本文主要是介绍Spark 3.0自适应查询执行框架(AQE),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. AQE设计原理
AQE 可以理解成是 Spark Catalyst 之上的一层,它可以在运行时修改 Spark plan。
AQE 完全基于精确的运行时统计信息进行优化,引入了 Query Stages 的概念 ,并且以 Query Stage 为粒度,进行运行时的优化,其工作原理如下所示:
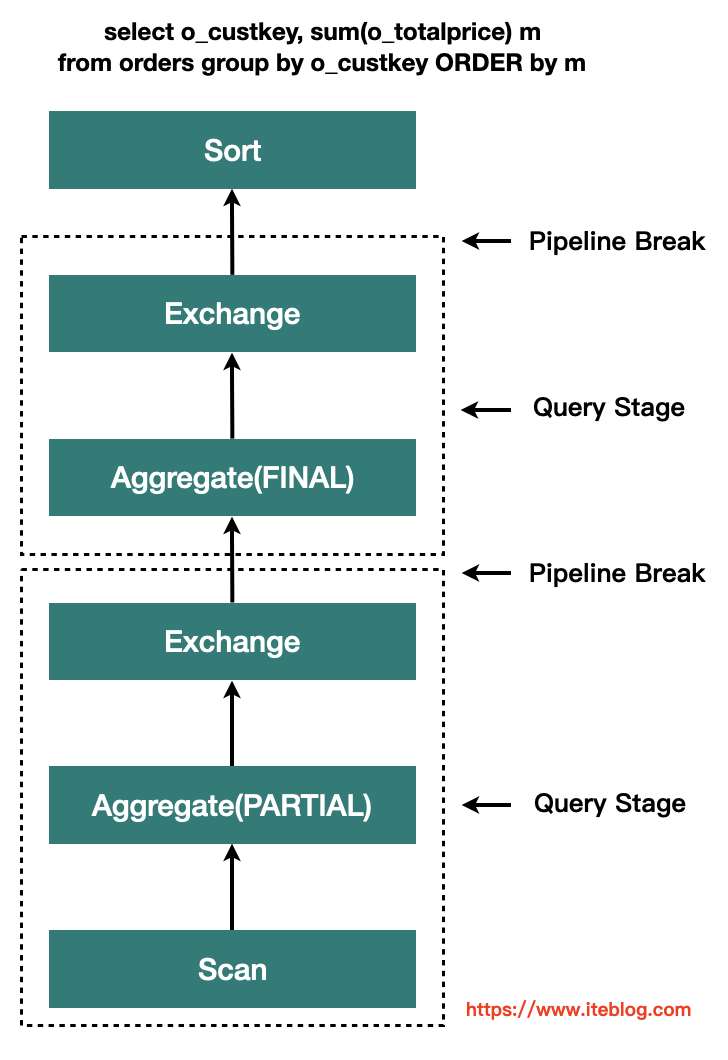
Query Stage 是由 Shuffle 或 broadcast exchange 划分的,在运行下一个 Query Stage 之前,上一个 Query Stage 的计算需要全部完成,这是进行运行时优化的绝佳时机,因为此时所有分区上的数据统计都是可用的,并且后续操作还没有开始。
2. AQE优化重点
2.1 自适应调整分区数
开启自适应调整分区数后,Spark 将会把连续的 shuffle partitions 进行合并(coalesce contiguous shuffle partitions)以减少分区数。
参数设置
spark.sql.adaptive.enabled
spark.sql.adaptive.coalescePartitions.enabled
spark.sql.adaptive.advisoryPartitionSizeInBytes
2.2 动态优化倾斜的 join
AQE解决倾斜Join时,从 shuffle 文件统计信息中自动检测到这种倾斜。然后,它将倾斜的分区分割成更小的子分区,这些子分区将分别从另一端连接到相应的分区。
参数设置
spark.sql.adaptive.skewJoin.enabled :是否启用倾斜 Join 处理;spark.sql.adaptive.skewJoin.skewedPartitionFactor:如果一个分区的大小大于这个数乘以分区大小的中值(median partition size),并且也大于spark.sql.adaptive.skewedPartitionThresholdInBytes 这个属性值,那么就认为这个分区是倾斜的。
spark.sql.adaptive.skewedPartitionThresholdInBytes:判断分区是否倾斜的阈值,默认为 256MB,这个参数的值应该要设置的比 spark.sql.adaptive.advisoryPartitionSizeInBytes 大。
2.3 动态将 Sort Merge Joins 转换成 Broadcast Joins
Spark支持各种Join策略,其中broadcast hash join通常是性能最好的,前提是参加join的一张表的数据小于广播阀值。
很多情况spark估算表大小是否小于广播阀值的时候,可能估算出错,比如表的统计信息不准确等。有了 AQE,Spark 可以利用运行时的统计信息动态调整Join方式,只要参与Join的任何一方的大小小于广播大小的阈值时,即可将 Join 策略调整为 broadcast hash join。
这篇关于Spark 3.0自适应查询执行框架(AQE)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







