本文主要是介绍第⑯讲:Ceph集群Pool资源池管理以及PG的数据分布的核心技术要点,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1.Pool资源池的管理
- 1.1.查看Pool资源池列表
- 1.2.创建一个Pool资源池
- 1.3.查看Pool资源池的参数信息
- 1.4.修改Pool资源池的参数信息
- 1.5.为Pool资源池设置应用模式
- 1.6.重命名Pool资源池
- 1.7.设置Pool资源池的限额
- 1.8.删除Pool资源池
- 1.9.查看Pool资源池的利用率
- 2.PG的数据分布概念
1.Pool资源池的管理
1.1.查看Pool资源池列表
[root@ceph-node-1 ~]# ceph osd lspools
1 ceph-rbd-data
2 .rgw.root
3 default.rgw.control
4 default.rgw.meta
5 default.rgw.log
6 default.rgw.buckets.index
7 default.rgw.buckets.data
8 cephfs_metadata
9 cephfs_data
1.2.创建一个Pool资源池
语法格式:ceph osd pool create {pool-name} {pg-num} [{pgp-num}] [replicated] [crush-rule-name] [expected-num-objects]
[root@ceph-node-1 ~]# ceph osd pool create pool-test 3 3
pool 'pool-test' created
1.3.查看Pool资源池的参数信息
列出Pool资源池的所有参数
[root@ceph-node-1 ~]# ceph osd pool get pool-test

查看pool的副本数量
[root@ceph-node-1 ~]# ceph osd pool get pool-test size
size: 3查看pool的pg数量
[root@ceph-node-1 ~]# ceph osd pool get pool-test pg_num
pg_num: 3
1.4.修改Pool资源池的参数信息
设置pool的副本数
[root@ceph-node-1 ~]# ceph osd pool set pool-test size 1
set pool 10 size to 1
1.5.为Pool资源池设置应用模式
查看为Pool设置应用模式的命令格式,支持禁用、启用、查看、删除、设置等方式。
[root@ceph-node-1 ~]# ceph -h | grep application
osd pool application disable <poolname> <app> {-- disables use of an application <app> on pool
osd pool application enable <poolname> <app> {-- enable use of an application <app> [cephfs,rbd,
osd pool application get {<poolname>} {<app>} get value of key <key> of application <app> on
osd pool application rm <poolname> <app> <key> removes application <app> metadata key <key> on
osd pool application set <poolname> <app> <key> sets application <app> metadata key <key> to
为Pool设置应用模式。
[root@ceph-node-1 ~]# ceph osd pool application enable pool-test rbd
enabled application 'rbd' on pool 'pool-test'
查看Pool设置的应用模式。
[root@ceph-node-1 ~]# ceph osd pool application get pool-test
{"rbd": {}
}
1.6.重命名Pool资源池
[root@ceph-node-1 ~]# ceph osd pool rename pool-test pool-rename
pool 'pool-test' renamed to 'pool-rename'
1.7.设置Pool资源池的限额
同个限额可以调整资源池的最大Object文件数量等等参数。
[root@ceph-node-1 ~]# ceph osd pool set-quota pool-rename max_objects 10
set-quota max_objects = 10 for pool pool-rename
1.8.删除Pool资源池
[root@ceph-node-1 ~]# ceph osd pool delete pool-rename
Error EPERM: WARNING: this will *PERMANENTLY DESTROY* all data stored in pool pool-rename. If you are *ABSOLUTELY CERTAIN* that is what you want, pass the pool name *twice*, followed by --yes-i-really-really-mean-it.
直接删除会报错,报错的意思是说删除资源池会对其中的数据永久破坏,如果确认删除,则输入两次资源池的名称,然后根据提示信息加上–yes-i-really-really-mean-it参数进行删除。
[root@ceph-node-1 ~]# ceph osd pool delete pool-rename pool-rename --yes-i-really-really-mean-it
