近似专题

csu1328(近似回文串)
题意:求近似回文串的最大长度,串长度为1000。 解题思路:以某点为中心,向左右两边扩展,注意奇偶分开讨论,暴力解即可。时间复杂度O(n^2); 代码如下: #include<iostream>#include<algorithm>#include<stdio.h>#include<math.h>#include<cstring>#include<string>#inclu

随即近似与随机梯度下降
一、均值计算 方法1:是直接将采样数据相加再除以个数,但这样的方法运行效率较低,要将所有数据收集到一起后再求平均。 方法2:迭代法 二、随机近似法: Robbins-Monro算法(RM算法) g(w)是有界且递增的 ak的和等于无穷,并且ak平方和小于无穷。我们会发现在许多强化学习算法中,通常会选择 ak作为一个足够小的常数,因为 1/k 会越来越小导致算法效率较低

Pytorch:Tensor基本运算【add/sub/mul/div:加减乘除】【mm/matmul:矩阵相乘】【Pow/Sqrt/rsqrt:次方】【近似:floor...】【裁剪:clamp】
一、基本运算:加减乘除 1、乘法 1.1 a * b:element-wise 对应元素相乘 a * b:要求两个矩阵维度完全一致,即两个矩阵对应元素相乘,输出的维度也和原矩阵维度相同 1.2 torch.mul(a, b):element-wise 对应元素相乘 torch.mul(a, b):是矩阵a和b对应位相乘,a和b的维度必须相等,比如a的维度是(1, 2),b的维度是(1,
用Java近似求pi,利用公式pi=4*(1-1/3+1/5-1/7+.....)
public class Welcome { public static void main(String[] args) { // TODO Auto-generated method stub double pi=0; double n=1; double sum=0; double k=1; while((pi-Math.PI)>0.0000001||(Math.PI-pi)>0.00000

【412】【统计近似相等数对 II】
差130个样例,等佬解 class Solution:def ifqual(self,str1,str2):return int(str1)==int(str2)def change(self,str1,str2):str1 = list(str1)n=len(str1)t=0for i in range(n):for j in range(i+1,n):str1[i],str1[j]=st

数学基础 -- 微积分之近似误差计算
微积分中的近似误差 在微积分中,近似计算是常见的工具,特别是在数值分析中。近似中的误差通常可以分为截断误差(truncation error)和舍入误差(round-off error)。以下是这两种误差的详细解释: 1. 截断误差 当使用有限项的级数或某种近似方法来代替实际的函数或积分时,未使用的部分会引入误差。举例来说,在使用泰勒级数展开函数时,只取有限的几项,那么未展开的项就会带来截断
![[M模拟] lc3265. 统计近似相等数对 I(模拟+代码实现+分类讨论+周赛412_2)](/front/images/it_default.gif)
[M模拟] lc3265. 统计近似相等数对 I(模拟+代码实现+分类讨论+周赛412_2)
文章目录 1. 题目来源2. 题目解析 1. 题目来源 链接:3265. 统计近似相等数对 I 2. 题目解析 这场周赛并没有参加,补下题。 T2 思路: 比较简单直接的一个模拟哈,数据量非常非常小,想怎么写都行。注意代码实现细节。 当 1001 与 11 此类时,因为允许前导零的存在,所以也是成立的。stoi 可以比较快速的将含有前导 0 的字符串转为 int,就不用

近似求阶乘-斯特林公式
今天做Factstone Benchmark这个题,需要阶乘的近似值,用常规方法就是TLE,虽然我避开求阶乘,用为完成的中间值做为判断条件进而避免了TLE,但是这样的方法还是感觉不靠谱,经过查阅,果然有种可以近似求阶乘的东西,斯特林公式。 (baidu)斯特林公式(Stirling's approximation)是一条用来取n的阶乘的近似值的数学公式。一般来说,当n很大的时候,n阶乘的计算量十
FAT:一种快速的Triplet Loss近似方法,学习更鲁棒的特征表示,并进行有噪声标签的提纯...
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶” 导读 Triplet的两大问题,计算复杂度和噪声敏感,看看这篇文章如何用一种对Triple的近似的方法来解决这两大问题。 摘要 三元组损失是ReID中非常常用的损失, 三元组损失的主要问题在于其计算上非常贵,在大数据集上的训练会受到计算资源的限制。而且数据集中的噪声和离群点会对模型造成比较危险的影响。这篇文章要解决的就是这两个问题,
chi-square, chi-distribute与Guassian distribute近似
chi-distribute is closer to Guassian distribute than chi-square.

