影评专题

python手写了个简易的豆瓣影评爬虫
使用python手写了个简易的豆瓣影评爬虫代码。 __author__ = 'wsx'import timeimport requestsfrom bs4 import BeautifulSoupimport osimport reimport uuiddef clean_windows_filename(string_file_name):invalid_chars = r'[\\/

python : Requests请求库入门使用指南 + 简单爬取豆瓣影评
Requests 是一个用于发送 HTTP 请求的简单易用的 Python 库。它能够处理多种 HTTP 请求方法,如 GET、POST、PUT、DELETE 等,并简化了 HTTP 请求流程。对于想要进行网络爬虫或 API 调用的开发者来说,Requests 是一个非常有用的工具。在今天的博客中,我将介绍 Requests 的基本用法,并提供一个合理的爬虫实例。 一.安装 Requests
【实战项目二】Python爬取豆瓣影评
目录 一、环境准备 二、编写代码 一、环境准备 pip install beautifulsoup4pip intall lxmlpip install requests 我们需要爬取这些影评 二、编写代码 我们发现每个影评所在的div的class都相同,我们可以从这入手 from bs4 import BeautifulSoupimport req
《罗曼蒂克消亡史》影评
--转载自知乎用户 我桃桃渡河而来 作者:我桃桃渡河而来 链接:https://www.zhihu.com/question/49954922/answer/137945152 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 很久没看过这么一部有腔调的片子了。 如何评价呢? 其实就是一个不合格的黑帮大佬,一个不合格的间谍,一个不合格的欢场女
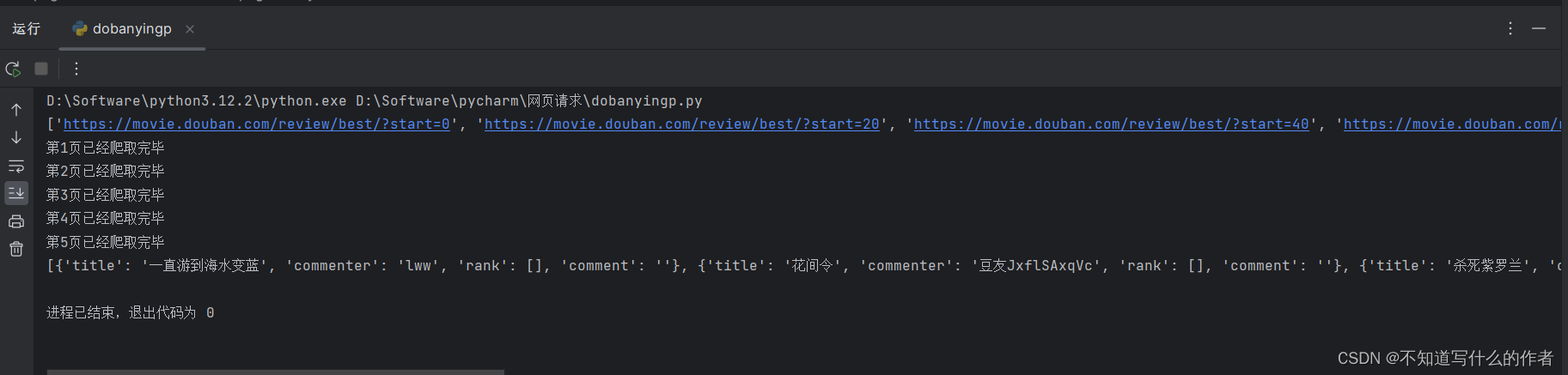
豆瓣影评信息爬取 (爬虫)
代码块: from lxml import etreeimport requestsheaders={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0'}url_l
基于豆瓣影评数据的文本分析系统【数据爬取+数据清洗+数据库存储+LDA主题挖掘+词云可视化】
本分析中很多的工作都是基于评论数据来进行的,比如:滴滴出行的评价数据、租房的评价数据、电影的评论数据等等,从这些语料数据中能够挖掘出来客户群体对于某种事物或者事情的看法,较为常见的工作有:舆情分析、热点挖掘和情感分析。 如果想要了解关于文本分类或者是情感分析相关的工作内容,可以阅读我的《数据建模实战》专栏文章,下面是链接信息:

Python—豆瓣影评的爬取(指环王)
之前闲着无聊,也不知哪里找到的这部电影,每一部都是快4个小时,看的,,,,,不过画面很美 编译环境:pycharm 需要导入的第三方库:requests 、BeautifulSoup、random 具体过程如下: 1.导入第三方库:具体方法见博客——>Python——爬取单章小说内容 2.关于豆瓣爬虫,我个人觉得豆瓣网是有反爬虫机制的,不过我的经验还是太少,只知道加请求头这一种方式来进

