数据分布专题

【MySQL】索引使用规则——(覆盖索引,单列索引,联合索引,前缀索引,SQL提示,数据分布影响,查询失效情况)
前言 大家好吖,欢迎来到 YY 滴MySQL系列 ,热烈欢迎! 本章主要内容面向接触过C++的老铁 主要内容含: 欢迎订阅 YY滴C++专栏!更多干货持续更新!以下是传送门! YY的《C++》专栏YY的《C++11》专栏YY的《Linux》专栏YY的《数据结构》专栏YY的《C语言基础》专栏YY的《单片机》专栏YY的《STM32》专栏YY的《数据库》专栏 目录 一.索引使用规则※.验证
生产事故(MongoDB数据分布不均解决方案)
事故集合: 可以很明显可以看到我们这个集合的数据严重分布不均匀。 一共有8个分片,面对这个情况我首先想到的是手动拆分数据块,但这不是解决此问题的根本办法。 造成此次生产事故的首要原因就是片键选择上的问题,由于片键选择失误,在数据量级不大的时候数据看起来还是很健康的,但随着数据量的暴涨,问题就慢慢浮出了水面,我们使用的组合片键并不是无规律的,片键内容是线性增长的,这就导致了数据的不

数据分布之一致性哈希
一、数据分布 在分布式环境下,数据分布也即是将数据拆分,存放到不同节点上,是分布式系统中的基本问题之一。不同的数据分布方式需要权衡诸如伸缩性、数据倾斜(负载的均衡)、元数据维护等问题。没有一种万能的方案能够解决所有的问题,不能脱离应用场景谈优劣,应该要针对不同的应用场景选择合适的方案。 一般而言,可以有以下几种数据分布的方式: 1)哈希分区(或者叫余数法) 基本思想是根据数据的某项特征(如

