本文主要是介绍NLP自然语言处理-英文文本电影影评分类1-pytorch版本,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
imdb电影影评数据集下载地址:传送门

点击下载后解压。
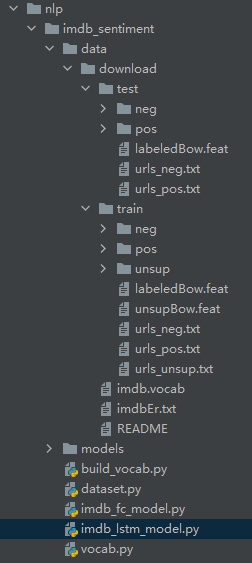
像这样放置数据集,所有代码放置在imdb_sentiment文件夹下面。在imdb_sentiment/data/下放置训练集合测试集。
imdb_sentiment/models文件夹下放置处理后的数据集
运行代码只有3部分,dataset制作数据集,build_vocab建立数据模型,lstm_model使用lstm算法进行训练模型,先来看数据集制作部分。代码如下:
# -*-coding:utf-8-*-
import os
import pickle
import re
import zipfile
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdmclass ImdbDataset(Dataset): #数据集制作定义def __init__(self, train=True):# super(ImdbDataset,se这篇关于NLP自然语言处理-英文文本电影影评分类1-pytorch版本的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






