豆瓣专题

Python:豆瓣电影商业数据分析-爬取全数据【附带爬虫豆瓣,数据处理过程,数据分析,可视化,以及完整PPT报告】
**爬取豆瓣电影信息,分析近年电影行业的发展情况** 本文是完整的数据分析展现,代码有完整版,包含豆瓣电影爬取的具体方式【附带爬虫豆瓣,数据处理过程,数据分析,可视化,以及完整PPT报告】 最近MBA在学习《商业数据分析》,大实训作业给了数据要进行数据分析,所以先拿豆瓣电影练练手,网络上爬取豆瓣电影TOP250较多,但对于豆瓣电影全数据的爬取教程很少,所以我自己做一版。 目

爬虫二:获取豆瓣电影Top250(Requests+XPath+CSV)
描述: 在上一篇获取豆瓣图书Top250的基础上,获取豆瓣电影Top250的数据并将结果写入CSV文件中。 代码: # -*- coding: UTF-8 -*-import requestsfrom lxml import etreeimport timeimport csv# 从网页上获取电影数据moviedata = []count = 0for i in range(1

爬虫一:获取豆瓣图书Top250(Requests+XPath)
目的: 获取豆瓣图书Top250的所有书目信息。 豆瓣网址:https://book.douban.com/top250 代码: import requestsfrom lxml import etreeimport timefor i in range(10):url = 'https://book.douban.com/top250?start=' + str(25*i)data

计算机毕设选题推荐-基于python的豆瓣电子图书数据可视化分析
💖🔥作者主页:毕设木哥 精彩专栏推荐订阅:在 下方专栏👇🏻👇🏻👇🏻👇🏻 实战项目 文章目录 实战项目 一、基于python的豆瓣电子图书数据可视化分析-项目介绍二、基于python的豆瓣电子图书数据可视化分析-视频展示三、基于python的豆瓣电子图书数据可视化分析-开发环境四、基于python的豆瓣电子图书数据可视化分析-项目展示五、基于python的豆瓣电子图

Python 爬虫爬取豆瓣电影列表信息,爬虫的原理,应用领域介绍学习
1. 什么是Python 爬虫 定义:爬虫是一种自动化程序,能够遍历互联网上的各个网页,并根据预设的规则和算法来解析和收集感兴趣的信息。这些信息可以包括网页的文本内容、图片、链接、视频等。 功能:爬虫可以自动化执行重复、繁琐的任务,如定时抓取和更新网站上的信息、自动化监测网站的性能和稳定性、自动化测试网站功能等,从而提高工作效率和质量。 2.爬取原理 选择起始网页:爬虫首先选择
python手写了个简易的豆瓣影评爬虫
使用python手写了个简易的豆瓣影评爬虫代码。 __author__ = 'wsx'import timeimport requestsfrom bs4 import BeautifulSoupimport osimport reimport uuiddef clean_windows_filename(string_file_name):invalid_chars = r'[\\/

python定时器爬取豆瓣音乐Top榜歌名
python定时器爬取豆瓣音乐Top榜歌名 作者:vpoet 日期:大约在夏季 注:这些小demo都是前段时间为了学python写的,现在贴出来纯粹是为了和大家分享一下 #coding=utf-8import urllib import urllib2 import re import time def SaveTop20Music(currtime):r

打卡学习Python爬虫第五天|使用Xpath爬取豆瓣电影评分
思路:使用Xpath爬取豆瓣即将上映的电影评分,首先获取要爬取页面的url,查看页面源代码是否有我们想要的数据,如果有,直接获取HTML文件后解析HTML内容就能提取出我们想要的数据。如果没有则需要用到浏览器抓包工具,二次才能爬取到。其次观察HTML代码的标签结构,通过层级关系找到含有我们想要的数据的标签,提取出数据。最后保存我们的数据。 1、获取url 这里我们可以看到,有的电影是

python : Requests请求库入门使用指南 + 简单爬取豆瓣影评
Requests 是一个用于发送 HTTP 请求的简单易用的 Python 库。它能够处理多种 HTTP 请求方法,如 GET、POST、PUT、DELETE 等,并简化了 HTTP 请求流程。对于想要进行网络爬虫或 API 调用的开发者来说,Requests 是一个非常有用的工具。在今天的博客中,我将介绍 Requests 的基本用法,并提供一个合理的爬虫实例。 一.安装 Requests

Scrapy实战-下载豆瓣图书封面
紧接着再识Scrapy-爬取豆瓣图书,我们打算把每一本图书的封面都爬下来,毕竟下载图片是一件很棒的事。可以凭借这招去搜集各种表情包呢,还可以省了在某榴辛辛苦苦一个一个打开网页的烦恼呢。 根据官方文档,下载图片其实pipeline.py的额外工作而已,大致分为以下几步 在Spider中,额外定义一个image_urls用来存放图片链接的 item;这个item会从spider中传递到pipelin

