炼丹专题

【炼丹经验积累(一)】梯度消失 学习率自动调节 附代码
问题描述 对 stable diffusion 3 进行 ip-adapter 微调,正常训练 2 w 步后,loss 出现不稳定状态,并出现 Not a number问题定位:由于 loss 并没有变成无限大(梯度爆炸),那么应该是梯度消失。 解决方案 降低学习率 参考 huggingface 官方论坛1,其中有用户提到:“我也遇到过几次了。就我而言,我能够通过降低学习率来解决这个问题
Lora基础炼丹学习笔记
1、收集数据集 20-30张人物各个角度、各个姿势的图片 2、图片预处理 裁剪 + 打标签 裁剪必须也要512 * 512 ,因为sd1.5就是用这个尺寸训练的,可以使用后期处理 打标可以勾选这个,Deepbooru对二次元画风更友好 打标也可以使用wb14-tagger的批量处理反推,注意下面的附加标签要填写你要出发的词 3、训练 选择指定的底模,底模的推荐如下
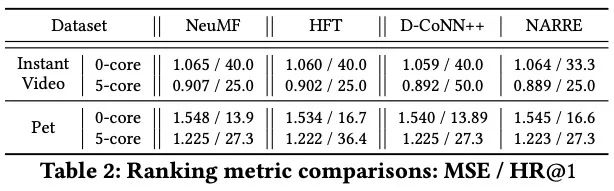
推荐系统炼丹笔记:多模态推荐之用户评论篇
作者:一元 公众号:炼丹笔记 目前非常多的推荐系统主要使用用户的一些基础反馈信息来作为最终的标签进行模型的训练,例如点击/购买等,但是却鲜有文章去进一步挖掘用户的其它反馈,例如用户对于该产品的评论,很多的评论相较于点击等反馈更加具有表示性,比如你经常向一个用户推荐一类商品,该商品虽然点击率很高,但是该用户之前已经评论了恶心之类的,这么继续推下去的化很可能使得该用户不再使用该软件。 所以推荐

EPSANet:金字塔切分注意力网络,有效的即插即用炼丹模块【原理讲解及代码!!!】
EPSANet:一种高效的金字塔切分注意力网络 一、引言 在深度学习领域,注意力机制已经成为提升卷积神经网络性能的关键技术。其中,一种新型网络结构——EPSANet,通过引入金字塔切分注意力(Pyramid Split Attention, PSA)模块,为注意力机制的研究和应用提供了新的思路。EPSANet不仅在图像识别任务中表现出色,还在计算参数量上实现了高效性。 二、PSA模块的设计

