泰坦尼克专题

24/9/3算法笔记 kaggle泰坦尼克
题目: 这次我用两种算法做了这道题 逻辑回归二分类算法 import pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScalerfrom sklearn.linear_model import LogisticRegr

Kaggle入门——泰坦尼克之灾
一、实验目的与实验环境 实验目的:熟练运用Python列表、字典、集合、数组等数据结构以及索引和切片等查询操作解决实际问题,熟练掌握Python读写文本文件的方法,熟练使用Python数据分析库函数,通过完成kaggle泰坦尼克之灾这个数据分析的入门项目,即“给出泰坦尼克号上的乘客的信息,预测乘客是否幸存”进行一个简单的数据分析。作为新手初步了解完成一个数据分析项目于的具体流程和实现方式,初步了
Kaggle泰坦尼克生存预测之随机森林学习
这篇文章讲述的是Kaggle上一个赛题的解决方案——Titanic幸存预测.问题背景是我们大家都熟悉的【Jack and Rose】的故事,豪华游艇与冰山相撞,大家惊慌而逃,可是救生艇的数量有限,无法人人都有。赛题官方提供训练数据和测试数据两份数据,训练数据主要是一些乘客的个人信息以及存活状况,测试数据也是乘客的个人信息但是没有存活状况的显示。所以本文的主要目的就是,根据训练数据生成合适的模型并预
【Python基础】案例分析:泰坦尼克分析
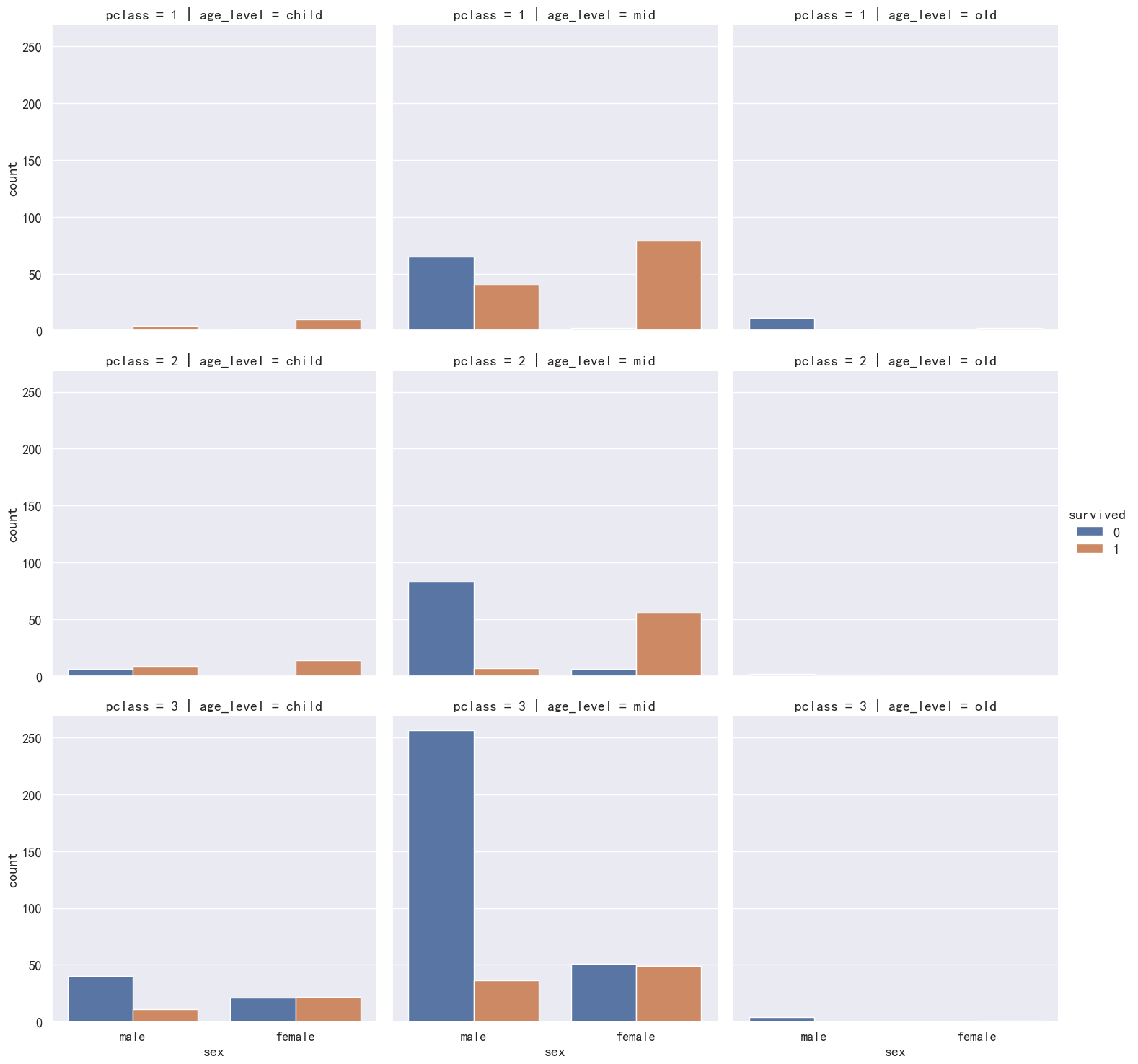
泰坦尼克分析 1 目的: 熟悉数据集熟悉seaborn各种操作作 import pandas as pdimport seaborn as snsimport numpy as npimport matplotlib.pyplot as plt%matplotlib inlinehome = r'data'df = sns.load_dataset('titanic', data

