本文主要是介绍【大数据分布并行处理】实验测试(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 测试任务1
- 测试任务2
- 测试任务3
测试任务1
使用HDFS相关命令完成下列四个操作(20分)
操作1:在HDFS根目录创建以自己名字命名的目录,并查看是否创建成功(5分)。
提示:截图包括:创建命令及查验结果。
答:hadoop fs -mkdir

操作2:将/home/zkpk/experiment目录下,新建一个名为自己学号的文本文件(文件内容自拟),查看文件内容,上传到HDFS根目录下(操作1中)新建的目录下,并查验是否成功(5分)。
提示:截图包括:创建文件和上传命令及查验结果。
答:hadoop fs -put

操作3:在/home/zkpk下新建目录,目录用自己喜欢的电影名或演员名字命名,并下载操作2中新建的文件到该目录中(5分)。
提示:截图包括:新建目录(使用命令创建目录)、下载命令及查验结果。
答:hadoop fs -get

操作4:删除HDFS根目录下操作1中新建的目录(5分)
提示:截图包括:删除命令、查验命令及查验结果。
答:hadoop fs -rmr

测试任务2
输出一个目录下多个文件的文件状态和元数据信息,目录和多个文件名自拟,文件内容自拟(30分)

(1)给出完整代码(20分);
package hadoop;import java.io.IOException;
import java.net.URI;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;public class WJW01 {public static void main(String[] args){Configuration conf = new Configuration();conf.set("fs.DefailtFS", "hdfs://master:9000/");FileSystem fs = null;Path path[] = new Path[args.length];for(int i=0; i<path.length; i++){path[i] = new Path(args[i]);}try{fs = FileSystem.get(URI.create(args[0]), conf);org.apache.hadoop.fs.FileStatus[] filestatus = fs.listStatus(path);Path listPaths[]=FileUtil.stat2Paths(filestatus);for(Path p:listPaths){System.out.println(p);System.out.println(p.getName());for(int i=0; i<filestatus.length;i++){System.out.println(filestatus[i]);}}}catch(IOException e){e.printStackTrace();}}}
这是一个使用Hadoop Java API获取HDFS中指定路径下的文件和文件夹的程序。
程序中通过传入命令行参数来获取需要查看的路径,然后通过Hadoop提供的API获取FileSystem对象,从而访问HDFS。接着使用listStatus方法获取指定路径下的所有文件和文件夹的FileStatus对象,再通过FileUtil类中的方法将FileStatus对象转为Path对象。最终循环遍历Path对象输出文件和文件夹的名称。
需要注意的是,在程序中设置了Hadoop集群的默认文件系统为hdfs://master:9000/,如果需要修改需要在conf.set()方法中修改。同时,在获取FileSystem对象时使用了URI.create(args[0]), 这是因为FileSystem.get(URI uri, Configuration conf)方法的参数需要传入URI类型的对象,而args[0]中保存的是需要查看的路径,因此需要进行转换。
另外,程序中使用了try-catch语句处理可能出现的IOException异常。
(2)分别在本地测试和集群进行测试,并给出测试效果截图(10分)
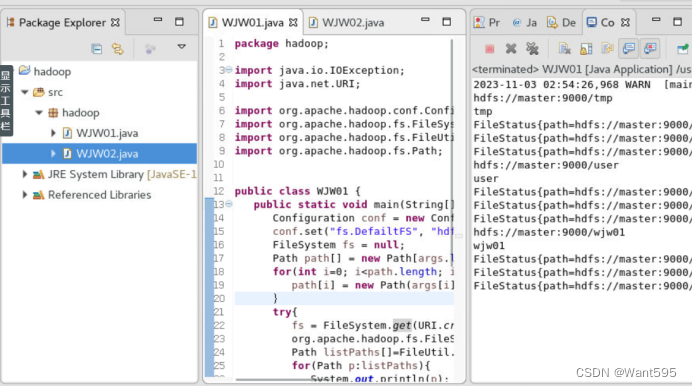
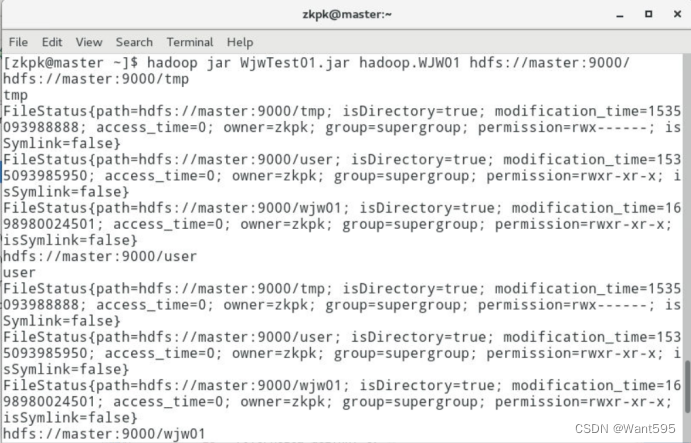
测试任务3
综合操作,创建一个类,实现目录文件的创建、删除、读取与写入、重命名、查看是否存在,查看某目录下文件路径信息和文件的最后一次修改时间等操作,测试效果参考下图,要求文件名和目录名自拟,体现个人姓名或学号信息。(50分)
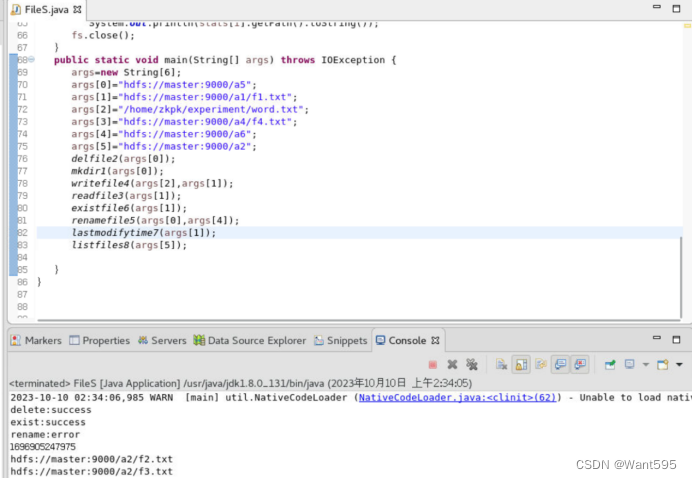
(1)给出完整代码(30分)
package hadoop;import java.io.BufferedInputStream;
import java.io.FileInputStream;
import java.io.IOException;
import java.text.SimpleDateFormat;