pool 'pool-rename' removed
1.9.查看Pool资源池的利用率
[root@ceph-node-1 ~]# rados df
POOL_NAME USED OBJECTS CLONES COPIES MISSING_ON_PRIMARY UNFOUND DEGRADED RD_OPS RD WR_OPS WR USED COMPR UNDER COMPR
.rgw.root 768 KiB 4 0 12 0 0 0 193 193 KiB 4 4 KiB 0 B 0 B
ceph-rbd-data 192 KiB 3 0 9 0 0 0 501 1.7 MiB 222 13 MiB 0 B 0 B
cephfs_data 0 B 0 0 0 0 0 0 0 0 B 4272 8 GiB 0 B 0 B
cephfs_metadata 2.8 MiB 23 0 69 0 0 0 9 425 KiB 381 647 KiB 0 B 0 B
default.rgw.buckets.data 1.9 MiB 8 0 24 0 0 0 102 253 KiB 305 493 KiB 0 B 0 B
default.rgw.buckets.index 0 B 3 0 9 0 0 0 366 388 KiB 147 70 KiB 0 B 0 B
default.rgw.control 0 B 8 0 24 0 0 0 0 0 B 0 0 B 0 B 0 B
default.rgw.log 0 B 207 0 621 0 0 0 287858 281 MiB 191830 0 B 0 B 0 B
default.rgw.meta 3 MiB 19 0 57 0 0 0 281 239 KiB 151 55 KiB 0 B 0 B
pool-rename 0 B 0 0 0 0 0 0 0 0 B 0 0 B 0 B 0 B total_objects 275
total_used 7.6 GiB
total_avail 62 GiB
total_space 70 GiB
2.PG的数据分布概念
PG的官方文档:https://docs.ceph.com/en/nautilus/rados/operations/placement-groups/#how-are-placement-groups-used
PG是建立在Pool资源池之上的,一个文件存储在OSD时,首先被拆分成多个Object文件,这些Object文件都是存储在Pool资源池的PG里的,PG最后再通过CRUSH算法将数据存储到OSD中。
如果一个Pool资源池中的PG数量很多,就意味着会通过CRUSH算法将Object数据分散写入到更多的OSD中,数据分散存储在OSD的数量越多,对于数据的安全性就越高,相反,如果Pool中的PG数量过少,那么通过CRUSH算法将数据分散存储到OSD的数量就越少,数据的丢失概率就会很高。
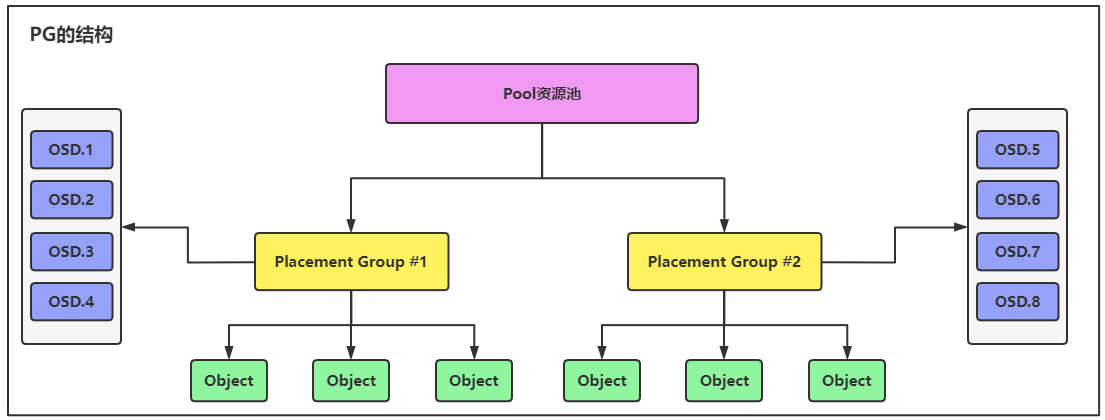
PG的作用有两种:
- 数据分布情况,如果PG的数量越多,那么数据就会分散在多个OSD中进行存储,降低数据丢失的概率,如果PG的数量很少,那么数据分散在OSD的数量也会随之减少,就会提高数据丢失的概率。
- 提高计算效率,如果没有PG的概念,一个文件会被拆分成多个Object文件,集群中就会有成千上万个Object,如果这些Object都由CRUSH进行计算,然后同步到OSD里,会大大降低集群的性能,有了PG的概念后,所有的Object都是存储在PG里的,CRUSH只需要根据PG进行计算就可以了,PG的数量远远要比Object的数量少很多。
集群中PG数量分配多少是合理的,是有具体计算公式的,如下所示,通过这个公式可用计算出集群中可以设置多少个PG。
(OSDs * 100)
Total PGs = ------------pool size
PG的数量是通过OSD的数量乘以100然后除以Pool的副本数得来的,这个100是指这个OSD中可以承载多少个PG数量。
每个OSD中最多只能容纳250个PG,PG的数量建议在100-200之间。
在使用公式计算PG的数量时,建议使用OSD*200,可以方便后期的数据量的扩展,随着数据量的增长,PG的数量也需要增长,如果一开始设置的数量很多,再后期就不需要扩容了。
注意这个公式只是计算出集群中有多少个PG合理,并不是计算的Pool拥有的PG数量。
例子:集群有200个OSD,Pool资源池的副本数为3。
(200x100)/3=6667
PG的数量建议是2的n次方,最接近6667的2的n次方是4096或者8192,为了方便后期的扩展,建议设置为8196个PG。
Ceph官方提供了一个PG计算器,地址为:http://ceph.com/pgcalc/,现在可能无法使用了。
pgcalc工具可以使用的使用,可用在这里添加Pool的一些参数(副本数、OSD的数量、数据使用比例、OSD可承载的PG数量)就可以计算出集群中PG的数量以及一个Pool设置多少个PG合理。
即使这个工具无法使用了,那也没有关系,还是有公式计算的。
在上面通过公式能够计算出集群合理的PG数量,下面的公式可以计算出一个Pool资源池分配多少个PG合理。
(OSDs * 100)
Pool PGs = -------------- * pool data percentpool size
"pool data percent"指的是该Pool将来可能存放的数据量占集群的百分比。
例子:OSD100个、OSD可承载的PG数量为200个、Pool副本数为3、该Pool的数据量占集群的15%。
(100X200)/3X0.15=1000个
1000接近2的n次方的值为1024,那么就建议这个Pool设置1024个PG。
这篇关于第⑯讲:Ceph集群Pool资源池管理以及PG的数据分布的核心技术要点的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