数据重构 —— 泰坦尼克任务
第二章:数据重构 熟悉的开始~ # 导入numpy和pandasimport pandas as pdimport numpy as np# 载入data文件中的:train-left-up.csvleft_up = pd.read_csv('train-left-up.csv')left_up.head() 2.4 数据的合并 2.4.1 任务一:将data文件夹里面的所有数据
kaggle:泰坦尼克生存预测( R语言机器学习分类算法)
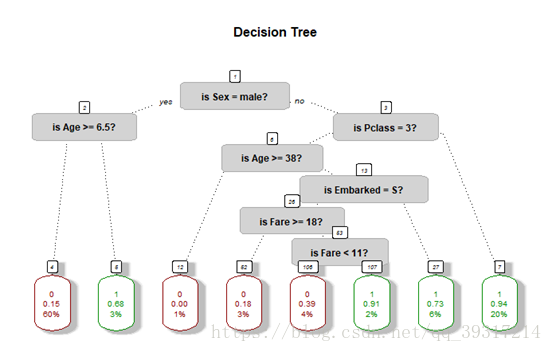
本文在基本的多元统计分析技术理论基础上,结合机器学习基本模型,选择Kaggle(数据建模竞赛网站)的入门赛——Titanic生存预测作为实战演练,较为完整地呈现了数据建模的基本流程和思路。采用的模型有逻辑回归,决策树,SVM支持向量机以及进阶的集成学习方法——Boosting和RandomForest。 在建立模型后基于混淆矩阵的模型评估方法给出了Titanic生存预测的基本结论。 该数
10000+字,利用 Python 进行泰坦尼克生存预测
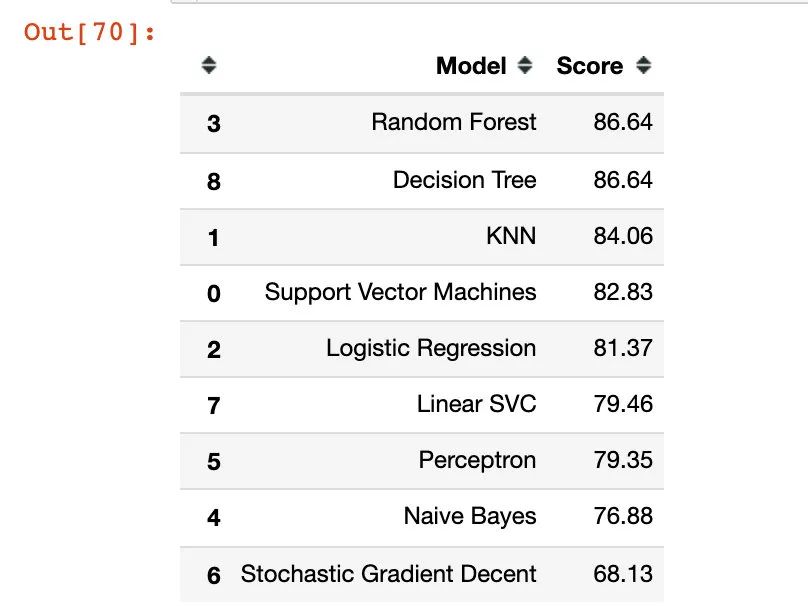
大家好,Titanic数据是一份经典数据挖掘的数据集,本文介绍的是kaggle排名第一的案例分享。原notebook地址:https://www.kaggle.com/startupsci/titanic-data-science-solutions 文章目录 排名技术提升数据探索导入库导入数据字段信息字段分类缺失值 数据假设删除字段修改、增加字段猜想 统计分析可视化分析年龄与生还舱位与
![[Machine Learning] 逻辑回归应用之Kaggle泰坦尼克之灾](http://7xo0y8.com1.z0.glb.clouddn.com/2_titanic/process.png?imageView/2/w/700/q/100)
[Machine Learning] 逻辑回归应用之Kaggle泰坦尼克之灾
主要学习数据处理的思路。 作者: 寒小阳 时间:2015年11月。 出处:http://blog.csdn.net/han_xiaoyang/article/details/49797143 声明:版权所有,转载请注明出处,谢谢。 1.引言 先说一句,年末双十一什么的一来,真是非(mang)常(cheng)欢(gou)乐(le)!然后push自己抽出时间来写这篇blog的原因也
Kaggle竞赛(1)——Tantic泰坦尼克之灾
作者: 寒小阳 时间:2015年11月。 出处:http://blog.csdn.net/han_xiaoyang/article/details/49797143 声明:版权所有,转载请注明出处,谢谢。 1.引言 先说一句,年末双十一什么的一来,真是非(mang)常(cheng)欢(gou)乐(le)!然后push自己抽出时间来写这篇blog的原因也非常简单: 写完前两篇逻辑回归的介绍
Kaggle竞赛-Titanic泰坦尼克
#####------------------------------------------------------------------------------------------------------- 在博主的原有基础上修改了部分错误,Jupyter Notebook实现。 代码链接:http://download.csdn.net/download/linxid/10230873

