本文主要是介绍推荐系统炼丹笔记:多模态推荐之用户评论篇,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:一元
公众号:炼丹笔记目前非常多的推荐系统主要使用用户的一些基础反馈信息来作为最终的标签进行模型的训练,例如点击/购买等,但是却鲜有文章去进一步挖掘用户的其它反馈,例如用户对于该产品的评论,很多的评论相较于点击等反馈更加具有表示性,比如你经常向一个用户推荐一类商品,该商品虽然点击率很高,但是该用户之前已经评论了恶心之类的,这么继续推下去的化很可能使得该用户不再使用该软件。
所以推荐系统里面的用户评论是否有用呢,按理说是有用的,比如有些不良的商品点击率极高,但是评论却极差,通过挖掘评论的信息是可以很好地挖掘出此类的信息。
但是此类的评论信息是否真的有用,有多大的用户都是一个问好,我们的实验显示:在大多数实践情况下, 最近的系统加入评论的效果是不如简单基线模型效果的;许多这样的系统在模型中隐藏评论时,性能只会有微小的变化;所以本文得出了下面的几个结论:
- 评论可能是非常重要的,但是最近的建模技术是很值得商榷的;
- 评论被作为一个正则而不是数据加入模型看起来更加有效;
- 我们英国更加关注一致的经验评估,尤其是数据集的选择和预处理策略;
问题设置

对比方案
为了评估推荐的reviews的作用,我们对比下面的几种方案。
- TransNets:除了使用用户和item 的评论文档来提取潜在特征外,Transnets还使用当前的评审进行正则化。它有两个子模型,一个关注给定评论中的情绪,另一个与DeepCoNN相同。正则化是通过最小化两个分量中潜在空间之间的距离来实现的。我们还考虑了一个TransNets++版本,其中MF潜在特征与潜在文本特征相连接;
- NARRE(Neural Attentive Rating Regression):通过在评论文件中学习对单个评论的关注权重,主要改进了DeepCoNN关于评论独立性的假设。NARRE还使用TextCNN为每个评论提取特征,并在默认情况下学习全局、用户和条目偏差。

- MPCN(Multi-Pointer Co-Attention Networks for Recommendation):引入了一个与NARRE相同的intuition的深层架构,即并非每个评论都同等重要,并尝试动态地推断这种重要性。与NARRE的注意机制不同,MPCN提出了一种基于评论的pointer式学习机制来推断评论的重要性。
实验
1. 不同模型在不同数据集上的效果
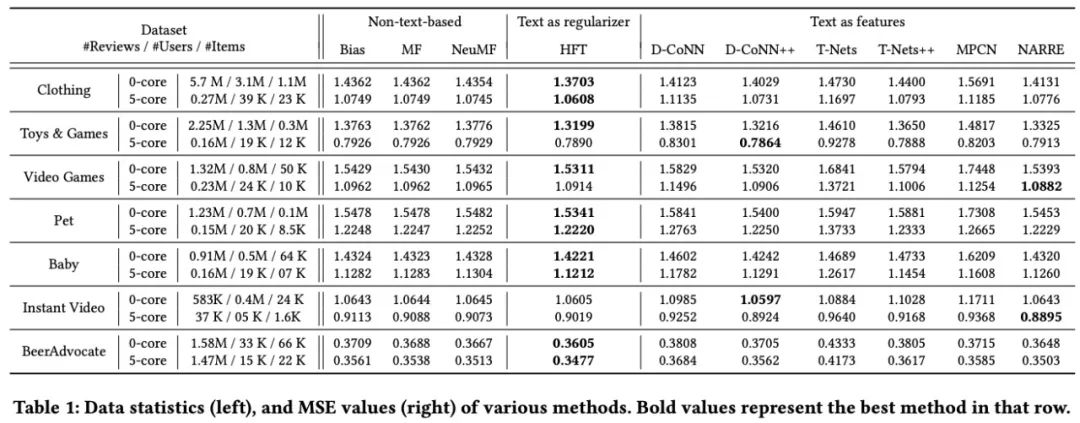
HFT在绝大部分数据集上都表现出了非常好的效果;比很多新的NN网络都要好很多;
2. 变动的稀疏性带来的性能变化
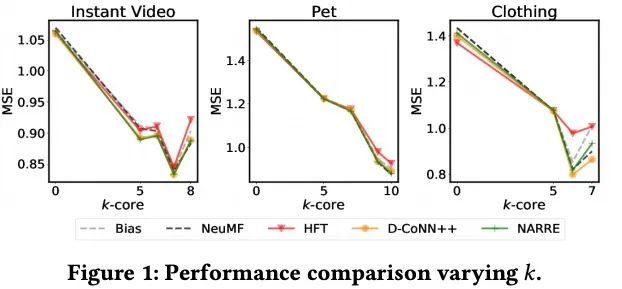
- 随着密度的增加,大多数方法的性能会更好。与其他方法相比,随着密度的增加,HFT变得相对更差,因为我们对每个用户和项目都有更多的评论,因此将评论建模为特征而不是正则化器是合乎逻辑的。文本作为基于特征的方法(如DeepCoNN和NARRE)性能的相对提高也支持了这一论点。我们还注意到随着密度的增加,MF方法的相对效果随着密度的增加而增加.
3. 评论什么时候有帮助

