本文主要是介绍唠一唠对AI炼丹师的模型部署探索(onnx),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
编者荐语
说到推理和部署,其实怎么也绕不开ONNX,ONNX在成立的初衷就是希望解决神经网络在不同的训练框架、推理框架上的转换问题。
作者丨战斗系牧师@知乎
链接丨https://zhuanlan.zhihu.com/p/557709588
说在前面的话
首先肯定是非常感谢 @OpenMMLab 能够给我这个小菜鸡机会,让我能够作为助理主持人(捧哏)和喵喵一起主持这一个开放麦。我是十分开心和激动的,因为其实离开了目标检测部署的工作有点时间了(已经被时代狠狠的抛弃,进化成了一个小白),所以这次的宵夜杂谈有啥做得不到位的,欢迎大佬们能够批评指正。另外非常欢迎愿意分享大佬可以报名开放麦,我们把知识传递下去,共建一个更棒的计算机视觉社区!
内容介绍
这期内容是 @走走 大佬关于目标检测模型End to End推理方案的探索和尝试。说到推理和部署,其实怎么也绕不开ONNX,ONNX在成立的初衷就是希望解决神经网络在不同的训练框架、推理框架上的转换问题。所以本期的内容会从如何玩转ONNX出发,唠一唠,我们在目标检测部署遇到的那些事情。因为篇幅以及有部分内容我不太了解不敢乱说的关系,我会在这里对开放麦的内容做一点顺序和内容上进行一点的调整,我也会加入自己的一些经历和看法,让大家看得更加轻松有趣一点。
ONNX是什么,如何生成ONNX(ONNX简要的介绍)?
预告:下面用三种方法向大家介绍如何生成Relu的ONNX模型,那么哪种方法才是最强的ONNX的生成方法呢?大家可以思考一下,我们继续往下看~
ONNX的组成
ONNX的静态图主要由Node(节点),Input(输入)和initializer(初始化器)但部分所组成的
✓节点就代表了神经网络模型一层的layer
✓输入代表了输入矩阵的维度信息
✓初始化器通常是存储权重/权值的。
每个组件元素都是hierarchical的结构,都是有着相互依赖关系的;
这是一个双向的链表。(Node、Graph彼此关联有相互关系的);
大家觉得难改,其实很大一部分也是因为ONNX的结构,边与边是一个稳定的结构关系,彼此很大程度上是相互依赖的。所以我们具体要怎么转化模型,怎么修改模型呢?我们接着看下去~
Pytorch导出ONNX模型
Pytorch是可以直接导出ONNX的模型,然后我们可以把导出的模型使用Netron的工具进行可视化工具。
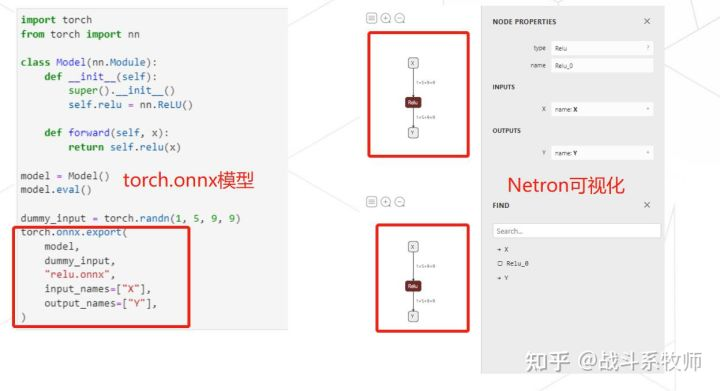
Numpy出发,揉一个数据结构是可行吗?