Scrapy实战-爬取豆瓣漫画
背景知识 (一)什么是Scrapy呢?Python上优秀的爬虫框架。什么是爬虫?可以看我的心得感悟,也可以自行谷歌百度。 (二)建议看下初识Scrapy的事前准备安装Scrapy。 (三)Selectors根据XPath和CSS表达式从网页中选择数据。XPath和CSS表达式是什么东西,我们不用太过于纠结,只需要知道可以使用它们在网页中选择数据。用法:利用chrome去复制所需数据的位置信息
Python中的爬虫实战:豆瓣图书爬虫
Python是当今最热门的编程语言之一,在不同的领域都得到了广泛的应用,如数据科学、人工智能、网络安全等。其中,python在网络爬虫领域表现出色,许多企业和个人利用python进行数据采集和分析。本篇文章将介绍如何使用python爬取豆瓣图书信息,帮助读者初步了解python网络爬虫的实现方法和技术。 首先,对于豆瓣图书信息爬虫,我们需要用到Python中的两个重要的库:urllib和beau

以豆瓣网为例,讲解restful api设计规范
什么是restful api 目前比较成熟的一套互联网应用程序的API设计理论 豆瓣电影api 应该尽量将API部署在专用域名之下 http://api.douban.com/v2/user/1000001?apikey=XXX应该将API的版本号放入URL http://api.douban.com/v2/user/1000001?apikey=XXX在RESTful架构中,每个网址
python爬虫入门——豆瓣电影排行榜top250
需要用到的库 1.requests 2.re(正则表达式库) 部分参数 请求头: 此处复制的火狐浏览器请求头 myheader = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0","Host": "movie.douban.com"}
python+Selenium 模拟登陆豆瓣6.0
新版豆瓣在登陆窗口内嵌了一个iframe,所以采用selenium模拟登陆的时候,不能直接定位到登陆的输入框。 关于iframe的具体介绍可以百度,简单的说就是在网页内嵌入另一个网页,采用右键查看源代码是没办法检索iframe里面的代码的。在python里实现模拟登陆,需要先定位到iframe框架,再跳转到框架内对表单元素进行定位。 **这里讲一下模拟登陆的思路:** 1.采用webd

AI网络爬虫:批量爬取豆瓣图书搜索结果
工作任务:爬取豆瓣图书搜索结果页面的全部图书信息 在ChatGPT中输入提示词: 你是一个Python编程专家,要完成一个爬虫Python脚本编写的任务,具体步骤如下: 用 fake-useragent库设置随机的请求头; 设置chromedriver的路径为:"D:\Program Files\chromedriver125\chromedriver.exe" 隐藏chrome

【爬虫实战项目一】Python爬取豆瓣电影榜单数据
目录 一、环境准备 二、编写代码 2.1 分页分析 2.2 编码 一、环境准备 安装requests和lxml pip install requestspip install lxml 二、编写代码 2.1 分页分析 编写代码前我们先看看榜单的url 我们假如要爬取五页的数据,那么五个url分别是: https://movie.douban.com/to
【实战项目二】Python爬取豆瓣影评
目录 一、环境准备 二、编写代码 一、环境准备 pip install beautifulsoup4pip intall lxmlpip install requests 我们需要爬取这些影评 二、编写代码 我们发现每个影评所在的div的class都相同,我们可以从这入手 from bs4 import BeautifulSoupimport req