- 在这个实验中,我们评估评论对于商品冷度谱的哪一部分是最有帮助的。我们根据训练集的频率对商品进行分组,并比较不同方法与仅使用偏差的方法在测试集均方误差(越高越好)方面的改善情况。基于文本的方法对于较冷的项目(x轴左侧)的差异最大。同样明显的是,HFT在0核数据集上的表现往往优于基于特征提取的方法,而对于5核数据集,情况恰恰相反。
4. 评论数据可以带来多大的帮助

- 为了度量评论的重要性,我们设计了一个简单的实验,在这个实验中,我们随机地将数据集中x%的评论屏蔽掉。在这个修改过的数据集上,我们训练了所有的方法,改变了x。只依赖于DeepCoNN和MPCN这样的评审的方法会随着我们随机删除评审而急剧下降。另一方面,像DeepCoNN++和NARRE这样的方法往往相对不受影响。我们推测这种行为的产生是因为DeepCoNN++和NARRE中的偏差分量。
5. 一些启示
通过我们的分析,我们观察到了有趣的见解、异常现象:
- 在0核子集上,与MF相比,bias only模型的MSE差异相对较小。
- 最近发布的方法,如DeepCoNN、NARRE、MPCN等,在大多数评论数据集的0、5核版本中,均未能优于MF和HFT等更简单的方法,这与基于最新文献的预期形成了鲜明对比。
- 最近神经方法(如NARRE&DeepCoNN++)改进的主要原因是包含了用户和项目偏差项,而不是它们的体系结构。
- 与原始设置相比,当评论被屏蔽时,基于深度学习的更高容量、基于深度学习的模型意外效果是变化最小的.
讨论
- 复现&正确性:大多数论文中提到的官方结果使用了数据集的5-core版本,这是一个dense(可以说是不现实的)数据集设定,有点违背了这一系列研究的最初动机。我们还注意到,尽管数据预处理策略有所改变,但许多论文都直接复制了竞争对手方法的结果。另一个问题是超参数搜索不完整。最近所有的论文都显示了基于MF的方法和所提出的基于综述的方法之间的巨大差距,我们发现这是不支持的。
- 过拟合问题:我们推测过拟合是在未经处理的现有审查数据集上使用高度复杂模型的主要障碍。我们可以观察到(1).DeepCoNN++、NARRE和NeuMF在提高数据集密度时,与仅使用偏差和HFT相比,DeepCoNN++、NARRE和NeuMF的效果相对提高;(2)对于低频项,MF的性能往往比只使用bias的差。
- 评论作为一个正则使用会更好: 我们认为评论更擅长于规范潜藏因子,而不是作为更多的数据从中提取更好的特征,尤其是在冷启动的情况下。我们的信任得到了以下事实的支持:与DeepCoNN(++)、NARRE和MPCN相比,HFT等更简单的模型在更冷的商品上表现更好——所有这些模型都使用评论来建模用户/商品的潜在特征。我们还想再次重申,我们的假设只在相对较冷(冷启动)的条件下成立,并且随着数据密度的增加,DeepCoNN++等更具表现力的方法开始表现得相对更好。
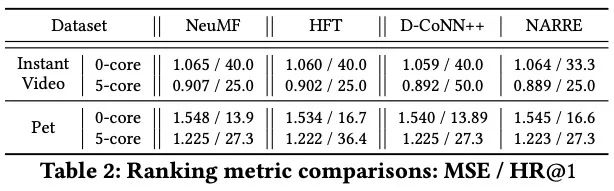
- MSE是否有问题?: 我们可以认为,新提出的模型确实会提升推荐的效果,但我们的评价标准(MSE)有限,我们应该考虑更相关的排序指标。
小结
通过分析评论和评论相结合的模型,我们得出结论:
- 评论数据可能很重要,但该领域目前的发展方向需要重新考虑。
- 结果中呈现的不一致,以及不切实际/不切实际的数据设置可能会阻碍整体的进度。
这篇关于推荐系统炼丹笔记:多模态推荐之用户评论篇的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








