer,根据一系列的优化规则来进行优化;AQE框架还会执行生成普通physical plan的optimizer以及自适应执行专属的优化规则,例如分区合并、数据倾斜处理等。于是,我们就获得了最新优化过的执行计划和一些已经执行完成的stages,至此为一次循环。接着我们只需要继续重复上面的步骤,直到整个query都跑完。
在Spark 3.0中,AQE框架拥有三大特征:
- 动态折叠shuffle过程中的partition
- 动态选择join策略
- 动态优化存在数据倾斜的join
接下来我们就具体来看看这三大特征。
① 动态合并shuffle partitions
在我们处理的数据量级非常大时,shuffle通常来说是最影响性能的。因为shuffle是一个非常耗时的算子,它需要通过网络移动数据,分发给下游算子。
在shuffle中,partition的数量十分关键。partition的最佳数量取决于数据,而数据大小在不同的query不同stage都会有很大的差异,所以很难去确定一个具体的数目:
- 如果partition过少,每个partition数据量就会过多,可能就会导致大量数据要落到磁盘上,从而拖慢了查询。
- 如果partition过多,每个partition数据量就会很少,就会产生很多额外的网络开销,并且影响Spark task scheduler,从而拖慢查询。
为了解决该问题,我们在最开始设置相对较大的shuffle partition个数,通过执行过程中shuffle文件的数据来合并相邻的小partitions。
