adaboost专题

Pandas使用AdaBoost进行分类的实现
《Pandas使用AdaBoost进行分类的实现》Pandas和AdaBoost分类算法,可以高效地进行数据预处理和分类任务,本文主要介绍了Pandas使用AdaBoost进行分类的实现,具有一定的参... 目录什么是 AdaBoost?使用 AdaBoost 的步骤安装必要的库步骤一:数据准备步骤二:模型
Adaboost——三个臭皮匠赛过诸葛亮
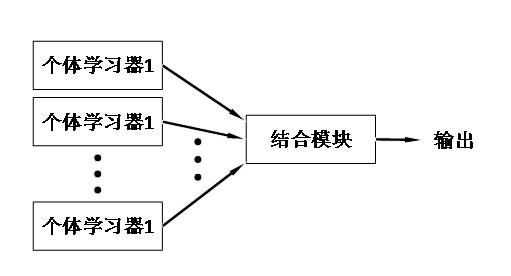
古人云“三个臭皮匠赛过诸葛亮”,以adaboost为代表的集成学习正是体现了古人的这个智慧,也就是说,对于弱学习器(性能比较差的学习器),通过某种算法把它们结合起来,使它们能够有缺互补,那么它们就能赛过诸葛亮(强学习器)。下面是集成学习的示意图。 图 1集成学习示意图 对于个体学习器,可以使用同类学习算法,也可以是不同类学习算法。理想的个体学习器是</

回归预测|基于粒子群优化核极限学习机PSO-KELM结合Adaboost集成的数据预测Matlab程序 多特征输入单输出
回归预测|基于粒子群优化核极限学习机PSO-KELM结合Adaboost集成的数据预测Matlab程序 多特征输入单输出 文章目录 一、基本原理1. 数据预处理2. PSO优化(粒子群优化)3. KELM训练(核极限学习机)4. AdaBoost集成5. 模型评估和优化6. 预测总结 二、实验结果三、核心代码四、代码获取五、总结 回归预测|基于粒子群优化核极限学习机PSO-
基于Python的机器学习系列(16):扩展 - AdaBoost
简介 在本篇中,我们将扩展之前的AdaBoost算法实现,深入探索其细节并进行一些修改。我们将重点修复代码中的潜在问题,并对AdaBoost的实现进行一些调整,以提高其准确性和可用性。 1. 修复Alpha计算中的问题 在AdaBoost中,如果分类器的错误率 e 为0,则计算出的权重 α 将是未定义的。为了解决这个问题,我们可以在计算过程中向分母中添加一个非

Adaboost 算法的原理与推导(读书笔记)
Adaboost 算法的原理与推导 0 引言 一直想写Adaboost来着,但迟迟未能动笔。其算法思想虽然简单“听取多人意见,最后综合决策”,但一般书上对其算法的流程描述实在是过于晦涩。昨日11月1日下午,邹博在我组织的机器学习班第8次课上讲决策树与Adaboost,其中,Adaboost讲得酣畅淋漓,讲完后,我知道,可以写本篇博客了。 无心

回归预测 | Matlab实现GWO-BP-Adaboost灰狼算法优化BP神经网络集成学习多输入单输出回归预测
回归预测 | Matlab实现GWO-BP-Adaboost灰狼算法优化BP神经网络集成学习多输入单输出回归预测 目录 回归预测 | Matlab实现GWO-BP-Adaboost灰狼算法优化BP神经网络集成学习多输入单输出回归预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 Matlab实现GWO-BP-Adaboost灰狼算法优化BP神经网络集成学习多输入

Adaboost集成学习 | Adaboost集成学习特征重要性分析(Python)
目录 效果一览基本介绍模型设计程序设计参考资料 效果一览 基本介绍 Adaboost集成学习特征重要性分析(Python)Adaboost(自适应增强)是一种常用的集成学习方法,用于提高机器学习算法的准确性。它通过组合多个弱分类器来构建一个强分类器。在Adaboost中,每个弱分类器都被赋予一个权重,这些权重根据其在训练过程中的表现进行调整。因此,Adaboost可以通

boosting,Adaboost,Bootstrap和Bagging的含义和区别
弱分类器:分类效果差,只是比随机猜测好一点。 强分类器:具有较高的识别率,较好的分类效果。(在百度百科中有提到要能在多项式时间内完成学习) 弱和强更大意义上是相对而言的,并没有严格的限定。比如准确率低于多少就是弱分类器,高于多少是强分类器,因具体问题而定。 1988年,有学者提出是否可以通过一些弱分类器来实现强分类器的分类效果。基于这个问题,之后两三年陆续的有早期的boosting算法