ceph的CRUSH数据分布算法介绍
原文:http://way4ever.com/?p=122 CRUSH是ceph的一个模块,主要解决可控、可扩展、去中心化的数据副本分布问题。 1 摘要 随着大规模分布式存储系统(PB级的数据和成百上千台存储设备)的出现。这些系统必须平衡的分布数据和负载(提高资源利用率),最大化系统的性能,并要处理系统的扩展和硬件失效。ceph设计了CRUSH(一个可扩展的伪随机数据分布算法),用在分
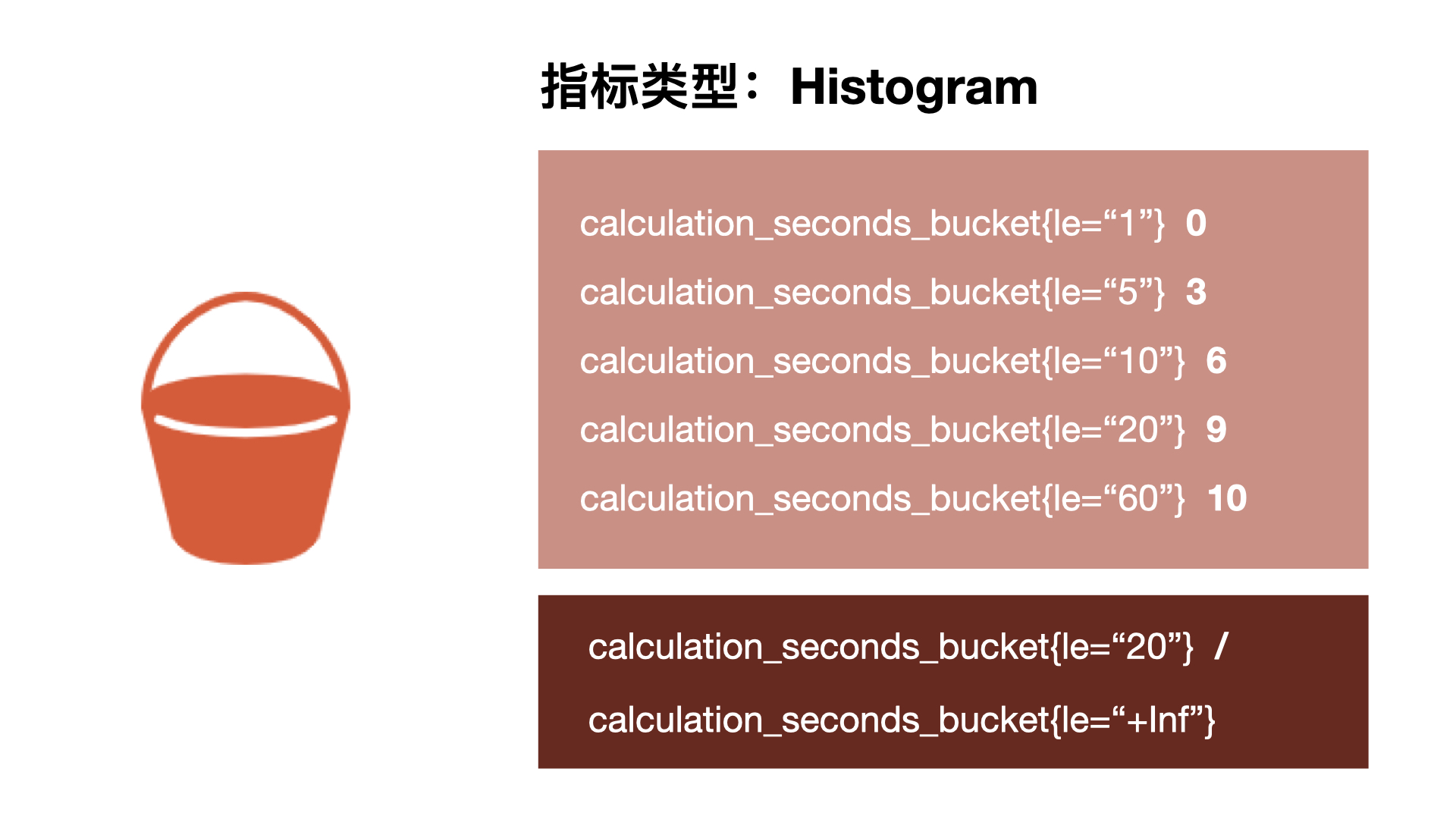
Prometheus Metrics指标类型 Histogram、Summary分析数据分布情况
Histogram 直方图 、Summary 摘要 使用Histogram和Summary分析数据分布情况 除了 Counter 和 Gauge 类型的监控指标以外,Prometheus 还定义了 Histogram 和 Summary 的指标类型。Histogram 和 Summary 主用用于统计和分析样本的分布情况。 在大多数情况下人们都倾向于使用某些量化指标的平均值,例如 C
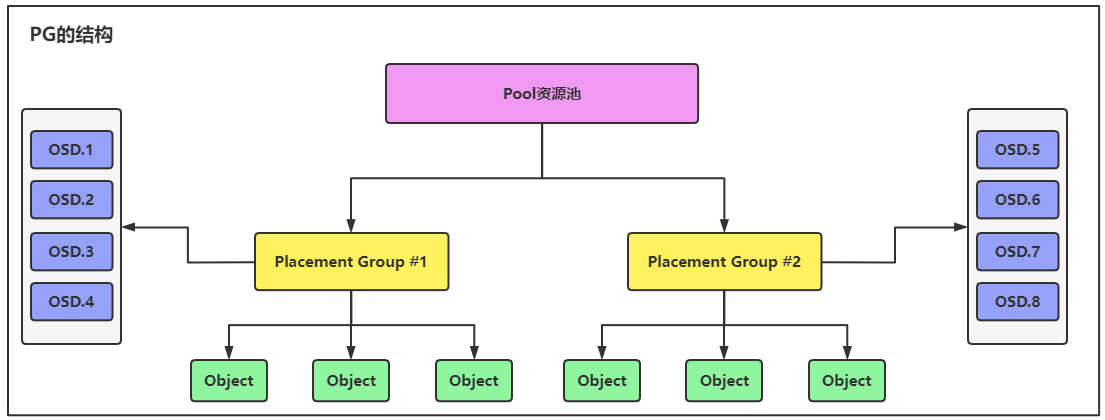
第⑯讲:Ceph集群Pool资源池管理以及PG的数据分布的核心技术要点
文章目录 1.Pool资源池的管理1.1.查看Pool资源池列表1.2.创建一个Pool资源池1.3.查看Pool资源池的参数信息1.4.修改Pool资源池的参数信息1.5.为Pool资源池设置应用模式1.6.重命名Pool资源池1.7.设置Pool资源池的限额1.8.删除Pool资源池1.9.查看Pool资源池的利用率 2.PG的数据分布概念 1.Pool资源池的管理 1.1