ONNX可以在Pytorch,通过转换得到。那么我们假如我们不用Pytorch上的转换,从零开始直接用Numpy人手揉一个ONNX模型是可行的吗?答案是可行的。
ONNX是用protobuf数据格式进行保存的。而protobuf本身也是跨语言的可以支持C, C++, C#, Java, Javascript, Objective-C, PHP, Python, Ruby,使用ONN下的helper fuction就可以帮助我们顺利的完成这些跨语言的转变,所以Numpy也自然可以使用helper函数揉出输入、节点以及初始化权值。

根据上图展示的情况,可想而知要想实现一个能用的模型整体的代码量是非常恐怖的。单一个Relu结构的代码量就要比Pytorch的转化(最上面的图)实现要多将近三倍左右。(其实最大的代码量还是出现在输入的数据类型转化上)如果要实现一个完整的深度模型转化,工作量可想而知,所以我们有没有其他的更科学高效一点的做法呢?
ONNX GraphSurgeon Basics
如果我们从ONNX出发要修改ONNX,其实是一个比较复杂的过程。那自然我们就会思考,那如果直接ONNX转ONNX困难的化,能不能借助点工具,也就是有没有更好的IR(中间表达)来帮助修改ONNX模型呢?
没错TensorRT就已经做出来一套有效帮助Python用户修改ONNX的工具GraphSurgeon(图手术刀)
这款IR主要有三部分组成
✓ Tensor——分为两个子类:变量和常量。
✓ 节点——在图中定义一个操作。可以放任何的Python 原始类型(list、dict),也可以放Graph或者Tensor。
✓ 图表——包含零个或多个节点和输入/输出张量。
目的就是为了更好的编辑ONNX

有了输入,再使用图手术刀对模型的结构进行组合,最后完成了Relu在ONNX上的转化。
如何在 ONNX 上进行图手术
因为ONNX本身是一种hierarchical的设计,这种其实就是一种经典的计算机思路。当我们打算动其中一层的时候,因为上下游的关联,下游的框架也会跟着被修改。
ONNX的IR,我们需要一个友好的中间表达!
比如在目标检测的场景中,我们有两种数据标注表达txt和mscoco。如果是一个区分train集和val集的工作的话,txt直接把标签随机分开两组就行。但是在coco数据集上,如果需要划分val集的时候,就要对json格式进行划分,还需要遵循一个图片和标注信息一一对应的关系,就会更加复杂。那ONNX的转化也是同理,所以理论上为了简便这个整个修改的工程,我们需要一个IR工具的一个中间表达来帮助我们进行修改。
GraphSurgeon IR
提供了丰富的API来帮我们进行表达。
没有边的信息,边的信息存在了输入输出中,所以ONNX需要对模型的信息进行拓扑排序。平时的手,我们在使用Pytorch导出ONNX模型的时候会发现有孤立的节点。如果对这个模型进行拓扑排序的话,会发现这个孤立算子是没有意义的,应该是需要处理掉这个冗余的算子。
TorchScript (具体的使用)
首先Pytorch是一个动态图,我们需要把Pytorch转变为ONNX的静态图!
