本文主要是介绍豆瓣影评信息爬取 (爬虫),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
代码块:
from lxml import etree
import requestsheaders={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0'
}url_list=[]
for i in range(0,5):i*=20urls=f"https://movie.douban.com/review/best/?start={i}"url_list.append(urls)
print(url_list)detail_urls=[]
for url in url_list:response=requests.get(url,headers=headers)# print(response.status_code)content = response.content.decode('utf8')html=etree.HTML(content)detail_url = html.xpath('//div[@class="main-bd"]/h2/a/@href')detail_urls.append(detail_url)# print(detail_urls)# breakmovies=[]
i=0
# 循环豆瓣网页的每一页
for page in detail_urls:# 循坏这页的网页每个连接for url in page:try:response=requests.get(url,headers=headers)content=response.content.decode('UTF-8')html=etree.HTML(content)# 抓取电影名# // *[ @ id = "content"] / div / div[2] / div[4] / div[2] / atitle=html.xpath('//div[@class="subject-title"]/a/text()')[0][2:]# 抓取评论者和评分commenter=html.xpath('//header/a/span/text()')[0]rank=html.xpath('//heafer//span/@title')# 抓影评comment=html.xpath('//div[@id="link-report"]//p/text()')comment=''.join(comment)movie={"title":title,"commenter":commenter,# "rank":rank,# "comment":comment}movies.append(movie)except:continuei+=1print(f"第{i}页已经爬取完毕")print(movies)
效果:
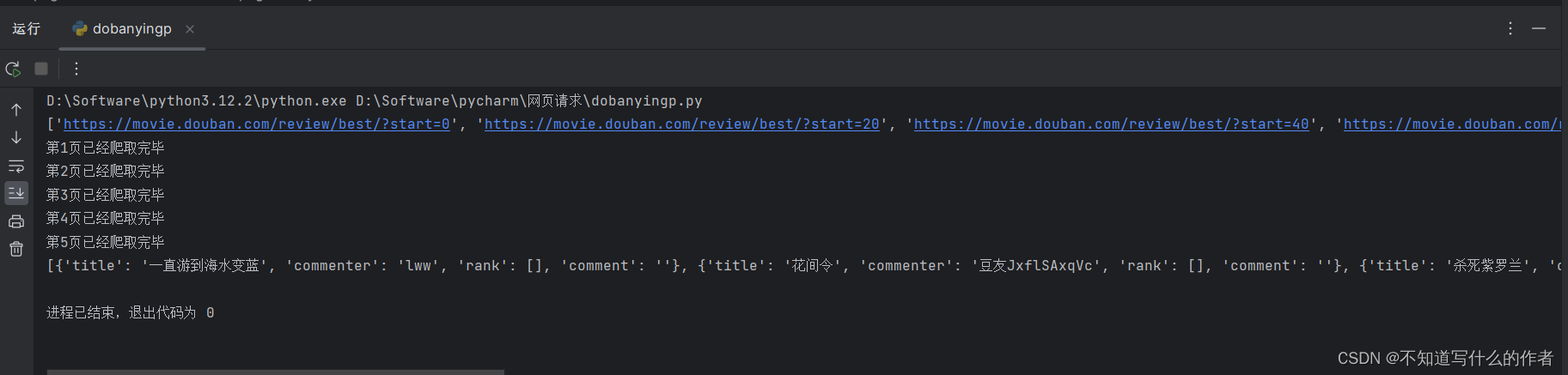
内容解释:
-
etree.HTML(内容):将不是html的格式的内容转换成html
-
etree.tostring(内容,encoding=‘UTF-8’).decode(‘UTF-8’):如果不是UTF-8编码格式的内容,这里可以更改成UTF-8的内容
-
etree.parse(文件路径):parse对html导入python并解析
-
自定解析器:
如果在浏览器上保存网页到本地,在python中获取.html文件需要利用自定解析器来解析文件内容
# 自定解析器
parser=etree.HTMLParser(encoding='UTF-8')
html=etree.parse(路径,parser=parser)
result=etree.tostring(html,encoding='UTF-8').decode('UTF-8')
xpath中的[1]表示第一个元素,而python中的第一个是从0开始,例如:[0]
这篇关于豆瓣影评信息爬取 (爬虫)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