例如,假设我们执行SELECT max(i) FROM tbl GROUP BY j,表tbl只有2个partition并且数据量非常小。我们将初始shuffle partition设为5,因此在分组后会出现5个partitions。若不进行AQE优化,会产生5个tasks来做聚合结果,事实上有3个partitions数据量是非常小的。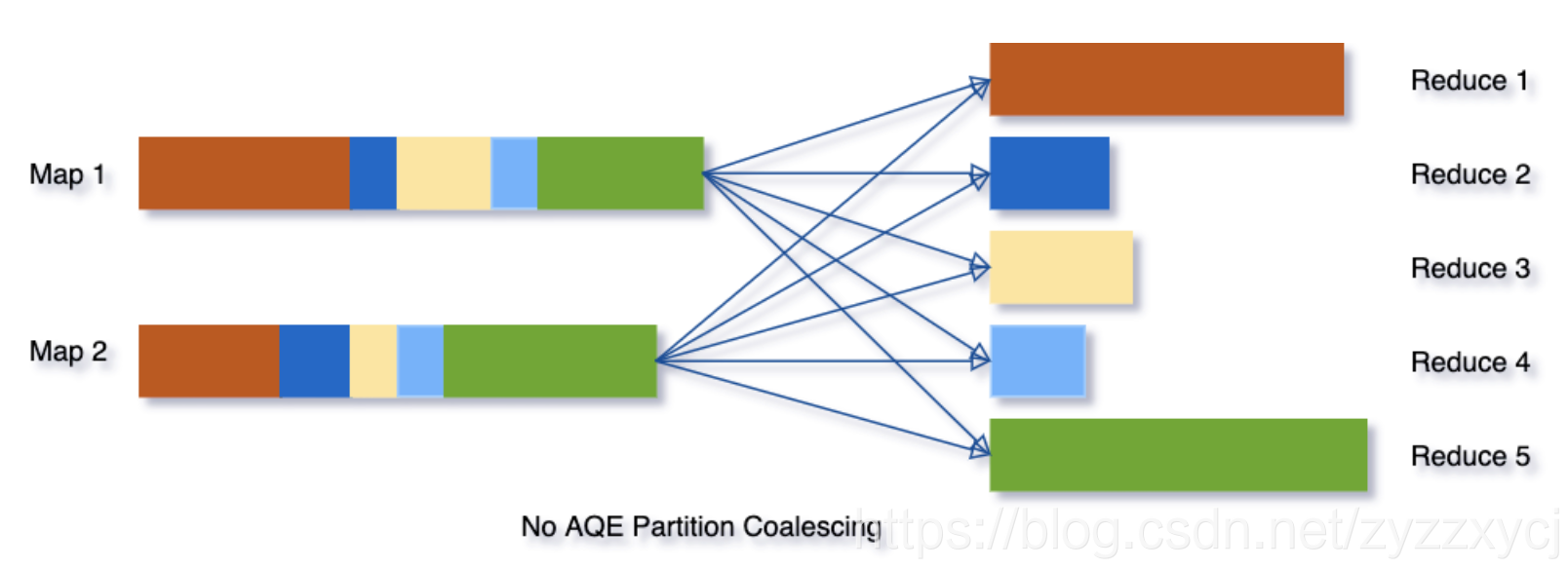
然而在这种情况下,AQE只会生成3个reduce task。

② 动态切换join策略
在Spark所支持的众多join中,broadcast hash join性能是最好的。因此,如果需要广播的表的预估大小小于了广播限制阈值,那么我们就应该将其设为BHJ。但是,对于表的大小估计不当会导致决策错误,比如join表有很多的filter(容易把表估大)或者join表有很多其他算子(容易把表估小),而不仅仅是全量扫描一张表。
由于AQE拥有精确的上游统计数据,因此可以解决该问题。比如下面这个例子,右表的实际大小为15M,而在该场景下,经过filter过滤后,实际参与join的数据大小为8M,小于了默认broadcast阈值10M,应该被广播。
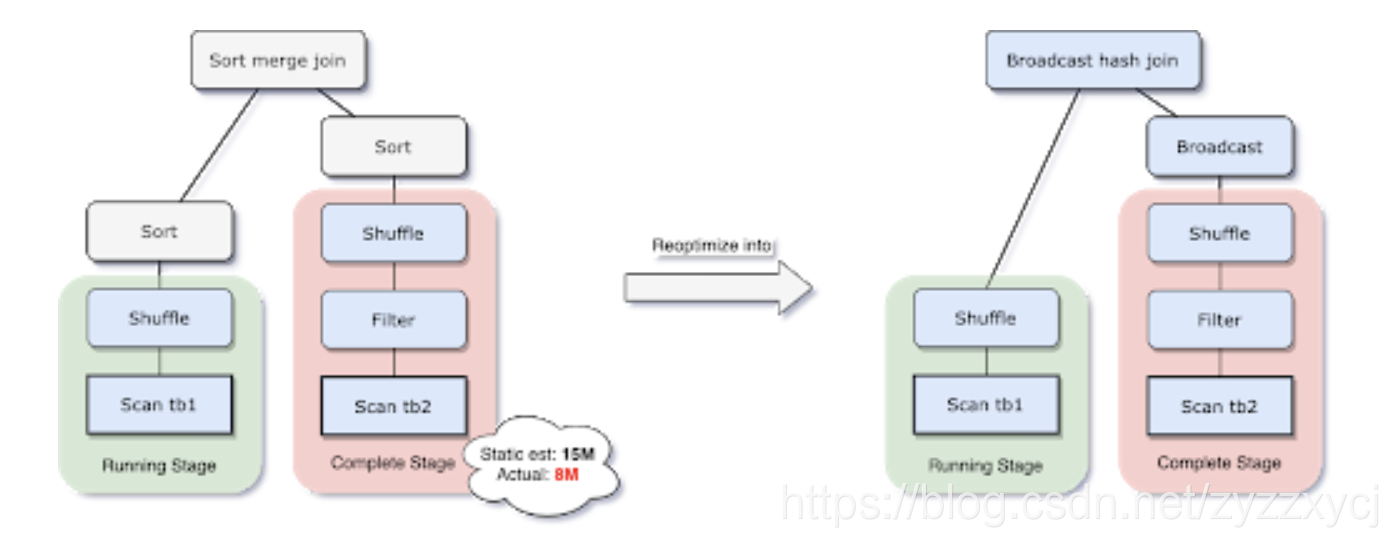
在我们执行过程中转化为BHJ的同时,我们甚至可以将传统shuffle优化为本地shuffle(例如shuffle读在mapper而不是基于reducer)来减小网络开销。
③ 动态优化数据倾斜
数据倾斜是由于集群上数据在分区之间分布不均匀所导致的,它会拉慢join场景下整个查询。AQE根据shuffle文件统计数据自动检测倾斜数据,将那些倾斜的分区打散成小的子分区,然后各自进行join。
