置信区间专题


区间预测 | Matlab实现EVO-CNN-SVM能量谷算法优化卷积神经网络支持向量机结合核密度估计多置信区间多变量回归区间预测
区间预测 | Matlab实现EVO-CNN-SVM能量谷算法优化卷积神经网络支持向量机结合核密度估计多置信区间多变量回归区间预测 目录 区间预测 | Matlab实现EVO-CNN-SVM能量谷算法优化卷积神经网络支持向量机结合核密度估计多置信区间多变量回归区间预测效果一览基本介绍程序设计参考资料 效果一览 基本介绍 1.Matlab实现EVO-CNN-SVM
文章解读与仿真程序复现思路——电力自动化设备EI\CSCD\北大核心《计及电-气园区综合能源系统多重不确定性的变置信区间优化调度 》
本专栏栏目提供文章与程序复现思路,具体已有的论文与论文源程序可翻阅本博主免费的专栏栏目《论文与完整程序》 论文与完整源程序_电网论文源程序的博客-CSDN博客https://blog.csdn.net/liang674027206/category_12531414.html 电网论文源程序-CSDN博客电网论文源程序擅长文章解读,论文与完整源程序,等方面的知识,电网论文源程序关注python
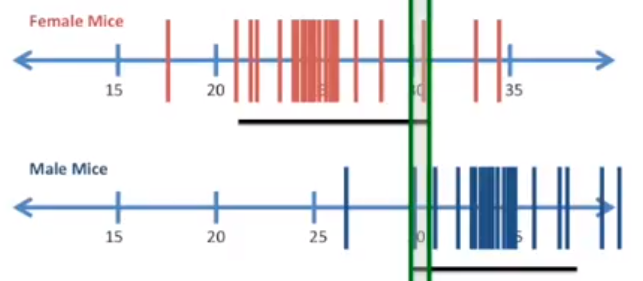
从零开始学统计 11 | 理解置信区间
置信区间 假设现在测量了12个小鼠体重的值,注意这里只测量了12只小鼠(样本),而不是地球上的每一只小鼠(总体) 取12个测量值,计算平均值,注意这里是样本均值,而不是总体均值(地球上所有小鼠的均值) 理解样本均值与总体均值:https://zhenglei.blog.csdn.net/article/details/108392410 但是,我们可以通过 Bootstrap 方法,

【机器学习荐货情报局】置信区间-看这一篇就够了