import java.util.Date;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;public class WJW02 {public static Configuration conf = new Configuration();public static void Read(String[] args) throws IOException {conf.set("fs.defaultFS", "hdfs://master:9000");FileSystem fs = FileSystem.get(conf);FSDataInputStream in =fs.open(new Path(args[2]));IOUtils.copyBytes(in, System.out, 4096, false);System.out.println("read: " + args[2] + " success");}public static void Write(String[] args) throws IOException {conf.set("fs.defaultFS", "hdfs://master:9000");BufferedInputStream in = new BufferedInputStream(new FileInputStream(args[1]));FileSystem fs = FileSystem.get(conf);FSDataOutputStream out = fs.create(new Path(args[2]));IOUtils.copyBytes(in, out, 4096, false);System.out.println("write: " + args[1] + " to " + args[2] + " success");}public static void Mkdir(String[] args) throws IOException {conf.set("fs.defaultFS", "hdfs://master:9000");FileSystem fs = FileSystem.get(conf);fs.mkdirs(new Path(args[0]));System.out.println("mkdir: " + args[0] +" success");}public static void Delete(String[] args) throws IOException {conf.set("fs.defaultFS", "hdfs://master:9000");FileSystem fs = FileSystem.get(conf);fs.delete(new Path(args[0]), true);System.out.println("delete: " + args[0] + " success");}public static void Rename(String[] args) throws IOException {conf.set("fs.defaultFS", "hdfs://master:9000");FileSystem fs = FileSystem.get(conf);Path ori = new Path(args[2]);Path dest = new Path(args[3]);boolean result = fs.rename(ori, dest);if (result) {System.out.println("rename: " + args[2] + " to " + args[3] + " success");} else {System.out.println("rename not success");}}public static void Exist(String[] args) throws IOException {conf.set("fs.defaultFS", "hdfs://master:9000");FileSystem fs = FileSystem.get(conf);boolean result = fs.exists(new Path(args[0]));fs.close();if(result==true){System.out.println("file: " + args[0] + " exist");}else{System.out.println("file: " + args[0] + " not exist");}}public static void LastModifyTime(String[] args) throws IOException{conf.set("fs.defaultFS", "hdfs://master:9000");FileSystem fs = FileSystem.get(conf);Path path = new Path(args[3]);if (fs.exists(path)) {FileStatus fileStatus = fs.getFileStatus(path);long modificationTime = fileStatus.getModificationTime();String lastModifiedTime = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss").format(new