本文主要是介绍Scrapy实战-爬取豆瓣漫画,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
背景知识
(一)什么是Scrapy呢?Python上优秀的爬虫框架。什么是爬虫?可以看我的心得感悟,也可以自行谷歌百度。
(二)建议看下初识Scrapy的事前准备安装Scrapy。
(三)Selectors根据XPath和CSS表达式从网页中选择数据。XPath和CSS表达式是什么东西,我们不用太过于纠结,只需要知道可以使用它们在网页中选择数据。用法:利用chrome去复制所需数据的位置信息。当然进阶的话可以看这里
基本用法与说明:
- response.selector.xpath('//title/text()')##用xpath选取了title的文字内容
- response.selector.css('title::text') ##用css选取了title的文字内容
由于selector.xpath和selector.css使用比较普遍,所以专门定义了xpath和css,所以上面也可以写成: - response.xpath('//title/text()')
- response.css('title::text')
由于<code>.xpath</code>和<code>.css</code>返回的都是<class 'scrapy.selector.unified.SelectorList'>,因此可以这样写<code>response.css('img').xpath('@src').extract()</code> - 提取全部内容:
.extract(),获得是一个列表 - 提取第一个:
.extract_first(),获得是一个字符串 - 选取链接:
.response.css('base::attr(href)')或.response.xpath('//base/@href')
正式开始
1. 新建工程 scrapy startproject tutorial
2. 创建爬虫 scrapy genspider -t basic douban douban.com
上面两步会创建如下的目录结构:
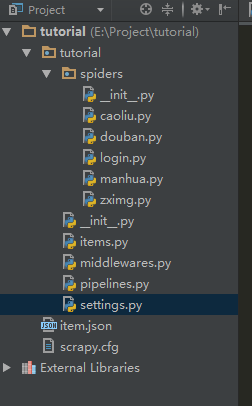
简单说下每一个文件的作用,虽然在初识Scrapy已经说过了。
- spiders文件夹存放你的爬虫,
- items.py用于定义存放网页数据的item。
- middlewares.py是后加的,目前不需要
- pipelines.py 用于处理从spiders返回的item,比如说清洗、存储。
- settings.py是全局设定,比如说接下来提到的DEFAULT_REQUEST_HEADERA和USER_AGENT都在这里。
3. 修改settings.py
因为Scrapy非常诚实,爬取网页的时候会表明自己是一只爬虫,但是豆瓣不给这些表明身份的爬虫活路。所以我们只能换个身份。
第一步:chrome用快捷键F12打开开发者工具,选择Network一栏,可能需要F5刷新页面:
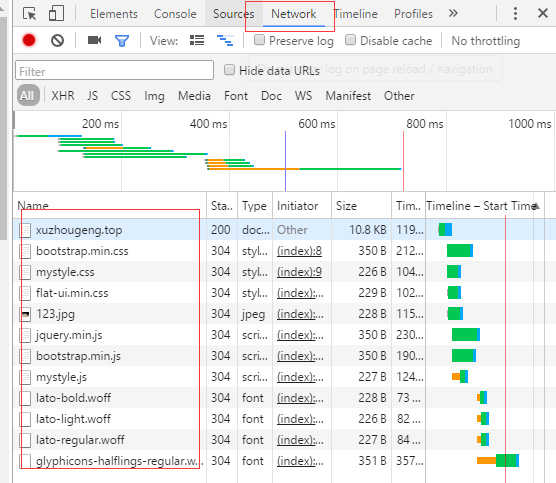
第二步:在上图红框部分随机选取一个,会出现下图:
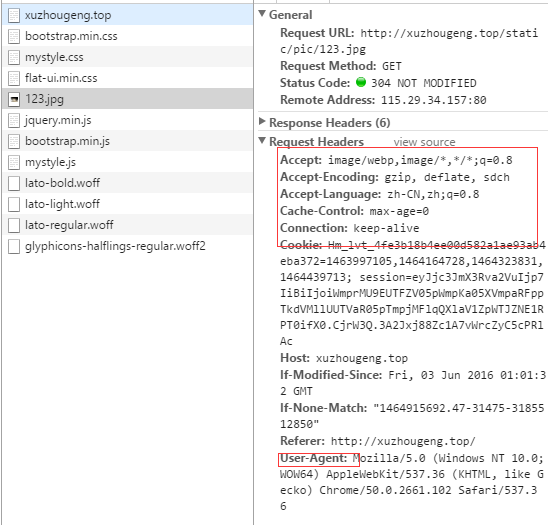
我们主要需要的是里面红框的Request Headers的信息。
第三步:在settings.py中修改DEFAULT_REQUEST_HEADERA和USER_AGENT。

里面的USER_AGENT填写浏览器图中的User-Agent对应信息,DEFAULT_REQUEST_HEADERA里的信息根据字典的写法,从浏览器信息图中依次对应对应填上去。
PS:
顺便启用DOWNLOAD_DELAY=3减慢爬取速度,不要给别人的服务器增加太多压力。
此外启用
ITEM_PIPELINES = { 'tutorial.pipelines.DoubanPipeline': 300,}用于处理数据
4. 用爬虫的视角看网页,
在命令行中输入scrapy shell https://movie.douban.com/chart 这时候会进入scrapy版的ipython,输入view(response)就可以查看网页。
5. 定义要爬取的内容
在items.py中作如下修改
import scrapy
class DoubanItem(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()title = scrapy.Field()link = scrapy.Field()info = scrapy.Field()desc = scrapy.Field()
6. 单页逻辑
爬取多个网页前,我们首先得要成功提取一个网页的信息。在spiders/douban.py做如下修改
# -- coding: utf-8 --
import scrapy
from scrapy.http import Request
from ..items import DoubanItem
class DoubanSpider(scrapy.Spider):name = "douban"allowed_domains = ["douban.com"]start_urls = ('https://book.douban.com/tag/%E6%BC%AB%E7%94%BB?start=0&type=T',)def parse(self, response):item = DoubanItem()for sel in response.css('#subject_list > ul > li > div.info'):item['title']= sel.css('h2 > a::text').extract_first()item['link'] = sel.css('h2 > a::attr(href)').extract_first()item['info'] = sel.css('div.pub::text').extract_first()item['desc'] = sel.css('p::text').extract_first()yield item
大致的爬虫就完成了。用scrapy crawl douban开始工作。由于scrap构建在python2.7上,所以对中文支持不太好,在命令行中会以unicode编码的方式显示,所以在shell上看到一堆不认识的\xxx也不要太担心。
7.数据储存
为了方便之后调用数据,我们需要用pipelines.py将爬取的数据存储在固定的文件中。可以用json等格式储存,也可以存放在数据库中。网页爬取数据往往不太规范,建议使用mongodb(NoSQL)。