数据蒋堂 | 数据分布背后的逻辑
作者:蒋步星 来源:数据蒋堂 本文共1100字,建议阅读7分钟。在分布式数据库及大数据平台中,数据如何分布到多台机器中是个很关键的问题。 在分布式数据库及大数据平台中,数据如何分布到多台机器中是个很关键的问题。因为很多运算是数据密集型的,如果数据分布做得不好,就会导致网络传输量变大,从而影响性能。 一般来讲,分布式数据库会提供两种分布策略:对于大表按某个字段(的HASH值)去分布,大多数
分布式系统原理(2)--数据分布方式
二、分布式系统原理 1、数据分布方式 如何将分布式系统的输入数据拆解为可疑使用多机分布式处理的过程,成为数据分布方式。 (1)哈希方式(最常见) 按照数据的某一特征计算哈希值,并将哈希值与机器建立映射关系,从而将不同的数据分布到不同的机器上。如按数据属于的用户id计算哈希值,集群中的服务器按0-机器数减一编号,哈希值除以服务器的个数,余数为处理该数据的服务器编号。 l 优点:只要哈希函

绝对完美解决hdfs datanode数据和磁盘数据分布不均调整(hdfs balancer )——经验总结
Hadoop集群Datanode数据倾斜,个别节点hdfs空间使用率达到95%以上,于是新增加了三个Datenode节点,由于任务还在跑,数据在不断增加中,这几个节点现有的200GB空间估计最多能撑20小时左右,所以必须要进行balance操作。 通过观察磁盘使用情况,发现balance的速度明显跟不上新增数据的速度!!! 跟踪了一下balance的日志,发现两个问题:一是balance时

