本文主要是介绍11.6区间估计、置信区间,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
已知总体方差
就是说,在总体里随机取样的时候,取样的均值服从总体的均值,方差为总体均值方差与样本量比值的正态分布,样本量越小,方差越大,样本量越大,方差越小,取样的样本均值浮动越小,越接近于总体的均值
注意是任何一个分布,任何一个总体都可以以此来接近
或者说以此从总体取的样本来估计总体的样本均值
如果总体分布就是正态分布,那么就不是近似,就是准确
方差是未知
总体方差不知道,均值也不知道,就随机取样
取样的样本均值和方差知道后,那么T就满足一个t分布
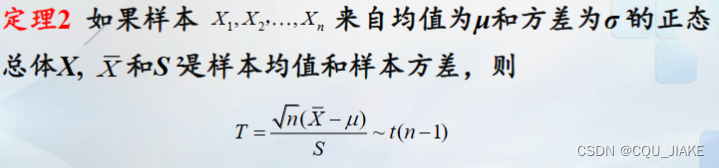

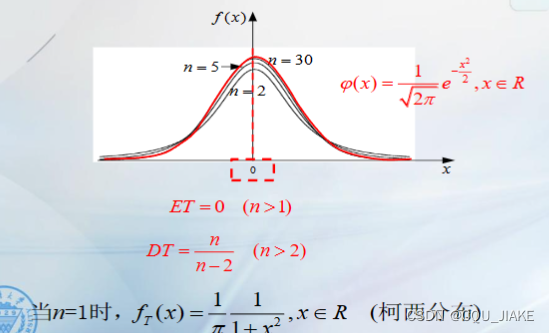
n越大,即样本量越大,那么越接近总体方差,也就是说,也靠近方差已知的情况,即正太分布
而如果n较小,相比正太分布,就比较平,越容易取到两侧的极值
总而言之,t分布就是在总体方差也不知道时,一种比较兜底的假设,它比方差已知时,更要假设两侧的极端量容易出现,但是随着样本量的增大,就越接近总体方差已知的情况
t分布适合小样本时的统计推断
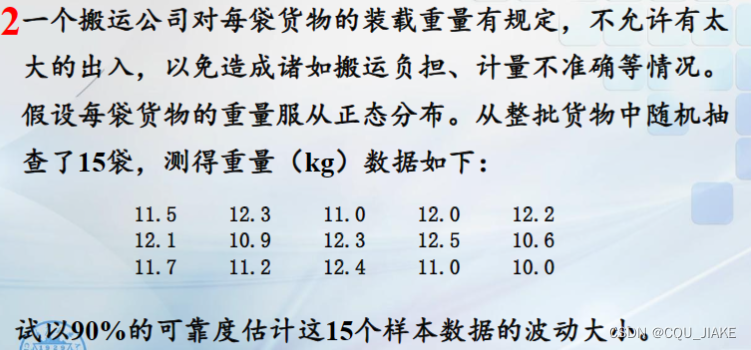
就是要以样本的方差估计总体的方差,即根据样本的波动程度估计总体的数据波动程度
估计的可靠度为90,是说



置信区间就是说,在一定置信度的情况下,即有置信度的把握可以肯定,参数确实位于这个区间里,这个区间就叫做置信区间。

显著性水平越高,那么置信度越低,把握越低。显著水平就是说,真实参数不落在置信区间里的概率。置信度是说真实参数落在置信区间里的概率

精度可以选择就是说,对于不同的区间,我都有相同的把握可以肯定参数确实在我所说的这个区间里。就是说区间上下限变,但落在的概率不变
置信度只是说估计正确的概率;精确度是说区间长度,区间越短,精度越高
称量出的结果最有可能的就是实际参数值,也就是正态分布的均值,
对参数的估计,要知道参数的分布,近似为以实际值为均值的正太分布
1-α的置信度就是说,把出现结果的所有情况的概率都加起来,最后等于1-α,那么就有1-α的把握认为真实参数在这个区间里
那么精度就是说参数在这个选取的置信区间里出现的所有可能的概率的累加和
如果选的比较偏,即偏离实际的参数,那么所需要的区间也就越大,在保证最后出现的概率累加和一定,也即置信度一定的情况下,精度就越小,区间长度长
但如果选的比较正,即区间里框起来的都是参数出现概率很大的点,那么就需要囊括较少的点就可以达到一定的可信度,此时区间长度就小,精度就高
也就是说,置信度一定,精确度即区间长度不一定
所谓置信度就是区间里的点出现概率的累加和,如果包括全部点,那么置信度就是100.本身就是描绘真实参数在所选区间里的概率。
最小的区间长度就是最接近实际参数的两端,也即均值两侧
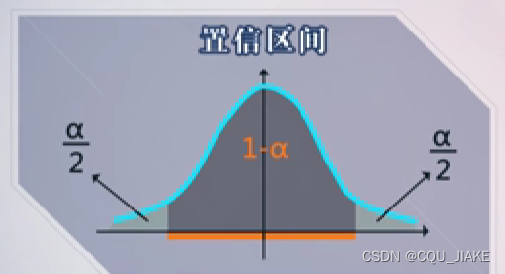