Torchscript模式主要分为Tracing和Script,区分是用Tracing还是Script,主要是看是否是动态流。
Tracing会从头到脚执行一遍,记录下来所有的函数
如果遇到动态控制流(if-else)Script会走其中的一条,执行哪条就会记录哪条,另一条就会忽略。并且Script对不同大小的输入有效。
一般都建议Trace,因为除了ONNX_runtime,别的都不会人if这个动态算子。
Symbolic
某些情况下,帮助模型在端侧落地,在转换后也能够达到很好的效果。Python语言和c++本质上不一致,找到所以还是希望找到一种方式可以直接转换,不用自己再手动写C++算子,这算是一件很棒的事情。
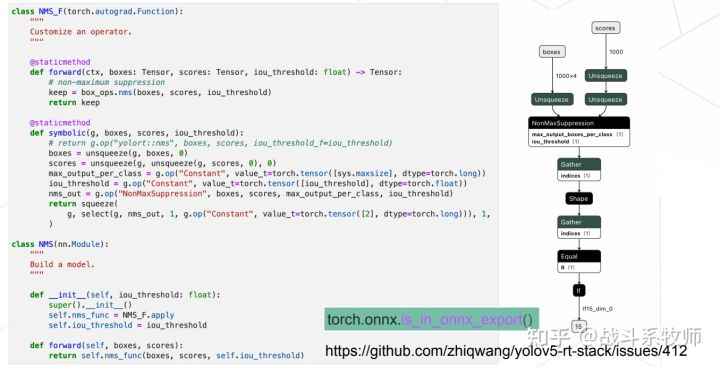
NMS_F是一个很平常的一个算子,在上图的实现。如果我们用Symbolic的函数会直接转出,整个后处理都可以用ONNX转出来,但是这种方法
ONNX GraphSurgeon
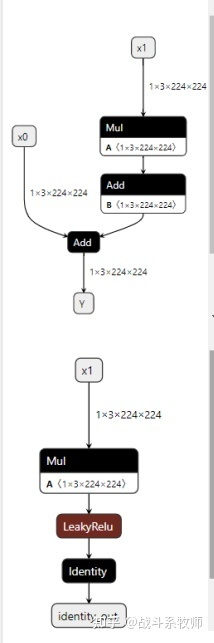
如何把上面的结构转换为下面的结构,大概需要做到是吧x0的输入分支给去掉,然后再加入LeakyReLU和Identity的节点,最后完成输出。
1、先找到add的算子,把add的名字改成LeakyReLU
2、补充attribute属性,加入alpha
3、指定一个输出属性identuty_out
4、然后再把identity节点加入到结构当中
5、先clean一些,再进行拓扑排序。
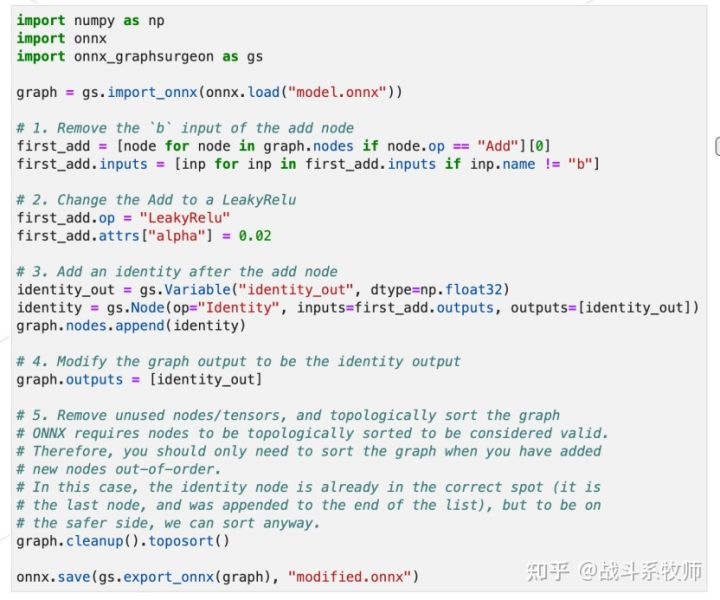
这个任务其实也可以用ONNX原生的IR来做,但是原生IR没有太多的帮助函数,很多工具链还是不太完善的,所以还是建议使用ONNX GraphSurgeon,因为用原生的IR的代码量一页肯定是写不完的了。
torch.fx
因为这块没有听太懂,所以就直接简单的吹一些没啥用的,大家可以放松一下看看!
从以前的量化进化到现在也能涉及一部分的图手术。其实为了能够在python上也能进行图手术上,在symbolic tracer的底层上也做了很多不一样的工作,但是在转化过程中也是有很多坑的,但是因为Python-to-Python会更加有利于模型训练师的开发,Pytorch的工程师也正在继续发展,正在逐步舍弃TorchScript。
利用torch.fx+ONNX做量化可以极大的节省代码量,是一个很棒的工作。
Focus模块替换(部署的技巧)
Focus在yolov5提出来的!