泰坦尼克沉船存活率(机器学习,Python)
目录 1,实验要求: 2,报告内容 引言 数据处理 导入数据 查看数据集信息 数据清洗 特征工程 特征提取 特征选择 生还率预测说明 模型构建 建立训练数据集和测试数据集 选择不同的机器学习算法 训练模型,评估模型 方案实施 生存预测 参数调优 结论 改进方法 1,实验要求: 详细描述:按照机器学习一般流程针对“泰坦尼克沉船生存率”数据进行

R语言可视化:ggplot2冲积/桑基图sankey分析大学录取情况、泰坦尼克幸存者数据
最近我们被客户要求撰写关于桑基图的研究报告,包括一些图形和统计输出。 本文介绍了冲积/桑基图,以及 定义了命名方案和冲积/桑基图的基本组成部分(轴、冲积层、流)。描述了所识别的冲积/桑基图数据结构。展示了一些流行的主题。 冲积/桑基图 这里有一个典型的冲积/桑基图。 现在,我们以该图像为参考点,定义典型冲积图的以下元素。 轴是一个维度(变量),数据沿着这个维度在一个固定
数据清洗及特征处理 —— 泰坦尼克任务
第二章:数据清洗及特征处理 熟悉的开始~ # 导入numpy和pandasimport pandas as pdimport numpy as np#加载数据train.csvdf = pd.read_csv('train.csv')df 2.1 缺失值观察与处理 2.1.1 任务一:缺失值观察 (1) 请查看每个特征缺失值个数 # 查看数据内缺失值字段df.info()
实战Kaggle泰坦尼克数据集,玩转Pandas透视表 | 强烈推荐
数据透视表(Pivot Table)是常用的数据汇总工具,可以通过控制数据的排列灵活地进行数据分析,进而挖掘出数据中最有价值的信息。掌握数据透视表,已经成为数据分析从业者必备的一项技能。 在python中我们可以通过pandas.pivot_table函数来实现数据透视表的功能。本篇文章介绍了pandas.pivot_table具体的使用方法,在最后还准备了一个备忘单,希望能够帮助你记住如何

数据分析案例实战:泰坦尼克船员获救
学习唐宇迪《python数据分析与机器学习实战》视频 一、数据分析 可以看到有些数据是字符串形式,有些是数值形式,有数据缺失。 survived:1代表存活,0代表死亡,目标tag。 Pclass:船舱,较重要。 sex:性别,较重要。 age:年龄,有缺失值,较重要。 SibSp:兄弟姐妹。Parch:父母孩子。 Ticket:票。 Fare:船票价格,特征可能与船舱特征重复,也较重要

kaggle入门-泰坦尼克
机器学习流程 初探数据 导入数据:pd.read_csv 观察数据:head()、info()、describe() 数据可视化 画子图plt.subplot2grid((2,3),(1,0)) 两行三列中第二行第一列的位置 每列按照unique值统计数量画条形图:df.col_name.values_counts().plot(kind=“bar”) 在此基础上观察某X于Y之间的联系

Kaggle泰坦尼克之灾
逻辑回归应用之Kaggle泰坦尼克之灾 背景 训练和测试数据是一些乘客的个人信息以及存活状况,要尝试根据它生成合适的模型并预测其他人的存活状况。 1. 数据总览 train.csv和test.csv分别为训练集和测试集,ground_truth.csv为对应答案 得到这些后,对这些数据读入和简单分析一下 df = pd.read_csv("train.csv")print(df.head

Kaggle 泰坦尼克
入门kaggle,开始机器学习应用之旅。 参看一些入门的博客,感觉pandas,sklearn需要熟练掌握,同时也学到了一些很有用的tricks,包括数据分析和机器学习的知识点。下面记录一些有趣的数据分析方法和一个自己撸的小程序。 1.Tricks 1) df.info():数据的特征属性,包括数据缺失情况和数据类型。 df.describe(): 数据中各个特征的数目,缺失值为Na