真北影评|没有半途而废的人生#三大队
我要走穿这条命去看雪兰花 我要踏破这双鞋光脚平风沙 我要白日见云霞夜里举火把 我要这朗朗乾坤下事事有王法 苦雨江头风波恶 做人一生坎坷多 大江歌罢掉头东 邃密群科济世穷 面壁十年图破壁 难酬蹈海亦英雄 今番良晤,豪兴不浅,他日江湖相逢,再当杯酒言欢。咱们就此别过。 你看这天上的云,聚了又散。 散了又聚,人生离合,亦复如斯。 满面尘灰烟火色,两鬓苍苍十指黑。 卖炭得钱何所营?身上衣裳
{我喜欢你,就像喜欢当时的自己。}---《那些年,我们一起追的女孩》影评。(By:Janice)
沈佳仪是2011年最幸运的女孩,因为一部电影,全世界都知道了她是著名作家九把刀喜欢过的女孩。这部电影是《那些年,我们一起追的女孩》。 故事发生在90年代的台湾彰化。 那时候,华视上演着港剧《鹿鼎记》,梁朝伟演韦小宝,刘德华演康熙皇帝。 井上雄彦的漫画灌篮高手,连载到湘北与海南附属大争夺神奈川在全国大赛的出赛权。 张学友的“每天多爱你一

运用python模拟登录豆瓣爬取并分析某部电影的影评
前段时间奉俊昊的《寄生虫》在奥斯卡上获得不少奖项,我也比较喜欢看电影,看过这部电影后比较好奇其他人对这部电影的看法,于是先用R爬取了部分豆瓣影评,jieba分词后做了词云了解,但是如果不登录豆瓣直接爬取影评只可以获得十页短评,这个数据量我认为有点少,于是整理了python模拟登录豆瓣,批量爬取数据,制作特别样式词云的方法。 一、 用到的Python库 import os ##提供访问操作系统服
python爬取豆瓣影评,涉及知识点:bs4,requests、time、random
页面源代码: <!DOCTYPE html><html lang="zh-CN" class="ua-windows ua-webkit"><head><meta http-equiv="Content-Type" content="text/html; charset=utf-8"><meta name="renderer" content="webkit"><meta name="re

利用selenium爬取《西虹市首富影评》
目标网址:豆瓣网 'https://movie.douban.com/subject/27605698/comments?status=P' 使用工具:python+selenium 首先,很简单的,我们得使用selenium的webdriver去打开网址,自动实现打开网页,并且翻页: selenium环境确保搭建完毕(如果没有搭建好,公众号python乱炖回复:selenium) 那我们
java+springboot电影订票选座及评论网站影评系统ssm+vue
广大观影消费者需要知道自己的空闲时间,在自己可以接受的地理距离范围内,是否有感兴趣的影片可供观看,也需要清楚哪家影院在销售自己需要的电影票;同时手握电影排期及上映信息的电影院的运营者也急需根据消费者的观影需求实时调整经营策略,这种买卖双方之间的信息交流需求更促进了“电影订票及评论网站”发展 ide工具:IDEA 或者eclipse 编程语言: java 数据库: mysql5.7+ 框架:ss

【python】爬取豆瓣影评保存到Excel文件中【附源码】
欢迎来到英杰社区https://bbs.csdn.net/topics/617804998 【往期相关文章】 爬取豆瓣电影排行榜Top250存储到Excel文件中 爬取豆瓣电影排行榜TOP250存储到CSV文件中 爬取知乎热榜Top50保存到Excel文件中 爬取百度热搜排行榜Top50+可视化 爬取斗鱼直播照片保存到本地目录 爬取酷狗音乐Top500排行榜 一、效果图:

jieba+wordcloud分析豆瓣惊奇队长影评
复联三过后或许你还惊魂未定就被惊奇队长里的噬元兽吓到恐猫,whatever,本文将会介绍如何从豆瓣爬取惊奇队长的短评并加工处理生成词云。 爬取评论 首先还是爬取评论,老规矩用requests和BeautifulSoup就行。通过查看网页源码容易发现所有的短评都放在span标签中且class为short,这样就很方便了,用find_all就完事了。 # -*- coding:utf-8 -*-

python 豆瓣电影影评数据可视化
import requestsfrom bs4 import BeautifulSoupimport pandas as pdu1 = "https://movie.douban.com/subject/26100958/comments?start=0&limit=20&sort=new_score&status=P"def urls(): # 获取多个网址urllist = []val

《长津湖》影评文本数据清洗--(简易版)
《长津湖》python文本数据清洗 文章目录 《长津湖》python文本数据清洗1.项目背景2.研究路线3.方案实施3.1数据清洗(某个案例)3.2数据可视化 1.项目背景 《长津湖》作为近年比较火的电影,它用来致敬曾经伟大的战斗前辈。此次项目为用python 和Kettle 对爬取到的《长津湖》电影短评进行数据清洗与数据可视化分析,然后应用python连接数据库技