Boosting和AdaBoost的可视化的清晰的解释
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 作者:Maël Fabien 编译:ronghuaiyang 前戏 可视化的方法,清楚的解释了Boosting和AdaBoost。 最近,在Kaggle竞赛和其他预测分析任务中,boosting技术正在兴起。我将尽可能清楚地解释boost和AdaBoost的概念。 在本文中,我们将讨论: 快速回顾baggingbagging的限制
2-11 基于matlab的BP-Adaboost的强分类器分类预测
基于matlab的BP-Adaboost的强分类器分类预测,Adaboost是一种迭代分类算法,其在同一训练集采用不同方法训练不同分类器(弱分类器),并根据弱分类器的误差分配不同权重,然后将这些弱分类器组合成一个更强的最终分类器(强分类器),并一直迭代,直到分类的错误率达到之前设定的阈值或者迭代次数达到设定最大迭代次数。程序已调通,可直接运行。 2-11 BP-Adaboost 分类器分类预

行人检测(haar+adaboost 与 hog+SVM)
最近在做行人检测,而最流行,也是最老的两种方法就是haar+adaboost 与 hog+SVM。两种我都尝试了,效果并不如想象的好,所以要想有更好的效果,一是要有预处理,二是要有更大量的正负样本。 下面现总结一下自己应用的 haar+Adaboost 进行的行人检测: 我分别训练了两个分类器,训练数据库均来自NICTA(澳大利亚信息与通讯技术研究中心),用其中的2000张

【Python】在 Pandas 中使用 AdaBoost 进行分类
我们都找到天使了 说好了 心事不能偷藏着 什么都 一起做 幸福得 没话说 把坏脾气变成了好沟通 我们都找到天使了 约好了 负责对方的快乐 阳光下 的山坡 你素描 的以后 怎么抄袭我脑袋 想的 🎵 薛凯琪《找到天使了》 在数据科学和机器学习的工作流程中,Pandas 是一个非常强大的数据操作和分析工具库。结合 Pandas 和 AdaBoost

【Python】深入了解 AdaBoost:自适应提升算法
我们都找到天使了 说好了 心事不能偷藏着 什么都 一起做 幸福得 没话说 把坏脾气变成了好沟通 我们都找到天使了 约好了 负责对方的快乐 阳光下 的山坡 你素描 的以后 怎么抄袭我脑袋 想的 🎵 薛凯琪《找到天使了》 在机器学习的领域中,集成学习是一种非常强大的技术,它通过结合多个模型的预测来提升整体的性能。AdaBoost(Adaptive

Adaboost集成学习 | Matlab实现基于CNN-LSTM-Adaboost集成学习时间序列预测(股票价格预测)
目录 效果一览基本介绍模型设计程序设计参考资料 效果一览 基本介绍 Adaboost集成学习 | Matlab实现基于CNN-LSTM-Adaboost集成学习时间序列预测(股票价格预测) 模型设计 融合Adaboost的CNN-LSTM模型的时间序列预测,下面是一个基本的框架。 数据准备: 收集并整理用于时间序列预测的数据集。确保数据集包含时间序列的输入
ADABOOST做人脸检测程序与原理
ADABOOST做人脸识别原理+程序详解 **注意:**adaboost算法的目的是做一个目标检测,举个例子在人脸识别中,adaboost只能检测出一张图片中的人脸,并不能区分这些人脸分别是谁。 *1. 算法的整体流程* 人脸检测(face detection)是指对于任意一幅给定的图像,采用一定的策略对其进行搜索以确定其中是否有人脸,如果有人脸则返回人脸的位置、大小和姿态。 这是

从零开始理解AdaBoost算法:前向分布算法(四)【数学推导】
理解 AdaBoost 算法的原理 在理解 AdaBoost 算法原理的过程中,两个关键问题需要注意: 权重是如何由分类误差决定的。如何调整前一轮错误和正确的样本的权值。 优化问题 AdaBoost 解决的是二分类问题,数据集表示为: T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , … , ( x N , y N ) } T = \{(x_1, y_1), (
从零开始理解AdaBoost算法:设计思路与算法流程(二)【权值更新与加权表决、数学公式】
设计思路 AdaBoost算法属于Boosting算法家族中的一种,其基本思路是将多个弱分类器组合成一个强分类器。 “强分类器”是指一个分类准确率较高的模型“弱分类器”则是指分类准确率略高于随机猜测的简单模型。 AdaBoost的核心思想是通过 加权 的方式逐步提高分类器的性能。 首先来看AdaBoost的数学表达,使用的是 加法模型 : f ( x ) = ∑ m = 1 M α m