置信区间 - 看这一篇就够了 欢迎关注公众号:机器学习荐货情报局 一起进步,一起学习,一起充电~ 欢迎投稿,讨论,拍砖 1. 定义 在统计学中,一个样本的置信区间是对总体参数的一个区间估计。置信区间给出的是,声称总体参数的真实值在测量值的区间所具有的可信程度或者说是概率。这个概率又叫做置信水平。举例来说:再一次大选中,上帝视角看到某人的支持率是55%,而置信水平0.95上的置信区间是

数据分析的几个数值P值、T值和R值(相关系数)中位数、众数、 方差、 标准差、 协方差、 置信区间
统计学中包含了多个基本概念和数值,以下是关于P值、T值和R值(相关系数)的简要解释,以及其他一些常见的统计学数值: P值(P value): P值是用来判定假设检验结果的一个参数。它表示在原假设为真时,比所得到的样本观察结果更极端的结果出现的概率。如果P值很小,说明原假设情况的发生的概率很小,而如果出现了,根据小概率原理,我们就有理由拒绝原假设。P值越小,拒绝原假设的理由越充分。 T值(T-
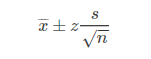
数理统计中95%置信区间的含义
95%置信区间,意味着如果你用同样的步骤,去选样本,计算置信区间,那么100次这样的独立过程,有95%的概率你计算出来的区间会包含真实参数值,即大概会有95个置信区间会包含真值。而对于某一次计算得到的某一个置信区间,其包含真值的概率,我们无法讨论。参源 1.点估计与区间估计 首先我们看看点估计的含义: 是用样本统计量来估计总体参数,因为样本统计量为数轴上某一点值,估计的结果也以一个点的数值表
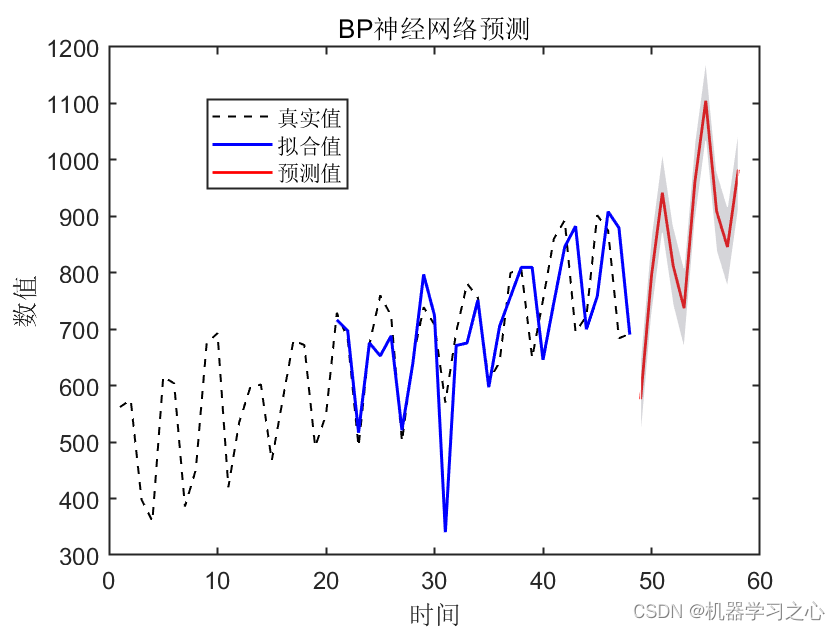
区间预测 | Matlab实现带有置信区间的BP神经网络时间序列未来趋势预测
区间预测 | Matlab实现带有置信区间的BP神经网络时间序列未来趋势预测 目录 区间预测 | Matlab实现带有置信区间的BP神经网络时间序列未来趋势预测预测效果基本介绍研究回顾程序设计参考资料 预测效果 基本介绍 BP神经网络(Backpropagation neural network)是一种常用的人工神经网络模型,用于解决各种问题,包括时间序列预测。时间