Aerospike-Architecture系列之数据分布
Data Distribution(数据分布) Aerospike数据库是Shared-Nothing 架构:一个Aerospike集群中的每个节点都是相同的,所有节点对等,无单点故障。 利用Aerospike智能分区算法,数据分布在集群中的各个节点之上。我们已经在这个领域的许多案例中测试过我们的方法,这个非常随机数函数保证分区分布误差在1-2%。 为了确定记录去向,使用RIPEMD160算
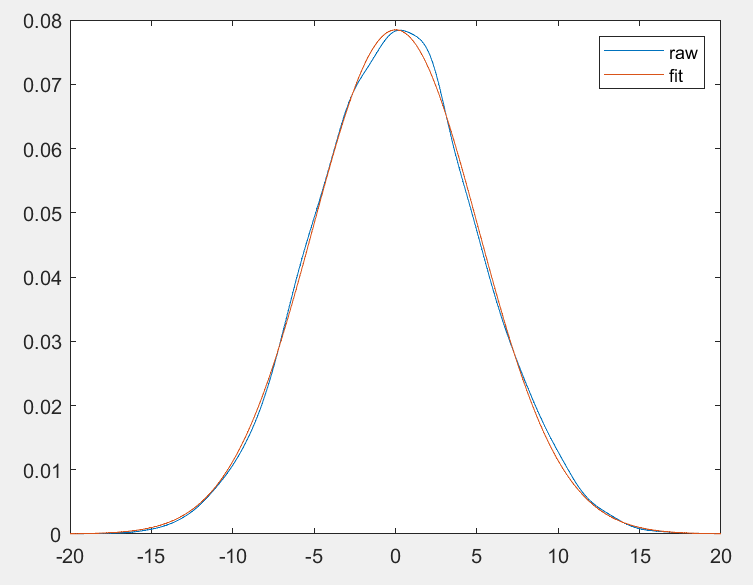
Matlab 之数据分布拟合
文章目录 Part.I IntroductionPart.II Distribution Fitter APP 的使用Chap.I APP 简介Chap.II 简单使用 Part.III 通过代码实现分布拟合Chap.I 基于 fitdist 函数Chap.II 获取数据的频率分布后进行曲线拟合 Reference Part.I Introduction 本文主要介绍了如何使用
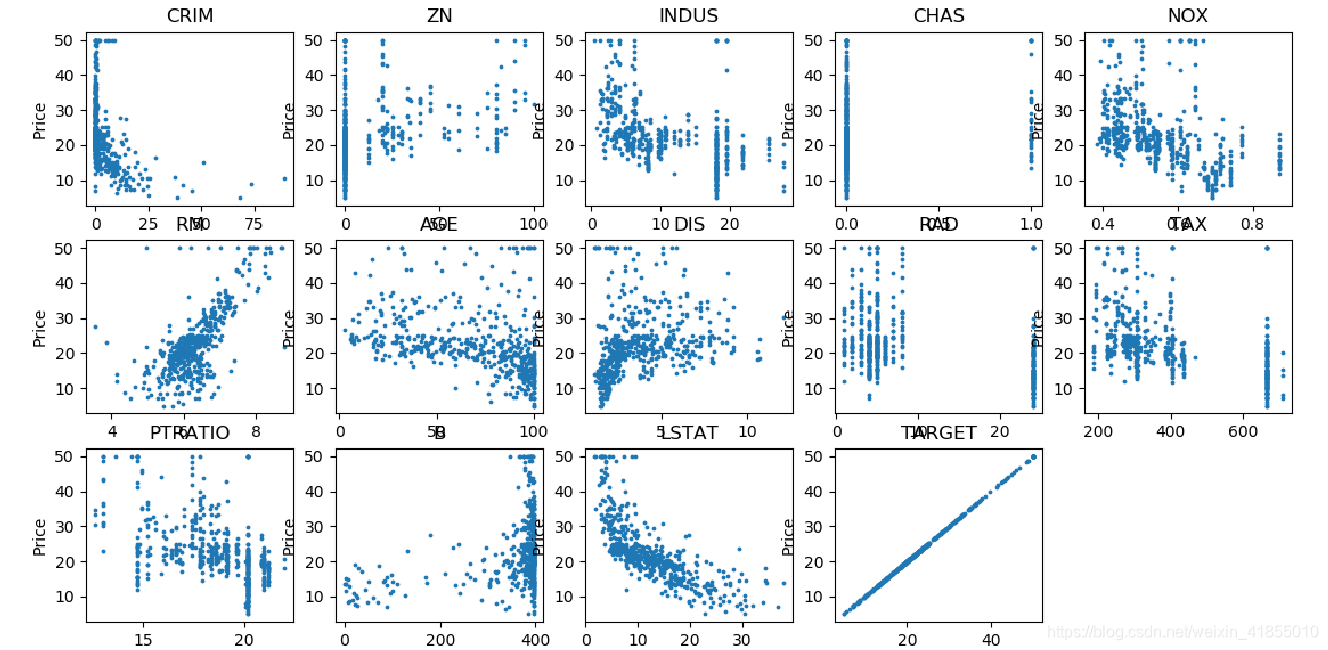
波士顿房价问题可视化:散点图感受价格相关因素数据分布
波士顿房价问题也是机器学习中的一个入门问题,sklearn这个模块中包含了500多条波士顿房价的数据,其中包括13个相关的因素。类似于鸢尾花数据可视化的处理(参考博文鸢尾花数据进行可视化展示)的处理方式,我们先把datasets的数据转换成我们熟悉的DF数据,这一次,我们是用python自带的matplot库中的方法来绘制散点图。具体的代码如下所示,其中用到了一些python的技巧,总结如下:
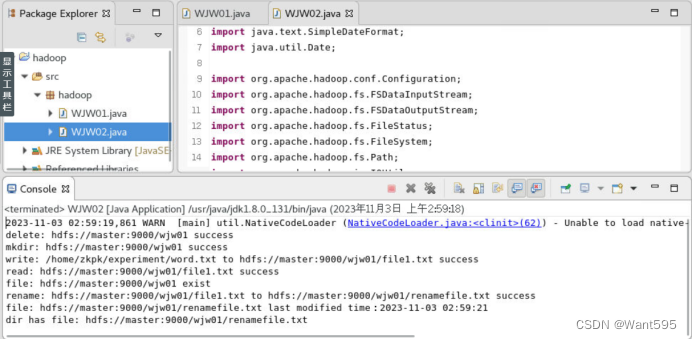
【大数据分布并行处理】实验测试(一)
文章目录 测试任务1测试任务2测试任务3 测试任务1 使用HDFS相关命令完成下列四个操作(20分) 操作1:在HDFS根目录创建以自己名字命名的目录,并查看是否创建成功(5分)。 提示:截图包括:创建命令及查验结果。 答:hadoop fs -mkdir 操作2:将/home/zkpk/experiment目录下,新建一个名为自己学号的文本文件(文件内容自拟),查看文件
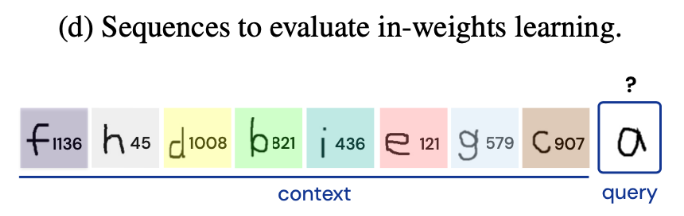
NeurIPS 2022|DeepMind最新研究:大模型背后的ICL可能与数据分布密切相关
NeurIPS 2022|DeepMind最新研究:大模型背后的ICL可能与数据分布密切相关 大模型自然语言处理机器学习 传统的文本语言模型倾向于两阶段的训练模式,即首先在大规模语料库上进行预训练,然后在目标下游任务上进行微调,这种方式会受数据标注质量和过拟合等多方面的影响。最近兴起并流行的大型语言模型(large language models,LLMs)已经克服了这类问题,并且会展现出惊人
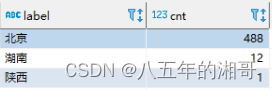
GEO地图数据分布处理
需求 已知访问用户经纬度数据,根据经纬度统计每个省的访问总数 地区经纬度分布表 CREATE TABLE `area_geo` (`id` int(11) NOT NULL,`name` varchar(250) NOT NULL COMMENT '地区名',`ext_name` varchar(255) NOT NULL COMMENT '地区扩展名',`geo` geometry NOT
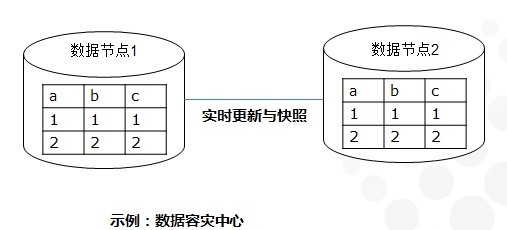
软件架构设计【三】-系统架构中的数据分布设计
在大型系统中,数据分布设计非常重要,整理数据分布设计的6中常见策略,仅供参考: 独立Schema:当一个大系统由相关的多个小系统组成,且不同小系统具有互不相同的数据库Schema定义。独立模式可管理性高,通信开销小。 集中:一个大系统必须支持来自不同地方的访问,或者该系统由多个不同的小系统组成,而数据进行集中化,统一格式存储。可管理性、数据一致性高。 分区:分为水平分