先设了一个置信区间,这个区间的上下限都不知道
然后假定一个置信度,一般置信度越高,区间长度越长,精度越低;置信度越低,区间长度越小,精度越高。
接着,根据参数的分布情况,根据分布的特点,选出这个置信度水平下,区间长度最短,即精度最高的一个区间,选取方式按分位点,就是两个分位点夹在一起的部分概率和为置信度,也就是说两个分位满足差为置信度,同时要保证两个分位点之间的距离最短
对于正太分布而言,就是均值两侧,左右两端分别为二分之α
查表得到分位点在标准分布下坐标轴的具体值,然后解就得到了区间估计
也即有1-α的把握认为实际参数在这个区间里

由于正态分布是对称的,所以查表查左侧的一个二分之α就可以,这个查表,就是去查分布函数,分布的率累和为二分之α,这里0.025查出来是-1.96,由于对称,所以就绝对值,即在-1.96和1.96两个左右二分之α分位点之间,之后就求解
s是收入,ES是给出去钱的均值
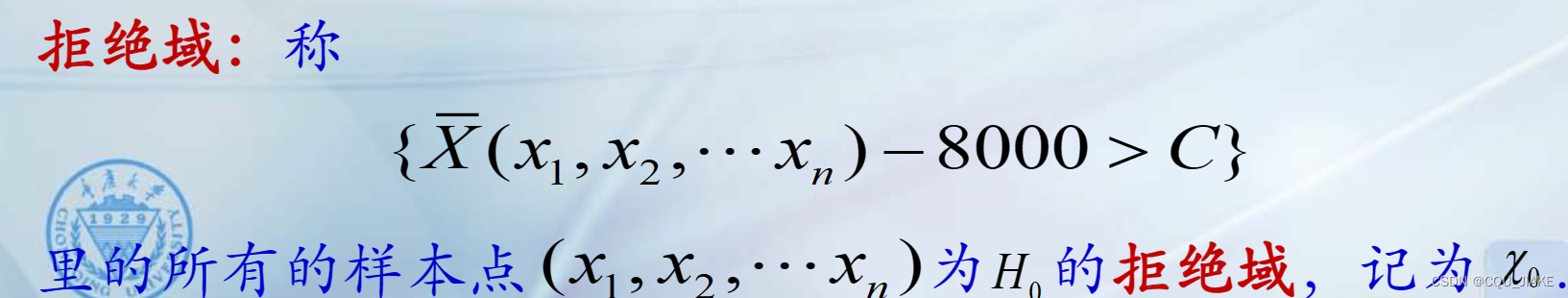
小概率α为显著水平
重点在于临界值的确定
就是样本的实际情况和假设值存在某种关系,要描述这个某种关系,需要临界值,临界值根据小概率事件发生的概率,即显著水平α确定
其中重要的一步是把其化为标准正态分布
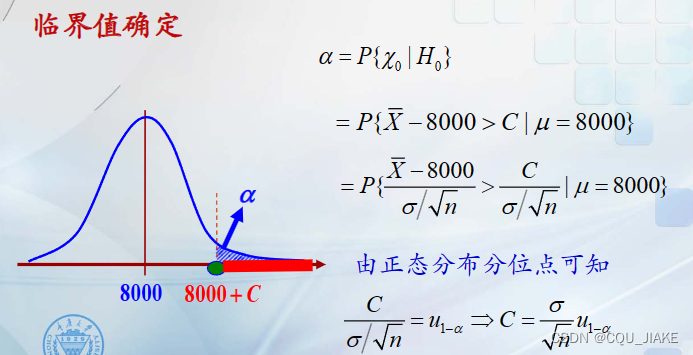
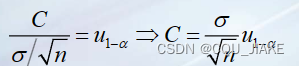
这个就是核心等式
这篇关于11.6区间估计、置信区间的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