转让闲置商标别中了残标,与驰名商标近似被驳回!
前几天有个人说要购买一个闲置的已注册商标,普推商标知产老杨帮忙去联系了一下,发现这个商标是残标用不成,他是要买回来的做化妆品的,但是在3类化妆品里面化妆品的小类并没有通过初审下证。 大家转让闲置商标就要注意了,看所需要的小类是不是通过出初审及下证,不仅是只看大的类别,那个商标闲置名称是三个汉字的,其的小类都过了,就是与化妆品及相关的小类没有关,这到底为何,经普推商标老杨详细检索发

线性代数|机器学习-P8矩阵低秩近似eckart-young
文章目录 1. SVD奇异值分解2. Eckart-Young2.1 范数 3. Q A = Q U Σ V T QA=QU\Sigma V^T QA=QUΣVT4. 主成分分析图像表示 1. SVD奇异值分解 我们知道,对于任意矩阵A来说,我们可以将其通过SVD奇异值分解得到 A = U Σ V T A=U\Sigma V^T A=UΣVT,通过 Σ \Sigma Σ中可以看

申请的商标名称相同或近似,如何解决!
最近遇到一些首次申请注册商标的主体,基本想的名称都是两个字或或者两个字加通用词,还有用的行业描述词或缺乏显著特征词,这样去申请注册商标,普推知产老杨分析这样去直接申请注册大概率驳回。 两个字基本上注册的差不多了,再加通用词还是等于两个字,还是有相同或高近,申请注册是大概率驳回,当然这种也有其它办法可以拿下。行业描述词或缺乏显著特征的词这样以驳回后,做驳回复审也没有机会,做了也会大概率驳回
近似最近邻搜索的QALSH方法-阅读笔记
近似最近邻搜索的QALSH方法 LSH和它的变体是解决高维欧氏空间下c-近似最近邻(c-ANN)搜索问题的著名索引方法。传统上,LSH函数在某种意义上是以未知查询的方式构建,即在任何查询到达之前划分桶。然而,距离一个查询越近的目标可能被划分在不同的桶中是令人不快的。由于利用yi遗忘查询桶划分,针对外存的最先进的LSH方案,即C2LSH和LSB森林,整数近似比率仅为c>=2。在这篇文章中,我们介

随机投影森林-一种近似最近邻方法(ANN)
转载自:http://blog.sina.com.cn/s/blog_7103b28a0102w1ny.html 当数据个数比较大的时候,线性搜索寻找KNN的时间开销太大,而且需要读取所有的数据在内存中,这是不现实的。因此,实际工程上,使用近似最近邻也就是ANN问题。其中一种方法是利用随机投影树,对所有的数据进行划分,将每次搜索与计算的点的数目减小到一个可接受的范围,然后建立多个随机
辛普森公式求函数的近似积分【通用计算】
利用辛普森公式可以近似求出复杂函数的积分值,公式如下: ∫ a b f ( x ) d x ≈ h 3 [ y 0 + y 2 n − 1 + 4 ( ∑ i = 1 n − 1 y 2 i − 1 ) + ∑ i = 1 n − 1 y 2 i ] \int_{a}^{b} f(x) dx \approx \frac{h}{3}\left[ y_0 + y_{2n-1} + 4(\sum\li
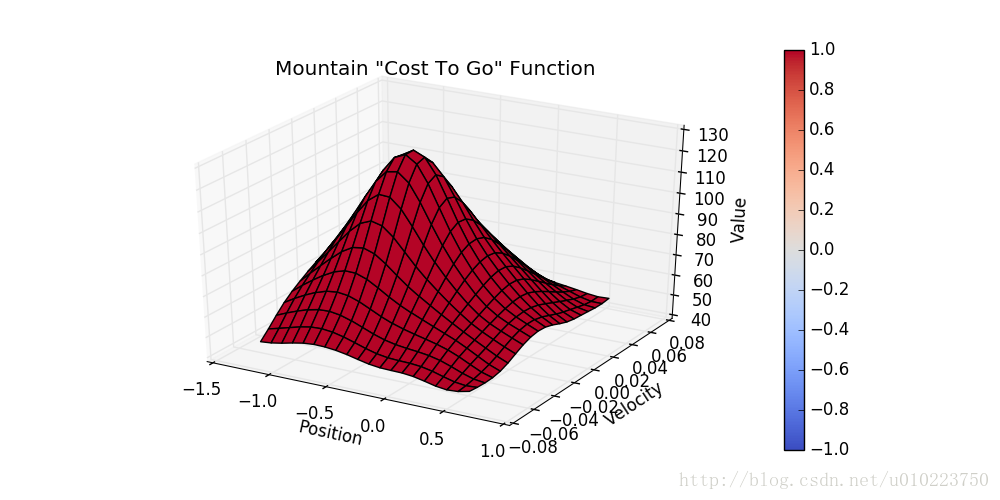
Reinforcement Learning强化学习系列之五:值近似方法Value Approximation
引言 前面说到了强化学习中的蒙特卡洛方法(MC)以及时序差分(TD)的方法,这些方法针对的基本是离散的数据,而一些连续的状态则很难表示,对于这种情况,通常在强化学习里有2中方法,一种是针对value function的方法,也就是本文中提到的值近似(value approximation);另一种则是后面要讲到的policy gradient。 值近似的方法 值近似的方法根本上是使用一个
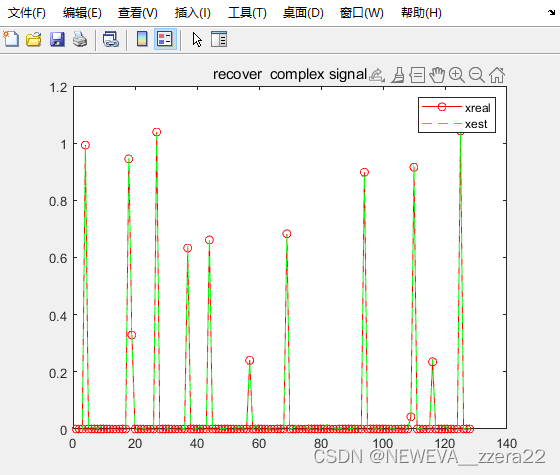
近似消息传递算法(AMP)单测量模型(SMV)
1、算法解决问题 很多人致力于解决SLM模型的求逆问题,即知道观测值和测量矩阵(字典之类的),要求未知变量的值。SLM又叫做标准线性模型,后续又在此基础上进行升级变为广义线性模型。即SLM是y=Ax+e,这里是线性关系,而到广义里可能就不单单只是Ax这个线性关系,可能是一个非线性函数y=F(x),此时就适合进一步的广义近似消息传递GAMP。并且在压缩感知CS出现后,又有很多人的兴趣转向与稀疏信号