影评 August Rush
电影开头,小男孩站在一片无垠的青草里,闭上双眼,双手舞动着,感触着,指挥着。大自然的声音是最华美的乐章 小男孩在孤儿院里,没有声音时,对着月亮说话,他相信心中的旋律来自父母,并且追随。。。 镜头切换,两个才华横溢地年轻人,不羁的乐队主唱和美丽的大提琴演奏家,他们倾听着同一曲美妙音乐邂逅,一见钟情短暂一

《谁的青春不迷茫》影评
昨天在回杭的高铁上,想要清理手机时看了这部在手机上放了很久都没看的电影,能拜托堕胎、车祸这样的青春片代名词,是这部电影值得肯定的地方,毕竟这些肯定不是大部分人青春最重要的东西。 在这个青春片泛滥的年代,电影《谁的青春不迷茫》摆脱了内地很多青春片惯有的那种车祸、堕胎的剧情,而让大众对这部电影增加了一丝好感。整部电影剧情简单,没有过多的意外与起伏。影片中女主叫林天娇,正如她的名字一样,她是一个

爬虫实战之《流浪地球》豆瓣影评分析(三)
4. 分析评论数量及评分与时间的关系 首先导入数据,进行一个初步的统计: import pandas as pddata = pd.read_csv('doubanliulangdiqiu.csv',encoding ='GB18030')data['评分'].value_counts() 可以看到这样的情况: 如果没有数据,可以去看爬虫实战之《流浪地球》豆瓣影评分析(一)的爬取过程
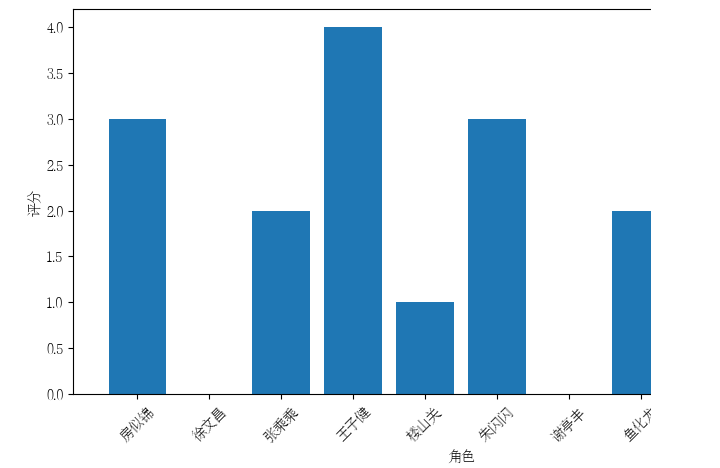
【深度学习】Python爬取豆瓣实现影评分析
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、任务描述二、使用步骤1.数据爬取1.2.对爬取的页面数据进行解析,并保存为JSON文件2、数据分析2.1数据分析之评论时间分布图2.2角色评分 前言 爬虫的过程,就是模仿浏览器的行为,往目标站点发送请求,接收服务器的响应数据,提取需要的信息,并进行保存的过程。 Python为爬虫的

RNN实现影评情感分析
在这里我们将使用RNN(循环神经网络)对电影评论进行情感分析,结果为positive或negative,分别代表积极和消极的评论。至于为什么使用RNN而不是普通的前馈神经网络,是因为RNN能够存储序列单词信息,得到的结果更为准确。这里我们将使用一个带有标签的影评数据集进行训练模型。 使用的RNN模型架构如下: 在这里,我们将单词传入到嵌入层而不是使用ONE-HOT编码,是因为词嵌入是一种
NLP自然语言处理-英文文本电影影评分类1-pytorch版本
imdb电影影评数据集下载地址:传送门 点击下载后解压。 像这样放置数据集,所有代码放置在imdb_sentiment文件夹下面。在imdb_sentiment/data/下放置训练集合测试集。 imdb_sentiment/models文件夹下放置处理后的数据集 运行代码只有3部分,dataset制作数据集,build_vocab建立数据模型,lstm_model使用lstm算
爬虫:python采集豆瓣影评信息并进行数据分析
前言:最近比较有时间,替一个同学完成了一个简单的爬虫和数据分析任务,具体的要求是爬取复仇者联盟4 的豆瓣影评信息并进行简单的数据分析,这里的数据分析指的是提取关键词并进行词云分析以及按照时间进行热度分析,分析比较简单,后续可以继续完善。 首先,献上数据采集和分析的结果。 短评数据 按照该同学的要求,只采集了1000条数据,有需要更多数据的同学可自行修改采集的限制即可 下面,我们就来详细