深度学习如炼丹,你有哪些迷信做法?网友:Random seed=42结果好
来源:机器之心本文约2200字,建议阅读9分钟调参的苦与泪,还有哪些“迷信的做法”? 每个机器学习领域的研究者都会面临调参过程的考验,当往往说来容易做来难。调参的背后往往是通宵达旦的论文研究与 GitHub 查阅,并需要做大量的实验,不仅耗时也耗费大量算力,更深深地伤害了广大工程师的头发。 有人不禁要问:调参是门玄学吗?为什么模型明明调教得很好了,可是效果离我的想象总有些偏差。 近日,re
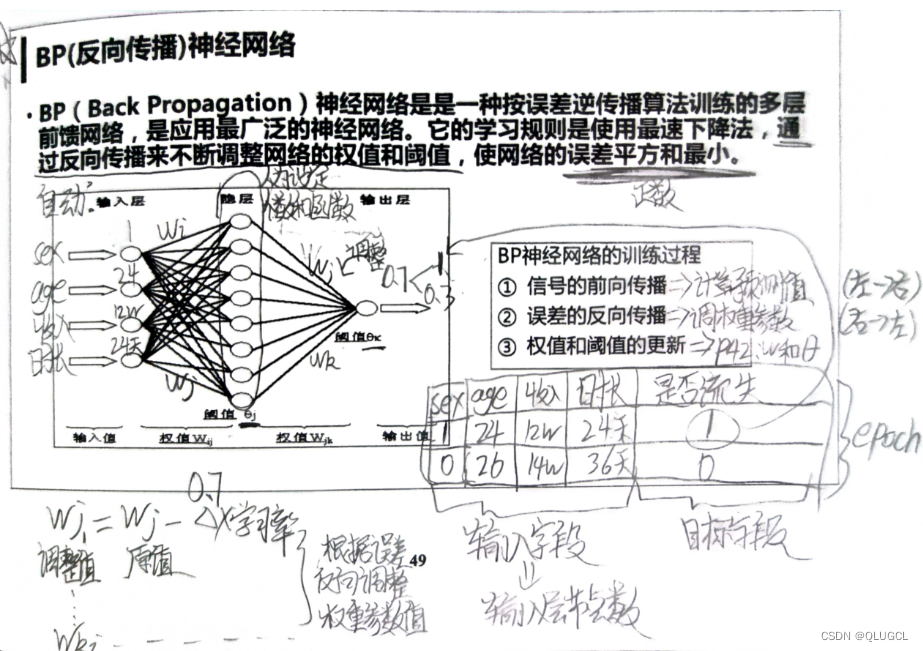
模型训练基本概念-赛博炼丹
文章目录 拓展知识基础名词解释(语义库更新)机器学习任务流程模型训练基本流程模型训练详细流程正向传播与反向传播正向传播-求误差值反向传播-求参数值 学习率激活函数激活函数-为什么希望激活函数输出均值为0?激活函数 — softmax & tanh激活函数 — ReLU(MVP:简单粗暴)激活函数 — Swish(ReLU进阶版,用的最多) 损失函数损失函数 — MSE & MAE损失函数 —
![[调参]CV炼丹技巧/经验](https://img-blog.csdnimg.cn/20181221165743991)
[调参]CV炼丹技巧/经验
转自:https://www.zhihu.com/question/25097993 我和@杨军类似, 也是半路出家. 现在的工作内容主要就是使用CNN做CV任务. 干调参这种活也有两年时间了. 我的回答可能更多的还是侧重工业应用, 技术上只限制在CNN这块. 先说下我的观点, 调参就是trial-and-error. 没有其他捷径可以走. 唯一的区别是有些人盲目的尝试, 有些人思考后再尝试.

炼丹!训练 stable diffusion 来生成LoRA定制模型
LoRA,英文全称Low-Rank Adaptation of Large Language Models,直译为大语言模型的低阶适应,这是微软的研究人员为了解决大语言模型微调而开发的一项技术。 比如,GPT-3有1750亿参数,为了让它能干特定领域的活儿,需要做微调,但是如果直接对GPT-3做微调,成本太高太麻烦了。 LoRA的做法是,冻结预训练好的模型权重参数,然后在每个Transfor
![[嵌入式AI从0开始到入土]5_炼丹炉的搭建(基于wsl2_Ubuntu22.04)](https://img-blog.csdnimg.cn/direct/971108e55b2f48f0b2802e72653b00e5.png)
[嵌入式AI从0开始到入土]5_炼丹炉的搭建(基于wsl2_Ubuntu22.04)
[嵌入式AI从0开始到入土]嵌入式AI系列教程 注:等我摸完鱼再把链接补上 可以关注我的B站号工具人呵呵的个人空间,后期会考虑出视频教程,务必催更,以防我变身鸽王。 第一章 昇腾Altas 200 DK上手 第二章 下载昇腾案例并运行 第三章 官方模型适配工具使用 第四章 炼丹炉的搭建(基于Ubuntu23.04 Desktop) 第五章 炼丹炉的搭建(基于wsl2_Ubuntu22.04)

一份保姆级的 Stable Diffusion 部署教程,开启你的炼丹之路
市面上有很多可以被用于AI绘画的应用,例如DALL-E、Midjourney、NovelAI等,他们的大部分都依托云端服务器运行,一部分还需要支付会员费用来购买更多出图的额度。 在2022年8月,一款叫做Stable Diffusion的应用,通过算法迭代将AI绘画的精细度提上了一个新的台阶,并能在以秒计数的时间内完成产出,还可以在一台有“民用级”显卡的电脑上运行。 通过Stable Di

【炼丹神器】wandb实践之sweep超参扫描工具
文章目录 一、四步上手wandb二、四步玩转sweep 参考官方文档:https://docs.wandb.ai/guides/sweeps/define-sweep-configuration 一、四步上手wandb 首先,wandb其实类似tensorboard,mindinsight,都是观察训练时的学习率,训练loss、验证loss等指标以了解训练进程的工具