Python爬取与可视化-豆瓣电影数据
引言 在数据科学的学习过程中,数据获取与数据可视化是两项重要的技能。本文将展示如何通过Python爬取豆瓣电影Top250的电影数据,并将这些数据存储到数据库中,随后进行数据分析和可视化展示。这个项目涵盖了从数据抓取、存储到数据可视化的整个过程,帮助大家理解数据科学项目的全流程。 环境配置与准备工作 在开始之前,我们需要确保安装了一些必要的库: urllib:用于发送HTTP请求
Python3网络爬虫教程10——ajax异步请求(爬取豆瓣电影数据 )
上接: Python3网络爬虫教程9——有道在线翻译项目(破解JS加密过程) https://blog.csdn.net/u011318077/article/details/86592160 7. ajax异步请求 异步请求 一定会有url,请求方法,可能有数据 一般使用json格式 豆瓣排行榜-剧情:https://movie.douban.com/typerank?type_na
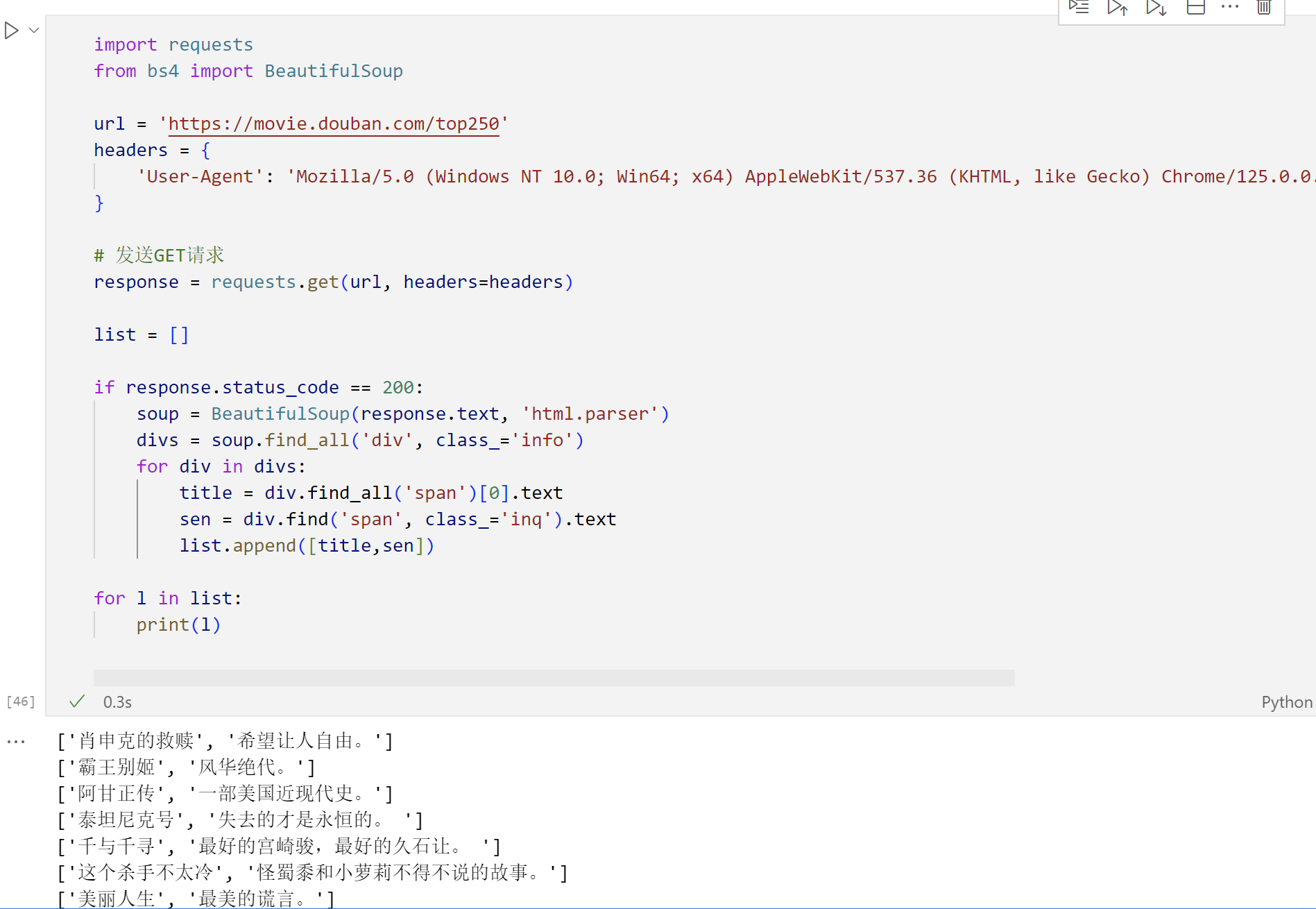
Python爬虫之简单学习BeautifulSoup库,学习获取的对象常用方法,实战豆瓣Top250
BeautifulSoup是一个非常流行的Python库,广泛应用于网络爬虫开发中,用于解析HTML和XML文档,以便于从中提取所需数据。它是进行网页内容抓取和数据挖掘的强大工具。 功能特性 易于使用: 提供简洁的API,使得即使是对网页结构不熟悉的开发者也能快速上手。文档解析: 支持多种解析器,包括Python标准库中的HTML解析器以及第三方的lxml解析器,后者速度更快且功能更强大。自动

豆瓣评分9.6!用81个项目带你从Python 3零基础到Python自动化
Python的名字来自超现实主义的英国喜剧团体,而不是来自蛇。Python程序员被亲切地称为Pythonistas。Monty Python和与蛇相关的引用常常出现在Python的指南和文档中。 今天给大家分享的这份手册将从下载安装到编程语法;从案例分析到代码实现;从在线编程到实时反馈;从知识总结到习题解答,一步步的带你深入Python! 限于文章篇幅原因,只能以截图的形式展示出来,有需要的小

带你系统学习平滑样条、局部回归、广义可加性模型-豆瓣9.6分统计学神作ISL之第七章读书笔记(下)
目录 1.原文内容概要2.算法知识总结2.1 平滑样条(Smoothing Splines)2.1.1 平滑样条简介(An Overview of Smoothing Splines )2.1.2 选择调优参数λ(Choosing the Smoothing Parameter λ) 2.2 局部回归(Local Regression)2.3 广义可加性模型(Generalized Addi
豆瓣客户端(三)发送图文广播
这只是一个简单的Demo,功能是调用豆瓣的接口发送图文广播。功能并不齐全,只是为网络编程练练手而已。 首先强调,这里没有用到第三方类库,也没有使用豆瓣的iOS SDK,都是直接用iOS给出的类和接口写的,只有代码是自己的,才真正有一种踏实的感觉。 当然第三方类库也非常好用,而且我也非常尊敬开发者开源共享的精神。 该广播接口的主要内容如下: URL shuo/v2/status