本文主要是介绍数据清洗及特征处理 —— 泰坦尼克任务,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第二章:数据清洗及特征处理
熟悉的开始~
# 导入numpy和pandas
import pandas as pd
import numpy as np#加载数据train.csv
df = pd.read_csv('train.csv')
df
2.1 缺失值观察与处理
2.1.1 任务一:缺失值观察
(1) 请查看每个特征缺失值个数
# 查看数据内缺失值字段
df.info()
# 查看每个特征缺失值个数
df.isnull().sum()
info()用于打印DataFrame的简要摘要,显示有关DataFrame的信息,包括索引的数据类型dtype和列的数据类型dtype,非空值的数量和内存使用情况。
info()方法最后输出的是每列不为空的数量。也就是说如果有某列数据的数量比实际的索引数量要少,说明该列存在缺少值。
注意info()和describe()的区别:
describe()函数用于生成描述性统计信息。 描述性统计数据:数值类型的包括均值,标准差,最大值,最小值,分位数等;类别的包括个数,类别的数目,最高数量的类别及出现次数等;输出将根据提供的内容而有所不同。
(2) 请查看Age, Cabin, Embarked列的数据
# 查看Age, Cabin, Embarked列的数据
df[['Age','Cabin','Embarked']] # ['Age','Cabin','Embarked'] 作为索引标签
2.1.2 任务二:对缺失值进行处理
(1)处理缺失值一般有几种思路
- 直接使用含有缺失值的特征
- 删除含有缺失值的特征(该方法在包含缺失值的属性含有大量缺失值而仅仅包含极少量有效值时是有效的时候)
- 缺失值补全