Date(modificationTime));System.out.println("file: " + args[3] + " last modified time\uff1a" + lastModifiedTime);}else{System.out.println("file: " + args[3] + " not exist");}}public static void ListFiles(String[] args) throws IOException{conf.set("fs.defaultFS", "hdfs://master:9000");FileSystem fs = FileSystem.get(conf);Path path = new Path(args[0]);if (fs.isDirectory(path)) {FileStatus[] fileStatuses = fs.listStatus(path);for (FileStatus fileStatus : fileStatuses) {System.out.println("dir has file: " + fileStatus.getPath());}} else {System.out.println("dir: " + args[0] + " not exist");}}public static void main(String[] args) throws IOException{args = new String[6];args[0] = "hdfs://master:9000/wjw01";args[1] = "/home/zkpk/experiment/word.txt";args[2] = "hdfs://master:9000/wjw01/file1.txt";args[3] = "hdfs://master:9000/wjw01/renamefile.txt";Delete(args);Mkdir(args);Write(args);Read(args);Exist(args);Rename(args);LastModifyTime(args);ListFiles(args);}
}
这是一个使用Hadoop Java API操作HDFS的程序,包含了创建目录、删除文件、重命名文件、判断文件是否存在、获取文件最后修改时间、列出目录下的文件等功能。
程序中使用了Hadoop提供的API,通过FileSystem类的get()方法获取FileSystem对象,然后使用该对象进行文件和文件夹的操作。
具体实现如下:
- Mkdir 方法
该方法用于创建目录,首先设置Hadoop集群的默认文件系统为hdfs://master:9000,然后获取FileSystem对象,最后调用FileSystem对象的mkdirs()方法创建目录。
- Delete 方法
该方法用于删除文件,同样首先设置Hadoop集群的默认文件系统为hdfs://master:9000,获取FileSystem对象,然后使用FileSystem对象的delete()方法删除指定路径下的文件或目录,第二个参数设置为true表示递归删除所有文件和目录。
- Rename 方法
该方法用于重命名文件,同样首先设置Hadoop集群的默认文件系统为hdfs://master:9000,获取FileSystem对象,然后使用FileSystem对象的rename()方法将原文件路径重命名为目标文件路径。
- Write 方法
该方法用于将本地文件写入到HDFS中,通过BufferedInputStream读取本地文件,然后创建FileSystem对象并调用create()方法创建文件输出流,最后使用IOUtils类中的copyBytes()方法将数据从输入流拷贝到输出流。
- Read 方法
该方法用于读取HDFS中的文件,首先获取FileSystem对象,然后使用FSDataInputStream对象读取文件内容,最后使用IOUtils类中的copyBytes()方法将数据从流中拷贝到控制台。
- Exist 方法
该方法用于判断文件或目录是否存在,获取FileSystem对象后使用FileSystem对象的exists()方法判断文件是否存在。
- LastModifyTime 方法
该方法用于获取文件的最后修改时间,同样获取FileSystem对象后使用FileSystem对象的getFileStatus()方法获取文件状态,然后使用FileStatus对象的getModificationTime()方法获取最后修改时间,最后使用SimpleDateFormat类将时间转换为指定格式。
- ListFiles 方法
该方法用于列出指定目录下的文件信息,首先获取FileSystem对象,然后使用FileSystem对象的listStatus()方法获取目录下的文件状态数组,最后遍历数组输出文件的路径。
程序中使用main()方法调用上述方法,对HDFS进行增删改查等操作。
(2)分别给出本地和集群测试效果截图(20分)
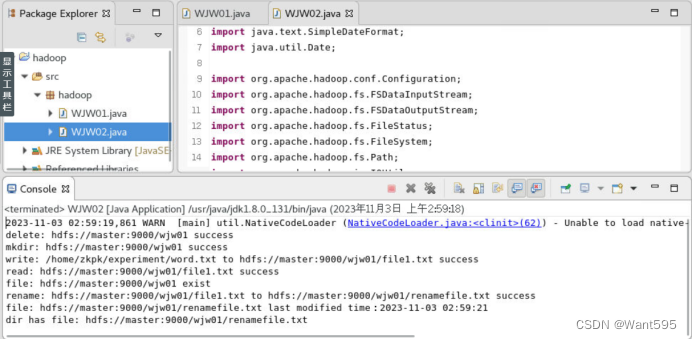
这篇关于【大数据分布并行处理】实验测试(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