使用AdaBoost分类方法实现对Wine数据集分类
目录 1. 作者介绍2. 什么是AdaBoost?2.1 什么是弱分类器2.2 什么是强分类器2.3 如何自适应增强2.4 如何组合弱分类器成为一个强分类器? 3. 什么是Wine数据集3.1 Wine 数据集3.2 Wine 数据集结构 4. 使用AdaBoost分类方法实现对Wine数据集分类5. 完整代码 1. 作者介绍 赵俊旗,男,西安工程大学电子信息学院,2023级研究

实战07- 模型融合:利用AdaBoost元算法提高分类性能
元算法(meta-algorithm)是对其他算法进行组合的一种方式,即模型融合。 模型融合主要分为三种:Bagging、Boosting和Stacking。 思想:将弱分类器融合成强分类器,融合后比最强的弱分类器更好。 视频导学:https://www.bilibili.com/video/BV1y4411g7ia?p=8 参考: https://www.cnblogs.com/hithin

AdaBoost人脸检测训练算法 (中)
(3)采用AdaBoost算法选取优化的弱分类器 通过Adaboost算法挑选数千个有效的haar特征来组成人脸检测器,Adaboost算法中不同的训练集是通过调整每个样本对应的权重来实现的。 开始时,每个样本对应的权重是相同的,对于h1分类错误的样本,加大其对应的权重;而对于分类正确的样本,降低其权重,这样分错的样本就被突出出来,从而得到一个新的样本分布U2。 在新的样本分布下,

AdaBoost人脸检测训练算法 (上)
http://blog.csdn.net/hqw7286/article/details/5556767 前在实际中应用的人脸检测方法多为基于Adaboost学习算法的方法,这种检测方法最初由剑桥大学的两位大牛Paul Viola和Michael Jones[ViolaJones01]提出,并由另一位大牛英特尔公司的Rainer Lienhart[Lienhart02]对这一方法进
从 AdaBoost 到随机森林:深入解析集成学习方法【集成学习】
集成学习的思想 集成学习是一种通过组合多个基学习器(弱学习器)来提高模型预测性能的机器学习方法。集成学习的思想类似于谚语“三个臭皮匠,顶个诸葛亮”,即通过集成多个表现较差的学习器,可以获得一个强大的整体模型。 什么是学习器? 强学习器:如神经网络等,通常具有较高的预测准确性,但需要大量的数据和计算资源来训练。弱学习器:如逻辑回归等,个体性能较差,但计算代价低,容易训练。 集成学习的优点

《机器学习实战》(七)—— AdaBoost(提升树)
http://blog.csdn.net/u011239443/article/details/77294201 AdaBoost 提升树 例子 将“身体”设为A,“业务”设为B,“潜力”设为C。对该题做大致的求解: 这里我们只计算到了f2,相信读者也知道如何继续往下计算。这里特征的取值较少,所以直接使用是否等于某个取值来作为分支条件。实际中,可以设置是否

【机器学习】Adaboost: 强化弱学习器的自适应提升方法
🌈个人主页: 鑫宝Code 🔥热门专栏: 闲话杂谈| 炫酷HTML | JavaScript基础 💫个人格言: "如无必要,勿增实体" 文章目录 Adaboost: 强化弱学习器的自适应提升方法引言Adaboost基础概念弱学习器与强学习器Adaboost核心思想 Adaboost算法流程1. 初始化样本权重2. 迭代训练弱学习器3. 组合弱
AdaBoost与随机森林区别
AdaBoost 首先明确一个大方向:强可学习和弱可学习是等价的。所以,弱可学习方法可以提升为强可学习方法。AdaBoost最具代表性。 对于提升方法,有两个问题需要回答: 每一轮如何改变训练数据的权值或概率分布?如何将弱分类器组合成一个强分类器? AdaBoost的做法: 提高那些被前一轮弱分类器错误分类样本的权值,而降低那些被正确分类样本的权值。加权多数表决的方法,加大分类误