Elasticsearch:理解近似最近邻 (ANN) 算法
作者:来自 Elastic Elastic Platform Team 如果你是在互联网出现之前长大的,你会记得找到新喜好并不总是那么容易。我们是在无意中听到收音机里的新乐队时发现他们的,是因为忘了换频道偶然看到一个新电视节目的,也是几乎完全依据游戏封面的图片来找到新喜欢的视频游戏的。 如今,情况大为不同。Spotify 会向我推荐符合我的口味的艺术家,Netflix 会突出显示它知道我们

详解 ROS 近似时间戳同步 ApproximateTime
ApproximateTime 功能介绍 message_filters::sync_policies::ApproximateTime 策略使用自适应算法根据时间戳来匹配多个Topic消息。 ApproximateTime根据时间戳来进行匹配,因此Topic的消息类型必须包含Header字段【C++】。 以下补充属性 以同步两个Topic为例,ApproximateTime至少会保证其
使用机器学习对非结构化数据加速查询(具有统计保证的近似选择查询)
作者:Daniel Kang, Edward Gan, Peter Bailis, Tatsunori Hashimoto, and Matei Zaharia 翻译:殷之涵 校对:方星轩 本文约2800字,建议阅读8分钟 本文以作者第一人称的方式向读者介绍了在2020年8月底对非结构化数据进行具有统计保证的近似选择查询方面所开展的工作,包含查询语义及查询背后的具体算法——如何在实现统计保证的
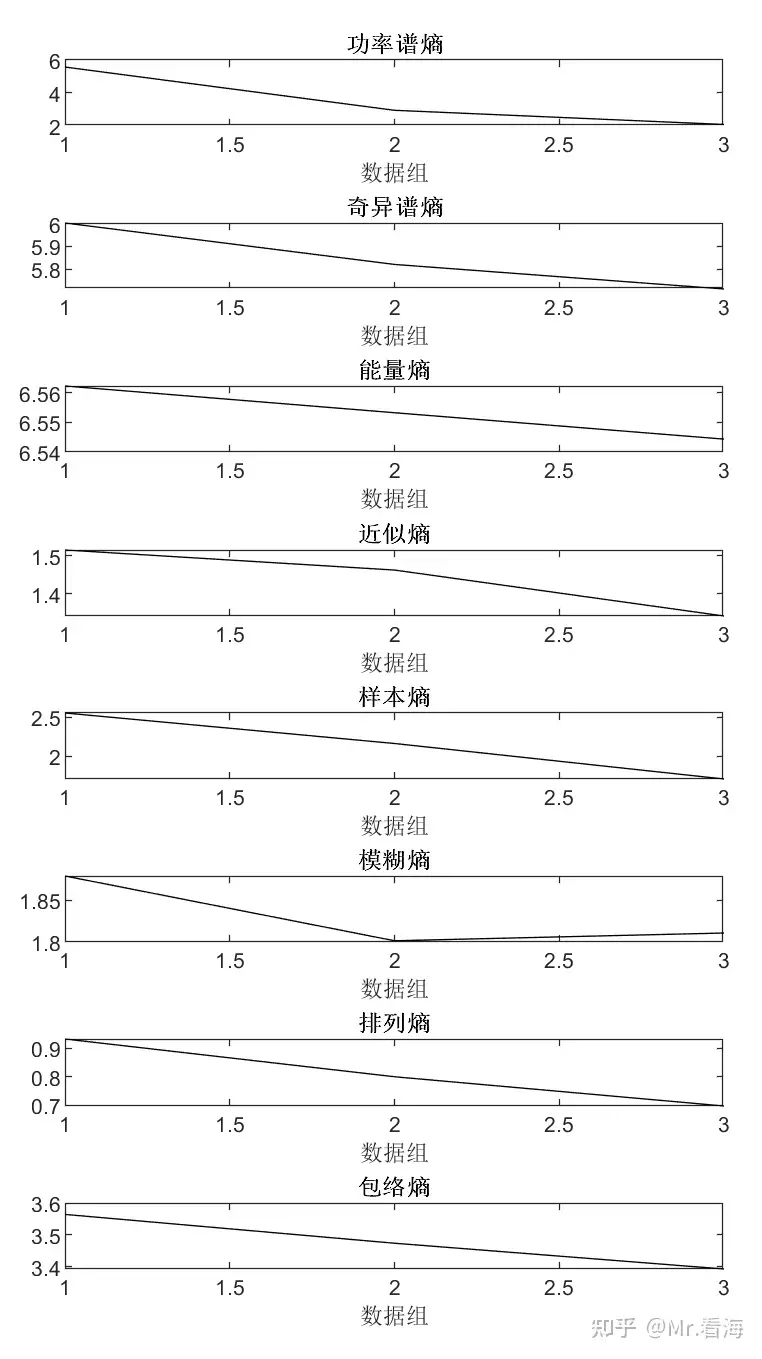
【熵与特征提取】从近似熵,到样本熵,到模糊熵,再到排列熵,包络熵,散布熵,究竟实现了什么?(第六篇)——“散布熵”及其MATLAB实现
今天讲散布熵,之前用了几篇文章分别讲述了功率谱熵、奇异谱熵、能量熵、近似熵、样本熵、模糊熵、排列熵、包络熵这8种类型的熵: Mr.看海:【熵与特征提取】基于“信息熵”的特征指标及其MATLAB代码实现(功率谱熵、奇异谱熵、能量熵) Mr.看海:【熵与特征提取】从近似熵,到样本熵,到模糊熵,再到排列熵,究竟实现了什么?(第一篇)——“近似熵”及其MATLAB实现 Mr.看海:【熵与特征提取】从