(2) 请尝试对Age列的数据的缺失值进行处理
- 均值插补
- 同类均值插补
- 建模预测
- 高维映射
- 多重插补
- 极大似然估计
- 压缩感知和矩阵补全
(3) 请尝试使用不同的方法直接对整张表的缺失值进行处理
处理缺失值的一般思路:
- 删除
- 插补(重点)
- 不处理缺失值
缺失值处理 —— 传送门
# 缺失值处理(方法一)
df[df['Age']==None]=0 # 空值部分未用“0”填充
# Age这一列的哪一行是空,就在Age那一列给它补上0
df
效果如下:
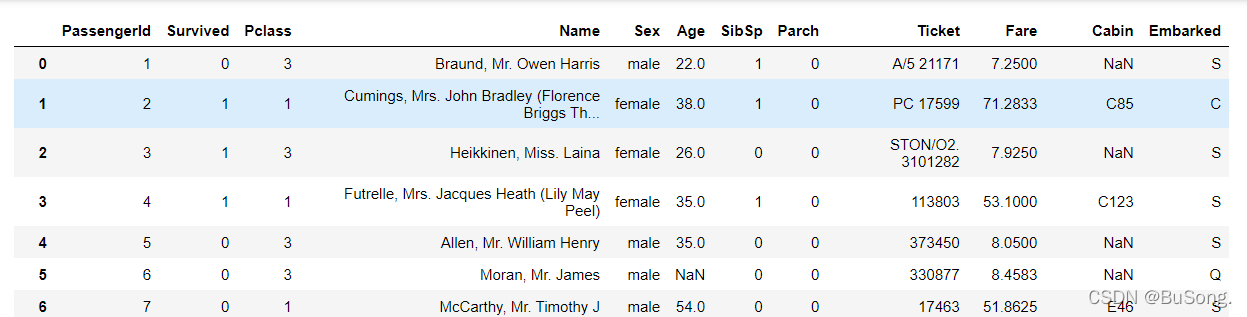
# 缺失值处理(方法二)
df = pd.read_csv('train.csv')
df[df['Age'].isnull()] = 0 # 可行操作 空值部分用“0”来填充
df
效果如下:
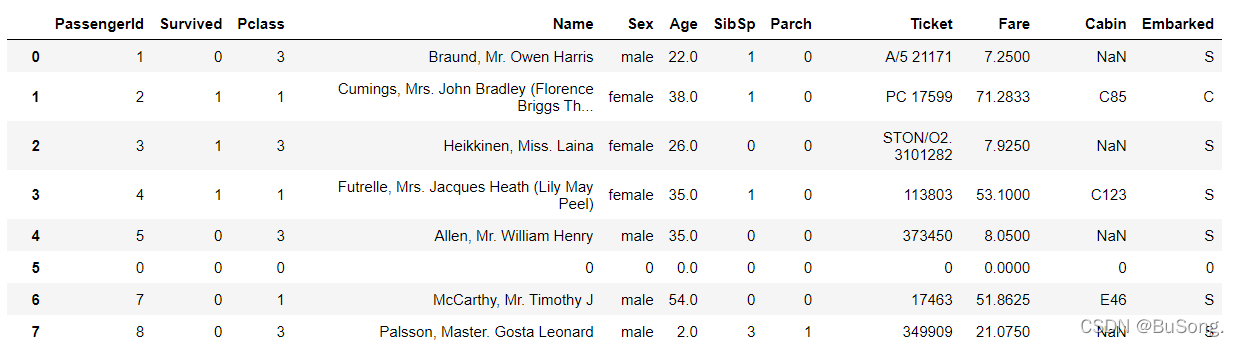
# 缺失值处理(方法三)
df = pd.read_csv('train.csv')
df[df['Age'] == np.nan] = 0 # 空值部分未用“0”填充
df
效果如下:
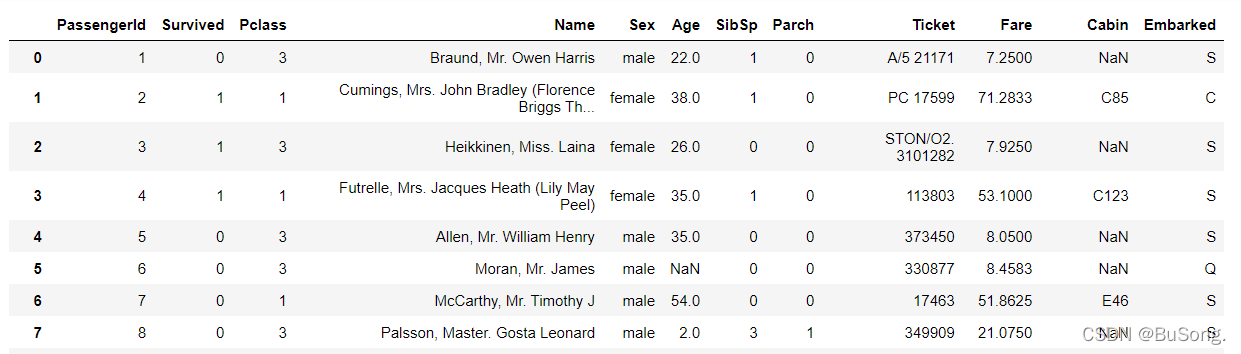
# 缺失值处理(方法四)
df = pd.read_csv('train.csv')
df[df['Age'].isna()] = 0 # 可行操作 空值部分用“0”来填充
df
效果如下:
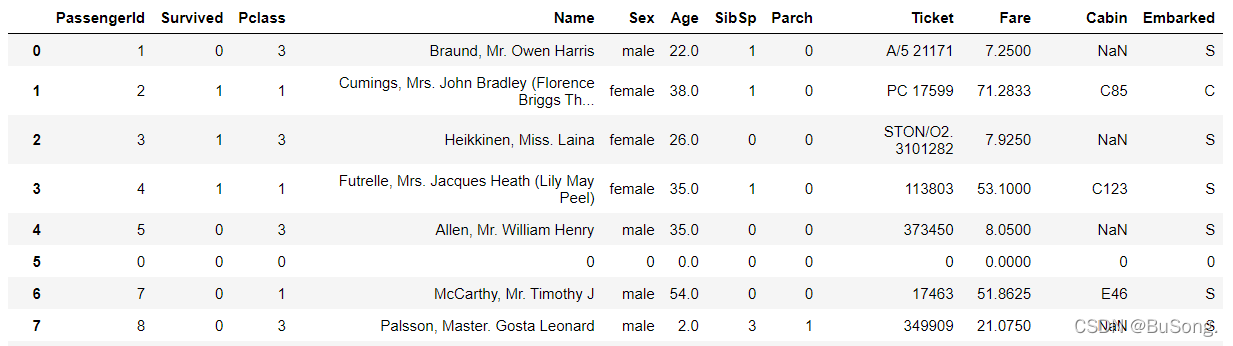
# 丢弃含空值的行、列
df.dropna()
# 用0来填充缺失值
df = pd.read_csv('train.csv')
df.fillna(0)
【思考1】dropna和fillna有哪些参数,分别如何使用呢?