置信概率的含义如何?与置信区间有何关系?
http://cal.ceprei.com/news_details.asp?id=219&category_id=11 按测量不确定度的定义,合理赋予被测量之值的分散区间是包括全部被测量的测量结果的,即测量结果100%存在于这一区间。这一分散区间的半宽一般用a表示。但是如只要求某个区间只包含其95%的赋予被测量之值,这个区间就称为概率p=95%的置信区间,其半宽就是扩展不

置信区间(confidence interval)
置信区间(confidence interval) 1、对于具有特定的发生概率的随机变量,其特定的价值区间------一个确定的数值范围(“一个区间”)。 2、在一定置信水平时,以测量结果为中心,包括总体均值在内的可信范围。 3、该区间包含了参数θ真值的可信程度。 4、参数的置信区间可以通过点估计量构造,也可以通过假设检验构造。 http://bbs.antpedia.com/vi
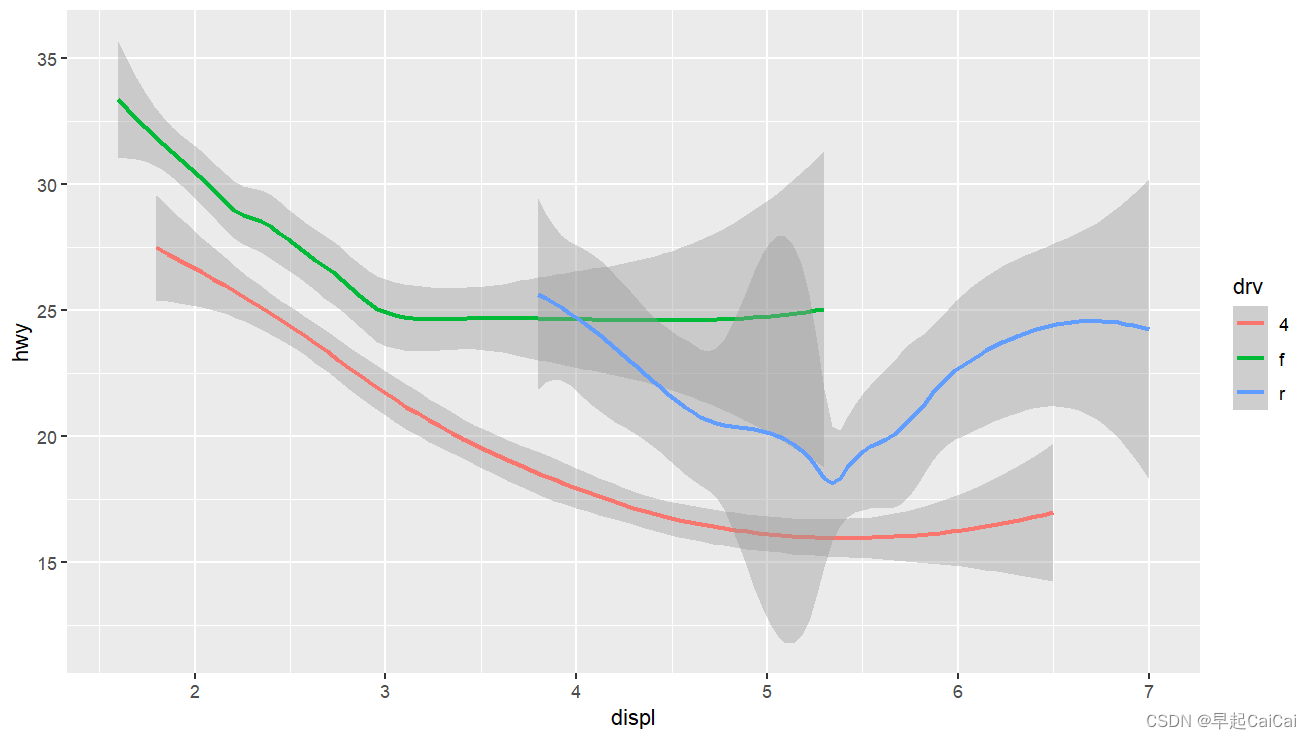
R语言学习case12:ggplot 置信区间(多线型)
接上文:多条曲线 R语言学习case11:ggplot 置信区间(包含多子图) 在ggplot2中,每个geom函数都接受一个映射参数。然而,并非每个美学属性都适用于每个geom。你可以设置点的形状,但不能设置线的“形状”。另一方面,你可以设置线的线型。geom_smooth()将为您映射到线型的每个唯一值绘制不同的线,具有不同的线型。 单一曲线 ggplot(data = mpg) + g
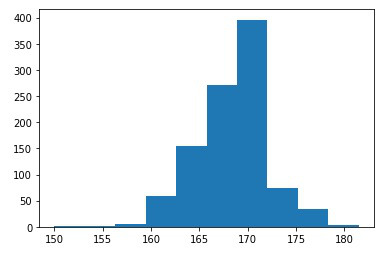
如何在Python中绘制置信区间?
