本文主要是介绍软件架构设计【三】-系统架构中的数据分布设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在大型系统中,数据分布设计非常重要,整理数据分布设计的6中常见策略,仅供参考:
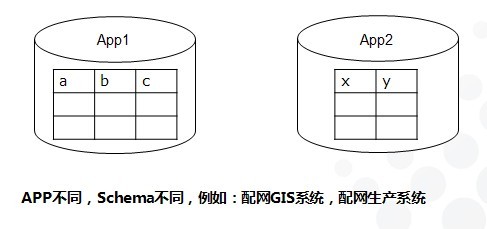
独立Schema:当一个大系统由相关的多个小系统组成,且不同小系统具有互不相同的数据库Schema定义。独立模式可管理性高,通信开销小。
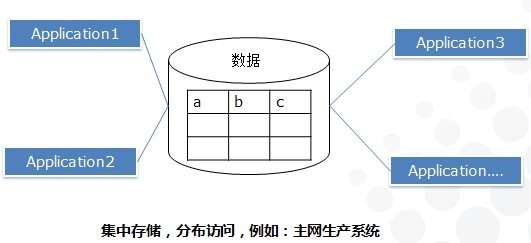
集中:一个大系统必须支持来自不同地方的访问,或者该系统由多个不同的小系统组成,而数据进行集中化,统一格式存储。可管理性、数据一致性高。
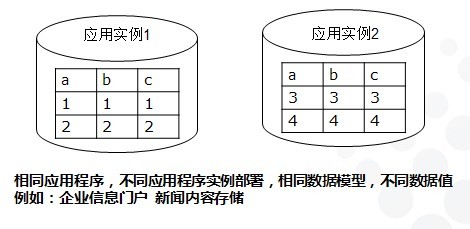
分区:分为水平分析与垂直分区,当系统为“地域分布广泛的用户”提供“相同服务”时,常常使用水平分区策略。垂直分区为字段分隔,一般较少使用。采用分区方式,可伸缩性好。
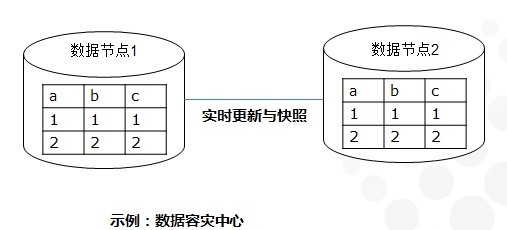
复制:在整个分布式系统中,保存多个副本、并且以某种机制保持多个数据副本之间的数据一致性。复制方式可有效提升数据可靠性。
子集:“子集”是“复制”的特殊方式,就是某节点因功能或非功能考虑而保持全体数据的一
这篇关于软件架构设计【三】-系统架构中的数据分布设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