光流 数据空间和数据分布的概念--迁移学习人工智能基础(高中版)
https://www.cnblogs.com/LiYimingRoom/p/12095523.html 数据集:UCF101 Youbube 13320个视频,101分类 光流 深度学习视频行为识别 聚类 GAN 数据空间、数据分布 我们已经知道数据对人工智能系统的重要性,生成模型也不例外。假如,我们的目标是让计算机从无到有自动生成看起来像大牌明星的图片,就要提供大量的明星

单细胞数据分布 ZINB的理解
单细胞RNA测序(single-cell RNA-seq,scRNA-seq)数据是非常有特点的数据,具有很高的稀疏性(high sparsity),具体表现为0非常多(zero inflation)。对于数据的分布给出合理的假设是非常关键的工作,是downstream analysis的基础。显然对于scRNA-seq的reads count数据,最常用的正态分布是不合理的。首先正态分布描述的是

数据分布不均衡导致性能问题
今晚(2016/04/14)数据库版本11.2.0.4 遇到一个奇葩案例,虽然之前也遇到过非常多奇葩案例,但是限于当时条件,无法收集案例,谁叫他奶奶的银行,证券,电信不允许泄密啊。还好今晚这个案例可以拿出来分享。故事是这样的,下面这个SQL要跑几十分钟select count(distinct a.user_name), count(distinct a.invest_id)from base_

R实现数据分布特征的视觉化——多笔数据之间的比较
大家好,我是带我去滑雪! 如果要对两笔数据或者多笔数据的分布情况进行比较,Q-Q图、柱状图、星形图都是非常好的选择,下面开始实战。 (1)绘制Q-Q图 首先导入数据bankwage.csv文件,该数据集包含474条数据,变量分别是wage(数值)、wage0(数值)、edu(数值)、gender(字符)、minority(字符)、job(字符):