import json
import codecs
Import pymongo #python中用来操作mongodb的库
##存储为json格式
class DoubanPipeline(object):def __init__(self):self.file = codecs.open('douban_movie.json','wb',encoding='utf-8')def process_item(self, item, spider):line = json.dumps(dict(item)) + '\n'self.file.write(line.decode("unicode_escape"))return itemclass MongoPipeline(object):collection_name = 'douban_cartoon' # mongo的collection相当于sql的tabledef __init__(self, mongo_uri,mongo_db):self.mongo_uri = mongo_uriself.mongo_db = mongo_db## 配置mongo@classmethoddef from_crawler(cls, crawler):return cls(mongo_uri=crawler.settings.get('MONGO_URI'), #从settings中mongo的urimongo_db=crawler.settings.get('MONGO_DATABASE','douban') #从settings中获取数据库,默认为douban)# 在spider工作开始前连接mongodbdef open_spider(self, spider):self.client = pymongo.MongoClient(self.mongo_uri)self.db = self.client[self.mongo_db]## 在spider工作结束后关闭连接def close_spider(self, spider):self.client.close()## 在mongodb中插入数据def process_item(self, item, spider):# for i in item:self.db[self.collection_name].insert(dict(item))return item
运行后就可以在项目所在目录找到douban_movie.json,mongodb的话需要自己去查询了。
多页逻辑(一)
我们需要在这一页获取下一个的链接,然后重新调用parse函数爬取这个链接。
def parse(self, response):.....## 获取下一个的链接href = response.xpath('//*[@id="subject_list"]/div[2]/span[4]/a')url = u'https://book.douban.com'+ href.css('a::attr(href)').extract_first()yield Request(url, callback=self.parse)
多页逻辑(二)
我们还可以通过Scrapy提供的CrawlSpider完成多页爬取。CrawlSpider比Spider多了一步即设置Rule,具体可以看我的[Scrapy基础之详解Spider]的CrawlSpider。
第一步shell试错
为了确保LinkExtractor能提取到正确的链接,我们需要在shell中进行试验。
scrapy shell https://book.douban.com/tag/漫画from scrapy.linkextractors import LinkExtractor ##导入LinkExtractoritem=LinkExtractor(allow='/tag/漫画',restrict_xpaths=('//*[@id="subject_list"]/div[2]/span/a')).extract_links(response) ##需要反复修改
第二步修改爬虫
修改后的爬虫如下:
# -- coding: utf-8 --
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from tutorial.items import DoubanItem
class ManhuaSpider(CrawlSpider):name = 'manhua'allowed_domains = ['book.douban.com']start_urls = ['https://book.douban.com/tag/漫画']rules = (Rule(LinkExtractor(allow=r'/tag/漫画',restrict_xpaths=('//*[@id="subject_list"]/div[2]/span/a')),callback='parse_item',follow=True),)def parse_item(self, response):item = DoubanItem()for sel in response.css('#subject_list > ul > li > div.info'):item['title']= sel.css('h2 > a::text').extract_first()item['link'] = sel.css('h2 > a::attr(href)').extract_first()item['info'] = sel.css('div.pub::text').extract_first()item['desc'] = sel.css('p::text').extract_first()yield item
运行结果和多页逻辑(一)的一致。
进一步,你可以看再识Scrapy-下载豆瓣图书封面,在这个的基础上增加图片下载功能。
如果怕被ban,可以看再识Scrapy-防ban策略
本文参考了Andrew_liu的Python爬虫(六)--Scrapy框架学习,
scrapy研究探索(二)——爬w3school.com.cn,以及最重要的官方文档。
写在最后:
网络上有那么多的Scrapy的教程,为啥我还要写一个呢?因为我觉得真正学会用自己语言去表达一门技术的时候,才算入门了。
还有写出来的东西才能让别人发现自己的不足,希望各位大大批评指正。
我的源代码托管在GitHub上,有需要的话可以去看
这篇关于Scrapy实战-爬取豆瓣漫画的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