Focus包括了两部分组成Space2Depth + Conv3。有一点值得注意的是,Focus在实现过程focus_transform中会用到Slice的动态的操作,而这种动态的操作在部署的时候往往是会出大问题的。但是有意思的一点是,Space2Depth和Pytorch中的nn.PixelUnShuffle物理意义是一致的,但是实现的过程却有点不太相同,这也是这一版本YoloV5比较坑的点。
但是实现上一般有 CRD/DCR mode 方式, 由排列顺序决定, focus的实现跟这两种常用的mode 均不一致
nn.PixelUnShuffle是我们分割任务的老朋友了,在这里的出现,其更多的是在说明,其实下游任务正常逐步的进行一个统一和兼容。FPN到现在也转变为PAN,这样的转变也说明了很多。

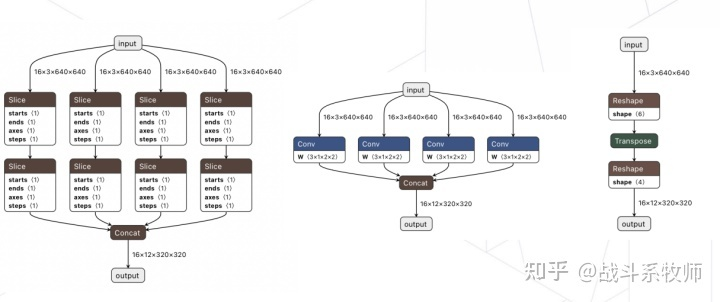
仔细看看右边的Focus2的内容,其实只是一个reshape+conv+reshape的操作,这在虽然物理含义上是Space2Depth,但是与ONNX和Pytorch对应的实现都是不一致的。
mmdepoly有提供一系列的转换,可以帮助我们更好的解释这一点,大家可以看看。
在yolov5-6.0的时候已经没有人再使用Focus,这个操作也被替换成了一个6x6的卷积操作了。
再到现在6x6的卷积会转换为3x3的卷积拼接出来,这样会让整体的推理速度会更快。
Torch.FX对Focus进行替换

主要是用自己的卷积的实现替换focus_transform和Focus的实现。把中间层展开来看的,就可以发现还需要自己手写去补充buffer的算子。
一个比较新的图手术的方法,大家可以看一看,代码量也不是很大。
给目标检测网络插入EfficientNMS结构(如何做后处理会更加的高效!)
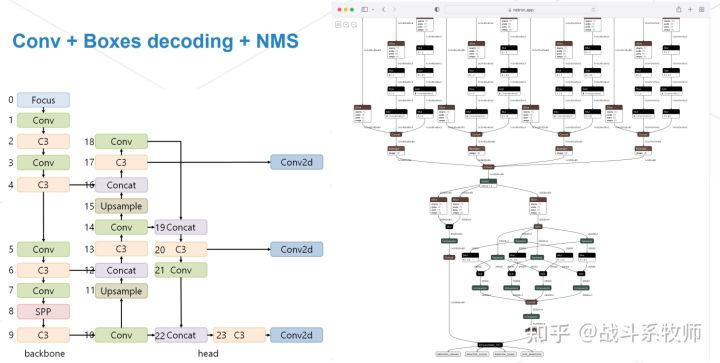
其实EfficientNMS是trt8.0的一个插件,以前是BatchedNMS,这个操作还没有手写的插件快。
下面就展开的讲讲EfficientNMS。
EfficientNMS原本是来自谷歌的EfficientDet 来的,能提速,而且与BatchedNMS一致,这么好用,我们为啥不用呢?