【思考1回答】
dropna()方法-丢弃含空值的行、列
函数形式:dropna(axis=0, how=‘any’, thresh=None, subset=None, inplace=False)
参数:
axis:轴。0或’index’,表示按行删除;1或’columns’,表示按列删除。
how:筛选方式。‘any’,表示该行/列只要有一个以上的空值,就删除该行/列;‘all’,表示该行/列全部都为空值,就删除该行/列。
thresh:非空元素最低数量。int型,默认为None。如果该行/列中,非空元素数量小于这个值,就删除该行/列。
subset:子集。列表,元素为行或者列的索引。如果axis=0或者‘index’,subset中元素为列的索引;如果axis=1或者‘column’,subset中元素为行的索引。由subset限制的子区域,是判断是否删除该行/列的条件判断区域。
inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。
fillna()方法-填充空值
函数形式:fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None, **kwargs)
参数:
value:用于填充的空值的值。
method: {‘backfill’, ‘bfill’, ‘pad’, ‘ffill’, None}, default None。定义了填充空值的方法, pad / ffill表示用前面行/列的值,填充当前行/列的空值, backfill / bfill表示用后面行/列的值,填充当前行/列的空值。
axis:轴。0或’index’,表示按行删除;1或’columns’,表示按列删除。
inplace:是否原地替换。布尔值,默认为False。如果为True,则在原DataFrame上进行操作,返回值为None。
limit:int, default None。如果method被指定,对于连续的空值,这段连续区域,最多填充前 limit 个空值(如果存在多段连续区域,每段最多填充前 limit 个空值)。如果method未被指定, 在该axis下,最多填充前 limit 个空值(不论空值连续区间是否间断)
downcast:dict, default is None,字典中的项为,为类型向下转换规则。或者为字符串“infer”,此时会在合适的等价类型之间进行向下转换,比如float64 to int64 if possible。
注:fillna(0) 用0来填充缺失值
【思考】检索空缺值用np.nan,None以及.isnull()哪个更好,这是为什么?如果其中某个方式无法找到缺失值,原因又是为什么?
【思考回答】Pandas 主要用 np.nan 表示缺失数据。 计算时,默认不包含空值。数值列读取数据后,空缺值的数据类型为float64所以用None一般索引不到。
2.2 重复值观察与处理
2.2.1 任务一:请查看数据中的重复值
# 查看数据中的重复值
df[df.duplicated()]
2.2.2 任务二:对重复值进行处理
# 对整个行有重复值的清理的方法
df = df.drop_duplicates()
df.head()
2.2.3 任务三:将前面清洗的数据保存为csv格式
# 将前面清洗的数据保存为csv格式
df.to_csv('test_clear.csv')
2.3 特征观察与处理
我们对特征进行一下观察,可以把特征大概分为两大类:
数值型特征:Survived ,Pclass, Age ,SibSp, Parch, Fare,其中Survived, Pclass为离散型数值特征,Age,SibSp, Parch, Fare为连续型数值特征。
文本型特征:Name, Sex, Cabin,Embarked, Ticket,其中Sex, Cabin, Embarked, Ticket为类别型文本特征,数值型特征一般可以直接用于模型的训练,但有时候为了模型的稳定性及鲁棒性会对连续变量进行离散化。文本型特征往往需要转换成数值型特征才能用于建模分析。
2.3.1 任务一:对年龄进行分箱(离散化)处理
(1) 分箱操作是什么?