我们可以看下这个场景,Table A join Table B,其中Table A的partition A0数据远大于其他分区。
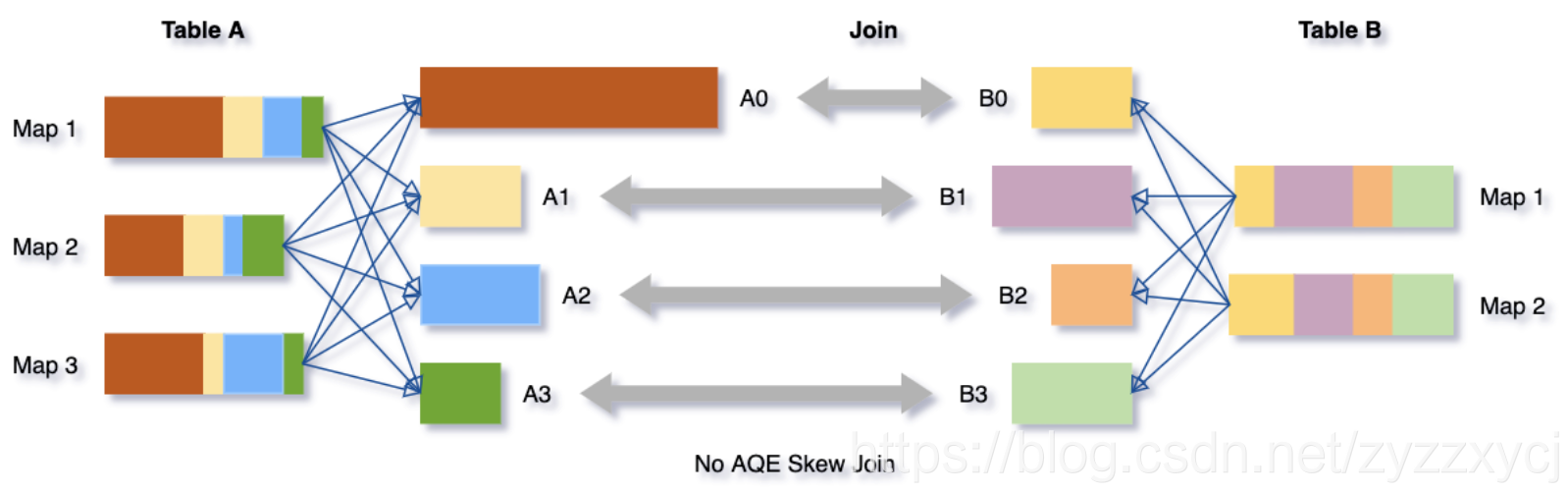
AQE会将partition A0切分成2个子分区,并且让他们独自和Table B的partition B0进行join。
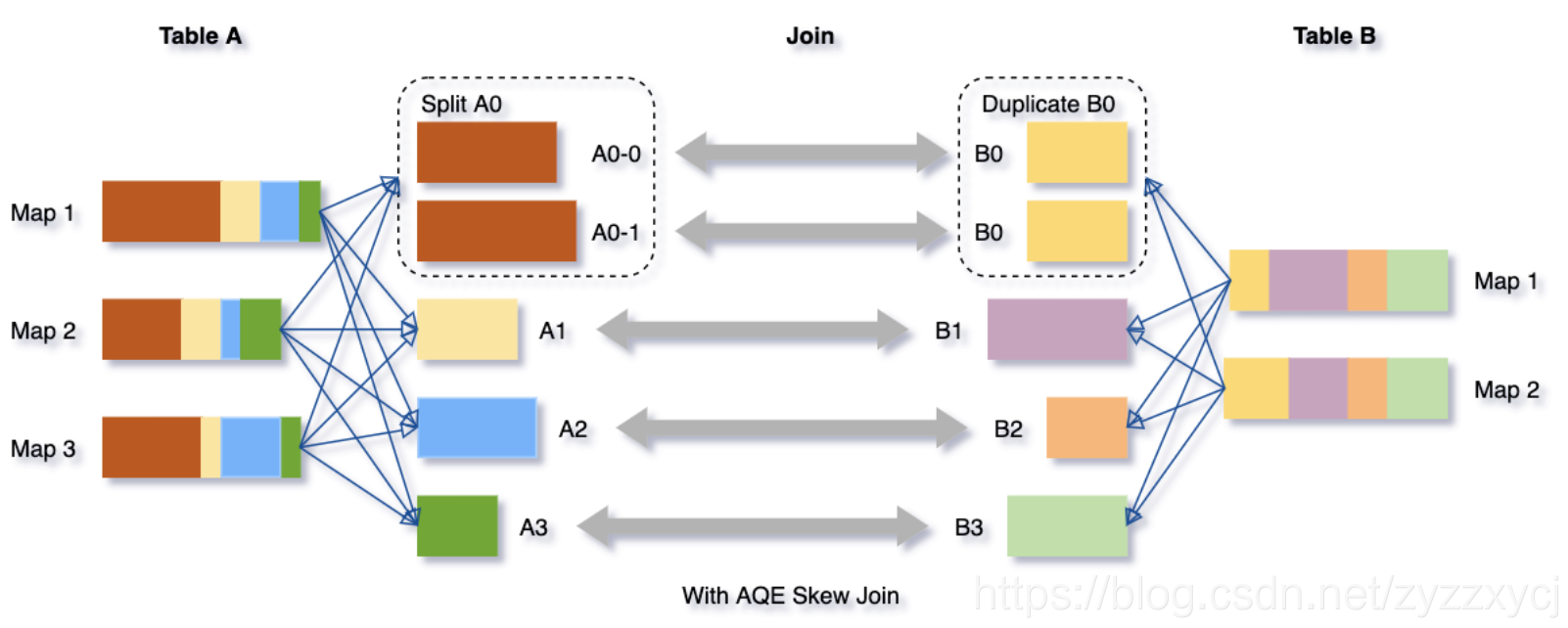
如果不做这个优化,SMJ将会产生4个tasks并且其中一个执行时间远大于其他。经优化,这个join将会有5个tasks,但每个task执行耗时差不多相同,因此个整个查询带来了更好的性能。
3、使用
我们可以设置参数spark.sql.adaptive.enabled为true来开启AQE,在Spark 3.0中默认是false,并满足以下条件:
- 非流式查询
- 包含至少一个exchange(如join、聚合、窗口算子)或者一个子查询
AQE通过减少了对静态统计数据的依赖,成功解决了Spark CBO的一个难以处理的trade off(生成统计数据的开销和查询耗时)以及数据精度问题。相比之前具有局限性的CBO,现在就显得非常灵活 - 我们再也不需要提前去分析数据了!
本文参考Adaptive Query Execution: Speeding Up Spark SQL at Runtime
这篇关于Spark 3.0 - AQE浅析 (Adaptive Query Execution)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