这里有一份炼丹秘籍!
Datawhale干货 作者:欧泽彬,西湖大学,来源:极市平台 文章导读 炼丹总是效率低下该怎么办?本文作者总结了自己多年来的炼丹经验,给大家提供了一些常见问题的解决方法和一套自建的工作流程。 来源丨https://zhuanlan.zhihu.com/p/482876481 炼丹多年,辗转在不同地方待过,发现还是有相当部分的小伙伴在手动敲命令开所有的实验。高效一点的操作是写一个 bas

炼丹学习笔记1---openPCDet训练配置参数含义介绍
背景:最近偷闲学习openPCDet,记录一下基本训练可能用到的一些配置。以下为个人学习探索,仅供参考。 1、cfg_file 含义: 指定用于训练的配置文件,其中包含了模型、优化器、学习率等相关的配置信息。 作用: 通过配置文件统一管理各种超参数,方便在不同的实验中灵活调整模型和训练设置。 2、batch_size 含义: 每个训练步中用于更新模型参数的样本数。 作用: 控制模型参数的更

AI 实战 | 机器学习元年| 中英文你想看哪个 | 一起回炉炼丹吗 |
吴恩达《Machine Learning Yearning》中文 And 英文版,你还在纠结看哪个版本吗 你想看的,咱都有,客官,快来炼丹 你是从吴恩达老师的机器学习和深度学习课程开始入坑的吗 我的答案没有一秒钟犹豫: Yes ,you are so clever … 文章目录 一段话开篇一段话,剩下全看图获取途径如下: 一段话 17年,我开始真正关注和入坑

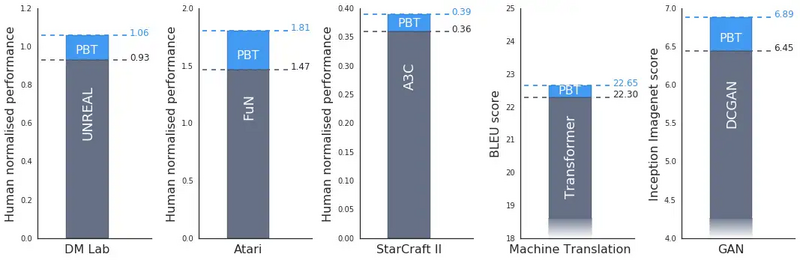
python炼丹师是什么意思_Ray Tune: 炼丹师的调参新姿势
在机器学习的大多数漂亮的结果背后,是一个研究生(我)或工程师花费数小时训练模型和调整算法参数。正是这种乏味无聊的工作使得自动化调参成为可能。 在 RISELab 中,我们发现越来越有必要利用尖端的超参数调整工具来跟上最先进的水平。深度学习性能的提高越来越依赖于新的和更好的超参数调整算法,如基于分布的训练(PBT) ,HyperBand,和 ASHA。 Source: 基于分布的训练大大提高了
python炼丹师_python炼丹师_python操作excel
几种常用模块的使用方法 注释:Excel 2003 即XLS文件有大小限制即65536行256列,所以不支持大文件,而Excel 2007以上即XLSX文件的限制则为1048576行16384列 下面则为几种模块的使用: 1.xlwt 写入xls文件内容 import xlwt book = xlwt.Workbook() # 新建工作簿 table = book.add_sheet('Ov

唠一唠对AI炼丹师的模型部署探索(onnx)
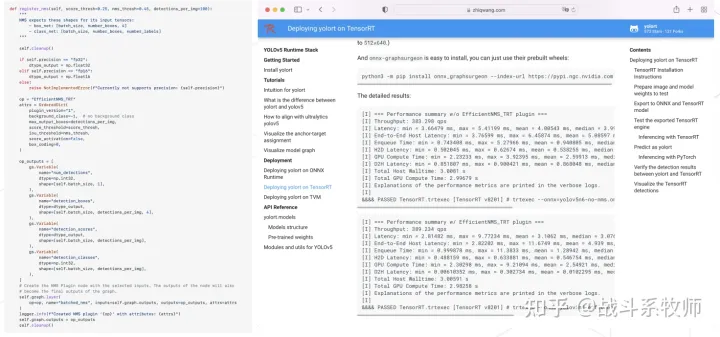
点击上方“小白学视觉”,选择加"星标"或“置顶” 重磅干货,第一时间送达 编者荐语 说到推理和部署,其实怎么也绕不开ONNX,ONNX在成立的初衷就是希望解决神经网络在不同的训练框架、推理框架上的转换问题。 作者丨战斗系牧师@知乎 链接丨https://zhuanlan.zhihu.com/p/557709588 说在前面的话 首先肯定是非常感谢 @OpenMMLab 能够给我这个小菜鸡