置信区间是从观测数据的统计量计算的一种估计值,它给出了一个可能包含具有特定置信水平的总体参数的值范围。 平均值的置信区间是总体平均值可能位于其间的值的范围。如果我预测明天的天气在零下100度到+100度之间,我可以100%肯定这是正确的。然而,如果我预测温度在20.4到20.5摄氏度之间,我就不那么有信心了。注意置信度如何随着区间的减小而减小。这同样适用于统计置信区间,但它们也依赖于其他因素。
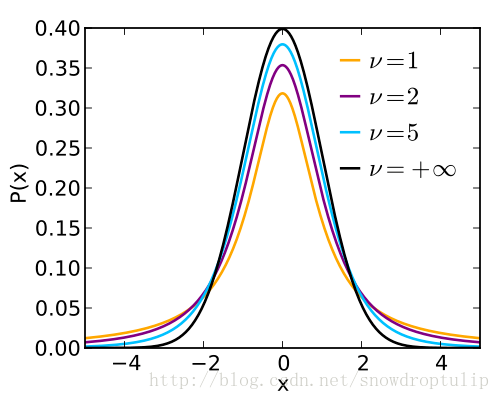
统计学——小样本容量置信区间
一般来讲,n<30,不能进行好的估计,针对这种情况,给出t distribution对sample mean分布进行修正。 T分布和正态分布相似,具有fatter tail,因为低估了S。对应的,不再去查z table,而是去查t table。T table的列为自由度degrees of freedom,即n-1。 有些记法在上面加了个帽子记为,表示这是由样本标准差估算出来的sample
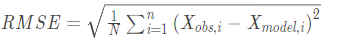
如何计算置信区间,RMSE均方根误差/标准误差:误差平方和的平均数开方
如何通过部分样本来计算总体的一个置信区间呢?主要有下面几个步骤: step1:首先明确要求解的问题。就是你要预估什么?不管是全校学生身高还是学生成绩。 step2:求抽样样本的平均值与标准误差(standard error,RMSE,均方根误差)。注意标准误差与标准差(standard deviation)不一样(标准差反映了整个样本对样本平均数的离散程度,标准误差反映样本平均数对总体平均
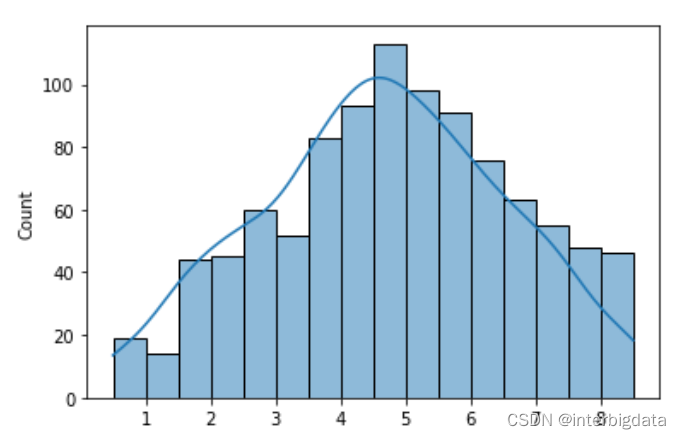
数据分析为何要学统计学(4)——何为置信区间?它有什么作用?
置信区间是统计学中的一个重要工具,是用样本参数()估计出来的总体均值在某置信水平下的范围。通俗一点讲,如果置信度为95%(等价于显著水平a=0.05),置信区间为[a,b],这就意味着总体均值落入该区间的概率为95%,或者以95%的可信程度相信总体均值在这个范围内。 一般情况下当我们抽样的数量大于等于30时,可认为样本均值服从正态分布,以此我们通过查标准正态分布表,获得显著水平a下的z值,用以下
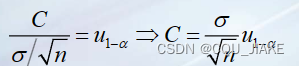
11.6区间估计、置信区间
已知总体方差 就是说,在总体里随机取样的时候,取样的均值服从总体的均值,方差为总体均值方差与样本量比值的正态分布,样本量越小,方差越大,样本量越大,方差越小,取样的样本均值浮动越小,越接近于总体的均值 注意是任何一个分布,任何一个总体都可以以此来接近 或者说以此从总体取的样本来估计总体的样本均值 如果总体分布就是正态分布,那么就不是近似,就是准确 方差是未知 总体方差不知道,均值也不知

数据分享|R语言Bootstrap、百分位Bootstrap法抽样参数估计置信区间分析通勤时间和学生锻炼数据...