Yolo系列中,卷积后会加一个Box的解码,最后再加上NMS的操作。Box解码需要我们去重点的优化,如果想要在C++实现,就要自己手写一个实现。但是在我们的实现中,我们会更多的加速方法,这里就不展开说了。但是总的来说现在的新版本的Yolo都基本都固定了前处理跟NMS部分,卷积部分和编解码一直在变,不过现在也基本被RepVGG统治了。
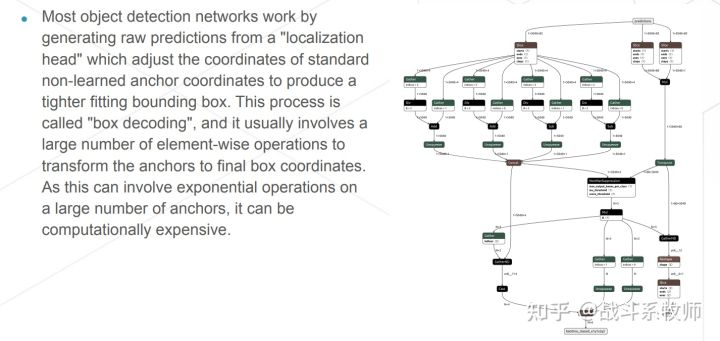
大家也可以看看上面实现的yolov7后处理的方法。这是一个日本的一个项目实现出的一个整体的结构,我们其实也还有另一种方式可以用pytorch+onnx直接拼出来这样一个graph出来的。主要还是为了解决这种动态性,转化为静态去部署。
小小的概括一下
EfficientNMS该插件主要用于在 TensorRT 上与 EfficientDet 一起使用,因为这个网络对引入的延迟特别敏感较慢的 NMS 实现。但是,该插件对于其他检测架构也足够的适用,例如 SSD 或Faster RCNN。
✓ 标准 NMS 模式:
仅给出两个输入张量,
(i)边界框坐标和(ii)和每个Box的对应的分数。
✓ 融合盒解码器模式:给出三个输入张量,
(i)原始每个盒子的定位预测直接来自网络的定位头,
(ii)相应的分类来自网络分类头的分数
(iii)认锚框坐标通常硬编码为网络中的常数张量
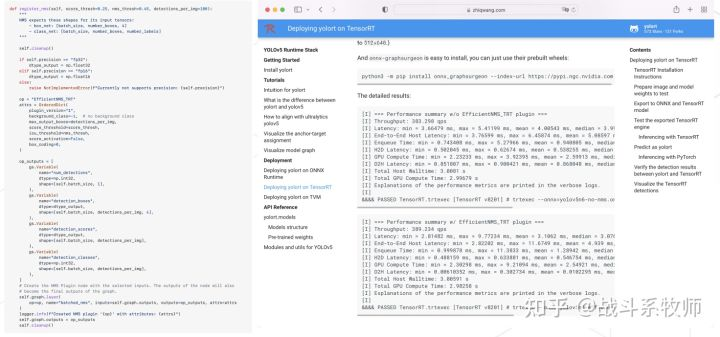
项目的实验结果
这里的实验结果大家可以看一看,这里值得注意的是居然时间要比以前没有加操作的结构要快。其实主要原因是没有把后处理的时间给加上,显然这样的快就没有啥意义。大家要记得对比后处理的时间,如果不对比这样的比较是不公平的,也不具有啥意义!
总结
感觉这个笔记还是没有记录得很到位,因为有些信息确实也是我的盲区,但是整个讲解过程,其实巨棒,我这里小小一篇杂谈,其实还不足以记录这么多内容,建议大家去看看开放麦的录播,以及去了解YOLORT和MMDeploy的代码哦~!
https://github.com/zhiqwang/yolov5-rt-stack github.com/zhiqwang/yolov5-rt-stack
https://github.com/open-mmlab/mmdeploy github.com/open-mmlab/mmdeploy
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇

下载1:OpenCV-Contrib扩展模块中文版教程在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。交流群欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~这篇关于唠一唠对AI炼丹师的模型部署探索(onnx)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