如何成为一名成功的“炼丹师”——DL训练技巧
关注并星标 从此不迷路 计算机视觉研究院 、. 学习群|扫码在主页获取加入方式 今天给大家讲讲DNN(深度神经网络)在训练过程中遇到的一些问题,然后我们应该怎么去注意它,并学会怎么去训练它。 1、数据集的准备: 必须要保证大量、高质量且带有准确标签的数据,没有该条件的数据,训练学习很困难的(但是最近我看了以为作者写的一篇文章,说明不一定需要大量数据集,也可以训练的很好,有空和大家来分享其思
yellowbrick牛逼,机器学习“炼丹师”、“调参侠”们有福了
yellowbrick是机器学习工具Scikit-Learn的扩展,通过几行代码可视化特征值、模型、模型评估等帮助“调参侠”们更便捷的的选择机器学习模型和调参,依赖Matplotlib和Scikit-Learn。 目录 yellowbrick安装 yellowbrick核心“武器” - Visualizers

基础入门:“炼丹师”——深度学习训练技巧
关注并星标 从此不迷路 计算机视觉研究院 公众号ID|ComputerVisionGzq 学习群|扫码在主页获取加入方式 计算机视觉研究院专栏 作者:Edison_G 深度学习已经成为解决许多具有挑战性的现实世界问题的方法。对目标检测,语音识别和语言翻译来说,这是迄今为止表现最好的方法。许多人将深度神经网络(DNNs)视为神奇的黑盒子,我们放进去一堆数据,出来的就是我们的解决方案!事实上,事
唠一唠对AI炼丹师的模型部署的探索
1、内容介绍 这期内容是@走走大佬关于目标检测模型End to End推理方案的探索和尝试。其实说到推理和部署,其实怎么也绕不开ONNX,ONNX在成立的初衷就是希望解决神经网络在不同的训练框架、推理框架上的转换问题。 所以本期的内容会从如何玩转ONNX出发,唠一唠,我们在目标检测部署遇到的那些事情。因为篇幅以及有部分内容我不太了解不敢乱说的关系,我会在这里对开放麦的内容做一点顺序和内容上进行一
不做“炼丹师”,听产业、高效、政府的大咖聊AI人才培养 | AI TIME
AI教育与人才培养 2020年7月04日 15:30-17:00 近年来,随着AI行业的快速发展,AI人才缺口巨大,AI专业教育异常火爆。 在学校教育方面,2018年,教育部首次设立了人工智能专业(专业代码080717T)。2019年3月,35所高校获首批人工智能专业建设资格。到了2020年3月,新增180所高校获批新增人工智能本科专业。开设人工智能本科专业的高校达到215 所。
一周新闻盘点!AI炼丹师即将转正,谷歌乳腺癌AI筛查引争议,达摩院发布2020十大科级趋势,小米摄像头被曝漏洞!
2020年的第一周,也是2019的最后一周,出现了很多劲爆新闻。小编不得不感慨:身处AI所带来的这波科技浪潮中,真是想停下歇歇脚都不行。本周新闻盘点包括:人社部发布人工智能训练师职业;谷歌DeepMind乳腺癌筛查被狂怼;达摩院发布2020十大科技趋势;小米摄像头被曝漏洞,遭谷歌禁用。 AI炼丹师即将转正 近日,中国就业培训技术指导中心发布了《关于拟发布新职业信息公示的通告》,经人

写给新手炼丹师:2021版调参手册
点击下方卡片,关注“CVer”公众号 AI/CV重磅干货,第一时间送达 本文转载自:夕小瑶的卖萌屋 文 | 山竹小果 在日常调参的摸爬滚打中,参考了不少他人的调参经验,也积累了自己的一些有效调参方法,慢慢总结整理如下。希望对新晋算法工程师有所助力呀~ 寻找合适的学习率(learning rate) 学习率是一个非常非常重要的超参数,这个参数呢,面对不同规模、不同batch-si