独家 | 使用机器学习对非结构化数据加速查询-第2部分(具有统计保证的近似选择查询)...
作者:Daniel Kang, Edward Gan, Peter Bailis, Tatsunori Hashimoto, and Matei Zaharia 翻译:殷之涵 校对:方星轩 本文约2800字,建议阅读8分钟 本文以作者第一人称的方式向读者介绍了在2020年8月底对非结构化数据进行具有统计保证的近似选择查询方面所开展的工作,包含查询语义及查询背后的具体算法——如何在实现统计保证的

微积分 重难点记录 四 近似积分 + 反常积分
微积分 重难点记录 见 微积分 重难点记录 知识点一: 知识点二: 中点定理就是根据中间点的值来计算积分值: 而Trapezoidal 则是利用了两个边界值的中值,所以如下图: 粉色表示中点定理的误差,蓝色表示Trapezoidal的误差,故中点的误差更小。 知识点三: 证明过程见书上。 知识点四: 题目五: 题目六:
使用阿里云试用Elasticsearch学习:2.4 深入搜索——近似匹配
使用 TF/IDF 的标准全文检索将文档或者文档中的字段作一大袋的词语处理。 match 查询可以告知我们这大袋子中是否包含查询的词条,但却无法告知词语之间的关系。 思考下面这几个句子的不同: Sue ate the alligator.The alligator ate Sue.Sue never goes anywhere without her alligator-skin purse.
[算法]简单的字符串近似匹配算法实现
GCC实现: /******************************************************************************* file: appmatch.cpp * brief: 字符串近似匹配算法实现 * 参照《柔性字符串匹配》6.2.2节 在文本中搜索 * creato