分箱操作就是将连续数据转换为分类对应物的过程。简单点说就是将不同的东西,按照特定的条件放到一个指定容器里,比如分水果,把绿色的放一个篮子里,红色一个篮子等等,这个篮子就是箱,而水果就是数据, 其中颜色就是条件
分箱操作分为等距分箱和等频分箱。
分箱操作也叫⾯元划分或者离散化。
(2) 将连续变量Age平均分箱成5个年龄段,并分别用类别变量12345表示
#将连续变量Age平均分箱成5个年龄段,并分别用类别变量12345表示
df['AgeBand'] = pd.cut(df['Age'], 5,labels = [1,2,3,4,5])
df.head()
df.to_csv('test_ave.csv')
(3) 将连续变量Age划分为[0,5) [5,15) [15,30) [30,50) [50,80)五个年龄段,并分别用类别变量12345表示
#将连续变量Age划分为(0,5] (5,15] (15,30] (30,50] (50,80]五个年龄段,并分别用类别变量12345表示
df['AgeBand'] = pd.cut(df['Age'],[0,5,15,30,50,80],labels = [1,2,3,4,5])
df.head()
df.to_csv('test_cut.csv')
#将连续变量Age划分为(0,5] (5,15] (15,30] (30,50] (50,80]五个年龄段,并分别用类别变量12345表示
df['AgeBand'] = pd.cut(df['Age'],[0,5,15,30,50,80],right = False)
df.head()
(4) 将连续变量Age按10% 30% 50% 70% 90%五个年龄段,并用分类变量12345表示
#将连续变量Age按10% 30% 50 70% 90%五个年龄段,并用分类变量12345表示
df['AgeBand'] = pd.qcut(df['Age'],[0,0.1,0.3,0.5,0.7,0.9],labels = [1,2,3,4,5])
df.head()
df.to_csv('test_pr.csv')
2.3.2 任务二:对文本变量进行转换
(1) 查看文本变量名及种类
# 查看类别文本变量名及种类
# 方法一: value_counts
df['Sex'].value_counts() # 查看'Sex'列中的变量及种类
df['Cabin'].value_counts() # 查看'Cabin'列中的变量及种类
df['Embarked'].value_counts() # 查看'Embarked'列中的变量及种类#方法二: unique
df['Sex'].unique()
df['Sex'].nunique()
value_counts常用于数据表的计数及排序,它可以用来查看数据表中,指定列里有多少个不同的数据值,并计算每个不同值有在该列中的个数,同时还能根据需要进行排序.
unique 函数 统计list中的不同值
nunique 函数 可直接统计dataframe中每列的不同值的个数
(2) 将文本变量Sex, Cabin ,Embarked用数值变量12345表示
# 将文本变量Sex, Cabin ,Embarked用数值变量12345表示
#方法一: replace
df['Sex_num'] = df['Sex'].replace(['male','female'],[1,2],inplace = True)
df.head()#方法二: map
df['Sex_num'] = df['Sex'].map({'male': 1, 'female': 2})
df.head()#方法三 (文本变量转换成数组变量)
from sklearn.preprocessing import LabelEncoder
df['Cabin'] = LabelEncoder().fit_transform(df['Cabin'])
df['Embarked'] = LabelEncoder().fit_transform(df['Embarked'])
df.head()#方法四: 使用sklearn.preprocessing的LabelEncoder(了解)
from sklearn.preprocessing import LabelEncoder
for feat in ['Cabin', 'Ticket']:lbl = LabelEncoder() label_dict = dict(zip(df[feat].unique(), range(df[feat].nunique())))df[feat + "_labelEncode"] = df[feat].map(label_dict)df[feat + "_labelEncode"] = lbl.fit_transform(df[feat].astype(str))df.head()
replace() 方法把字符串中的 old(旧字符串) 替换成 new(新字符串)
map()函数会将指定的函数依次作用于某个序列的每个元素,并返回一个迭代器对象
(3) 将文本变量Sex, Cabin, Embarked用one-hot编码表示
for column in ['Cabin', 'Embarked']:
x = pd.get_dummies(df[column], prefix=[column]) # one-hot编码表示
df = pd.concat([df,x],axis = 1) # 按列拼接
df.head()
# 将文本变量Sex, Cabin, Embarked用one-hot编码表示
#方法: OneHotEncoder
for feat in ["Age", "Embarked"]:
# x = pd.get_dummies(df["Age"] // 6)
# x = pd.get_dummies(pd.cut(df['Age'],5))x = pd.get_dummies(df[feat], prefix=feat)df = pd.concat([df, x], axis=1)#df[feat] = pd.get_dummies(df[feat], prefix=feat)df.head()
2.3.3 任务三:从纯文本Name特征里提取出Titles的特征(所谓的Titles就是Mr,Miss,Mrs等)
# 从纯文本Name特征里提取出Titles的特征(所谓的Titles就是Mr,Miss,Mrs等)
df['Title'] = df.Name.str.extract('([A-Za-z]+)\.', expand=False) # 正则表达式进行提取
df.head()
# 保存上面的为最终结论
df.to_csv('test_fin.csv')
总结
本节课学习掌握了对于存在缺失值、重复值、异常值数据的处理及所谓的数据清洗,同时了解如何对特征进行观察与处理,通常可以采取分箱(离散化)处理、将文本型特征转换成数值型特征或对文本字段特征进行提取等等操作。
这篇关于数据清洗及特征处理 —— 泰坦尼克任务的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




