本文主要是介绍R实现数据分布特征的视觉化——多笔数据之间的比较,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大家好,我是带我去滑雪!
如果要对两笔数据或者多笔数据的分布情况进行比较,Q-Q图、柱状图、星形图都是非常好的选择,下面开始实战。
(1)绘制Q-Q图
首先导入数据bankwage.csv文件,该数据集包含474条数据,变量分别是wage(数值)、wage0(数值)、edu(数值)、gender(字符)、minority(字符)、job(字符):
bankwage=read.csv("bankwage.csv")
目的:尝试比较员工薪酬上是否存在性别差异。
mwage = subset(bankwage, gender == "Male")$wage_current
fwage = subset(bankwage, gender == "Female")$wage_current
qqplot(mwage, fwage, xlim = range(wage_current), ylim = range(wage_current), xaxs = "i", yaxs = "i", xlab = "Male workers' wage", ylab = "Female workers' wage")
abline(0, 1)输出结果:
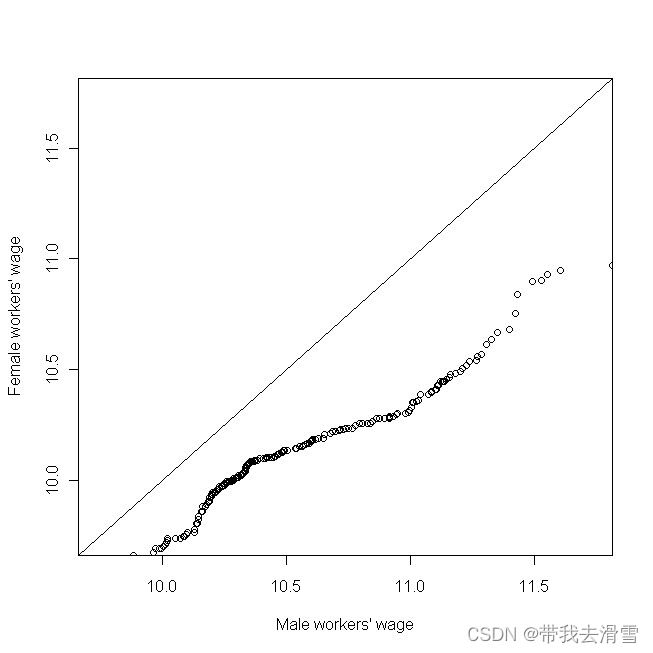
通过图像,可以发现薪酬分布倾向男性,说明男性和女性在薪酬上存在性别差异。
(2)绘制柱状图
数据采用国际上13个交易市场的市价总值数据,目的是比较多个市场市价总值2003年到2008年的差别情况,使用柱状图呈现数据。
load("Cap.RData")
par(mfrow=c(2,1))
barplot(t(Cap)/1e+06, beside = T,las=3,ylab="Capitalization")
title(main = "Major Stock Markets")
mtext(side = 3, "2003 - 2008")
barplot(Cap/1e+06, beside = TRUE,ylab="Capitalization")
par(mfrow=c(1,1))输出结果:
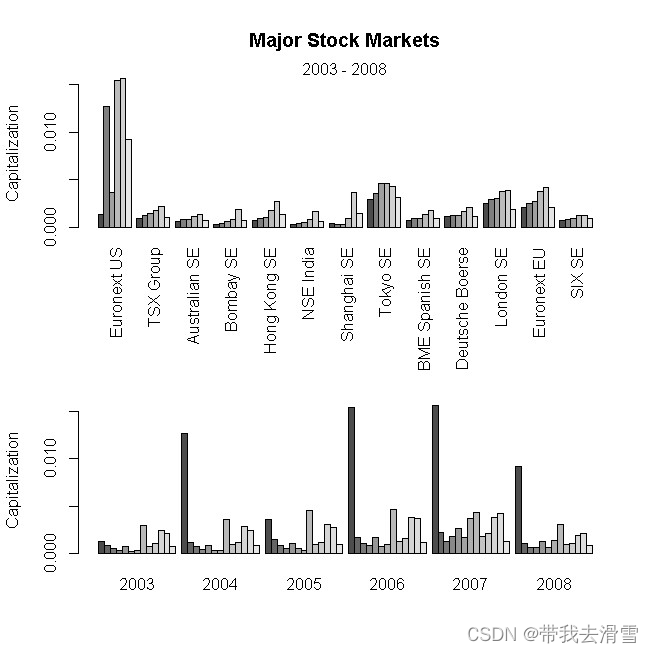
(3)星形图
星形图(Star Plot),也称为雷达图(Radar Plot)或蜘蛛图(Spider Plot),是一种用于可视化多维数据的图表类型。它以一个多边形的形式显示了多个变量或特征的值,使您能够比较各个特征之间的相对大小和分布。星形图通常用于展示数据的多维特征,特别适用于在不同类别或维度上比较多个观测值的情况。
palette(rainbow(13, s = 0.6, v = 0.75))
stars(t(log(Cap)), draw.segments = TRUE, ncol = 3, nrow = 2,
key.loc = c(4.6, -0.5), mar = c(15, 0, 0, 0))
mtext(side = 3, line = 2.2, text = "Growth and Decline of Major Stock Markets",
cex = 1.5, font = 2)
abline(h = 0.9)
输出结果:
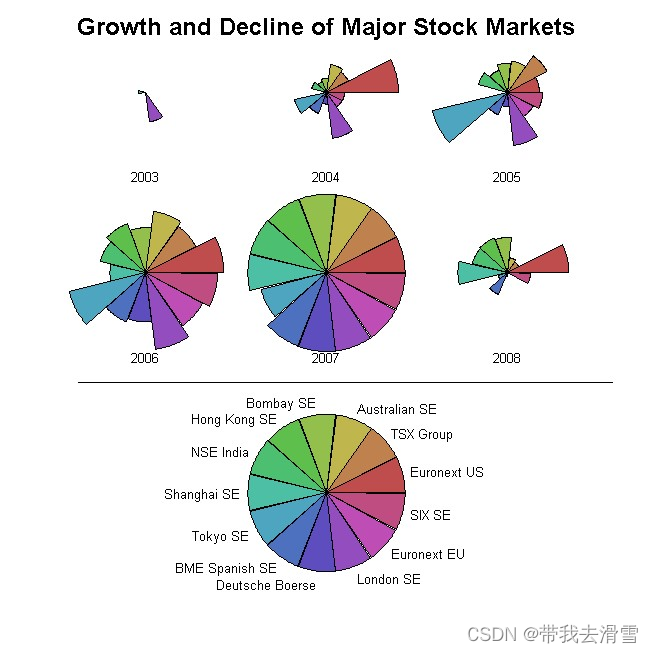
(4)相关性绘图
分析数值型数据时,变量间的相关性是一项重点,使用corrgram()函数用图形及其组合将相关系数矩阵可视化。可以通过图形色彩、形状等特征轻松地判断相关性是正还是负,甚至相关系数是否显著。
library(corrgram)
data(auto)
head(auto)
vars_name = setdiff(colnames(auto), c("Model", "Origin"))
low=panel.conf
up=panel.pie
txt=panel.txt
diag=NULL #or panel.minmax
corrgram(auto[, vars_name],lower.panel=low, upper.panel=up, text.panel=txt,diag.panel=diag, order=TRUE, main="Auto data (PC order)")输出结果:

更多优质内容持续发布中,请移步主页查看。
点赞+关注,下次不迷路!
这篇关于R实现数据分布特征的视觉化——多笔数据之间的比较的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