全文链接:http://tecdat.cn/?p=27505 本文展示了如何使用 R 构建Bootstrap自举置信区间的示例。还强调了 R 包 ggplot2 用于图形的用途。但是,在学习Bootstrap程序和 R 语言时,学习如何在没有包的情况下从头开始应用Bootstrap程序有助于更好地理解 R 的工作原理并加强对Bootstrap的概念理解。 相关视频 具有标准误差的bootstra
![[转] R 置信区间、预测区间差别](/front/images/it_default.jpg)
[转] R 置信区间、预测区间差别
原文地址: https://www.cnblogs.com/100thMountain/p/5539024.html Ask: 什么是预测区间,置信区间和预测区间二者的异同是什么? Answer: 置信区间估计(confidence interval estimate):利用估计的回归方程,对于自变量 x 的一个给定值 x0 ,求出因变量 y 的平均值的估计区间。预测区间估计(predic
Java实现Fisher‘s Exact Test 的置信区间的计算
实现代码 package com.bgi.aigi.common.utils;public class FisherExactUtils {public static double[] getConfidenceInterval(double[][] data) {if (data==null||data.length!=2||data[0].length!=2||data[1].length
Java实现Fisher‘s Exact Test 的置信区间的计算
实现代码 package com.bgi.aigi.common.utils;public class FisherExactUtils {public static double[] getConfidenceInterval(double[][] data) {if (data==null||data.length!=2||data[0].length!=2||data[1].length
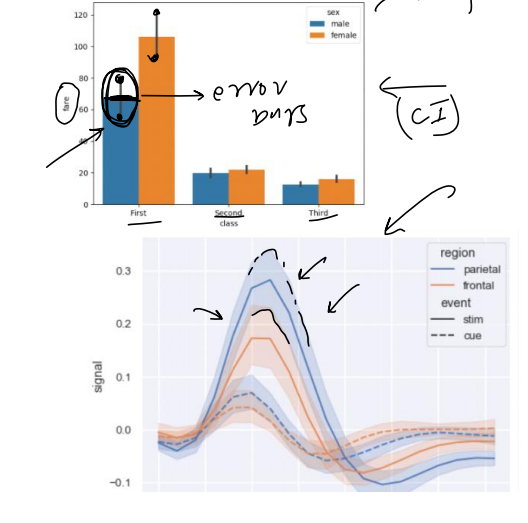
【统计学概念】初学者指南:了解置信区间
一、说明 什么是置信区间?如何将概率转化成信心度?信心度如何去工作?这些初步的统计概念需要明晰,然后才能应用统计模型,然后是贝叶斯推理,我们将逐步深入这些概念。 二、总体与样本个体统计 总体是研究人员想要研究或得出结论的整个群体或一组个人、物体或事件。它可以是人,动物,
置信系数 表达了置信区间的计算_大家的资产组合合理吗?股票计算风险值VaR|历史模拟蒙特卡罗...
概念 资产组合的概念是指的:有资产在手的人对其持有的各种股票、债券、基金、现金及其他资产进行的合理组合。通过对资产的合理搭配,可以保证一定水平的盈利,还能把投资风险降到最低。 证券投资中,高收益往往伴随着高风险,人们期望收益越高越好,但是由于每种证券都有风险,若只考虑追求收益,资产过分集中和单一,一旦出现股票大跌,遭受损失的程度就会越大。因此,通过科学的分析和评估,将证券投资进行合理的搭配
置信区间的置信区间_R:自举置信区间
置信区间的置信区间 最近,我在Julia Evans的博客上遇到了一篇有趣的文章,展示了如何通过对我们实际上使用bootstrapping 的一小部分数据点进行采样来生成更大的数据点集 。 Julia的示例全部使用Python,因此我认为将它们转换为R是一个有趣的练习。 我们正在进行引导,以模拟一次航班的未出现次数,因此我们可以算出可以超额预定飞机的座位数。 我们从一小部分未
从零开始学统计 11 | 理解置信区间
置信区间 假设现在测量了12个小鼠体重的值,注意这里只测量了12只小鼠(样本),而不是地球上的每一只小鼠(总体) 取12个测量值,计算平均值,注意这里是样本均值,而不是总体均值(地球上所有小鼠的均值) 理解样本均值与总体均值:https://zhenglei.blog.csdn.net/article/details/108392410 但是,我们可以通过 Bootstrap 方法,