本文主要是介绍Python爬虫之简单学习BeautifulSoup库,学习获取的对象常用方法,实战豆瓣Top250,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
BeautifulSoup是一个非常流行的Python库,广泛应用于网络爬虫开发中,用于解析HTML和XML文档,以便于从中提取所需数据。它是进行网页内容抓取和数据挖掘的强大工具。
功能特性
- 易于使用: 提供简洁的API,使得即使是对网页结构不熟悉的开发者也能快速上手。
- 文档解析: 支持多种解析器,包括Python标准库中的HTML解析器以及第三方的lxml解析器,后者速度更快且功能更强大。
- 自动编码识别: 自动将输入文档转换为Unicode编码,输出文档转换为UTF-8编码,简化了编码处理的复杂性。
- 导航与搜索: 提供了丰富的选择器和方法,如 .find(), .find_all(), .select() 等,便于按标签名、属性、类名等查找元素。
- 数据提取: 可以轻松地提取和修改HTML或XML文档中的数据,支持遍历和搜索DOM树,提取文本、属性等信息。
- 灵活的输出格式: 可以将解析后的数据输出为Python对象、字符串或者保存为文件。
目录
安装BeautifulSoup
基本使用
BeautifulSoup获取对象
选择器
1、CSS选择器(select()方法):
2、Tag名:
3、属性选择:
方法
.find_all()
.find()
示例
使用BeautifulSoup爬取豆瓣Top250实例
安装BeautifulSoup
在命令窗口安装
pip install基本使用
我们使用requests库发送请求获取html,获得的是html字符串,在爬虫中,只有正则表达式(re)才可以直接对html字符串进行解析,而对于html字符串我们无法使用xpath语法和bs4语法进行直接提取,需要通过lxml或者bs4对html字符串进行解析,解析为html页面才能进行数据提取。
在xpath中我们使用lxml进行解析,但是在bs4中,我们有很多的解析器对网页进行解析。
这里我们只说一种最常用最简单的解析器"html.parser"
简单来说BeautifulSoup是一个从html字符串提取数据的工具,使用BeautifulSoup分为三步:
第一步 导入BeautifulSoup类,抓取网页同时也导入requests库
from bs4 import BeautifulSoup
import requests第二步 传递初始化参数(HTML代码,HTML解析器),并初始化
这里解析器使用'html.parser',这是python自带的解析器,更方便使用
# html_code:html代码 html.parser:解析器,python自带的解析器
soup = BeautifulSoup(html_code, 'html.parser')第三步 获取实例对象,操作对象获取数据
BeautifulSoup获取对象可以使用选择器和方法。
BeautifulSoup获取对象
选择器
1、CSS选择器(select()方法):
支持ID选择器、类选择器、属性选择器、伪类等
复杂选择
- 组合选择器:可以使用逗号 , 分隔多个选择器来选择多个不同类型的元素。
- 后代选择器:使用空格表示,如 .story a 选取所有.story类内的<a>标签。
- 子选择器:使用 > 表示直接子元素,如 body > p 选取<body>直接下的所有段落。
- 属性选择器:如 [href*=example] 选取所有href属性包含"example"的元素。
- 伪类选择器:如 a:hover、:first-child 等,虽然不是所有CSS伪类在BeautifulSoup中都可用,但一些基本的如:first-child, :last-child等有时也能派上用场。
2、Tag名:
- 直接使用tag名作为属性,如 soup.div 返回第一个<div>标签。
- 支持通过列表索引来定位特定的标签,如 soup.divs[0]。
3、属性选择:
使用[attribute=value]语法,例如 soup.find_all(attrs={'class': 'active'}) 查找所有class为"active"的元素。
方法
.find_all()
查找文档中所有匹配指定条件的tag,返回一个列表。
参数可以精确指定tag名字、属性、文本内容等。
.find()
类似于.find_all(),但只返回第一个匹配的元素。
示例
1、获取所有div标签
soup.find_all('div')
2、获取拥有指定属性的标签(id='even'的div标签)
soup.find_all('div', id='even')如果有多个属性的标签,可以使用字典模式
soup.find_all('div', attrs={"id":"even", "class":"cc"})
soup.find_all('div', id='even',class_='c')使用字典形式,还可以添加样式属性,更加灵活
3、获取标签的属性值
方法1:通过下标方式提取
alist = soup.find_all('a')
# 我想获取a标签的href值
for a in alist:href = a['href']print(href)方法2:利用attrs参数提取
for a in alist:href = a.attrs['href']print(href)使用BeautifulSoup爬取豆瓣Top250实例
网址:豆瓣电影 Top 250
导入库,使用requests向网站发起请求,获取页面响应对象
.status_code状态码为200则请求成功,可以继续下一步
import requests
from bs4 import BeautifulSoupurl = 'https://movie.douban.com/top250'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0'
}# 发送GET请求
response = requests.get(url, headers=headers)
print(response.status_code)打开浏览器开发者工具,找到User-Agent复制

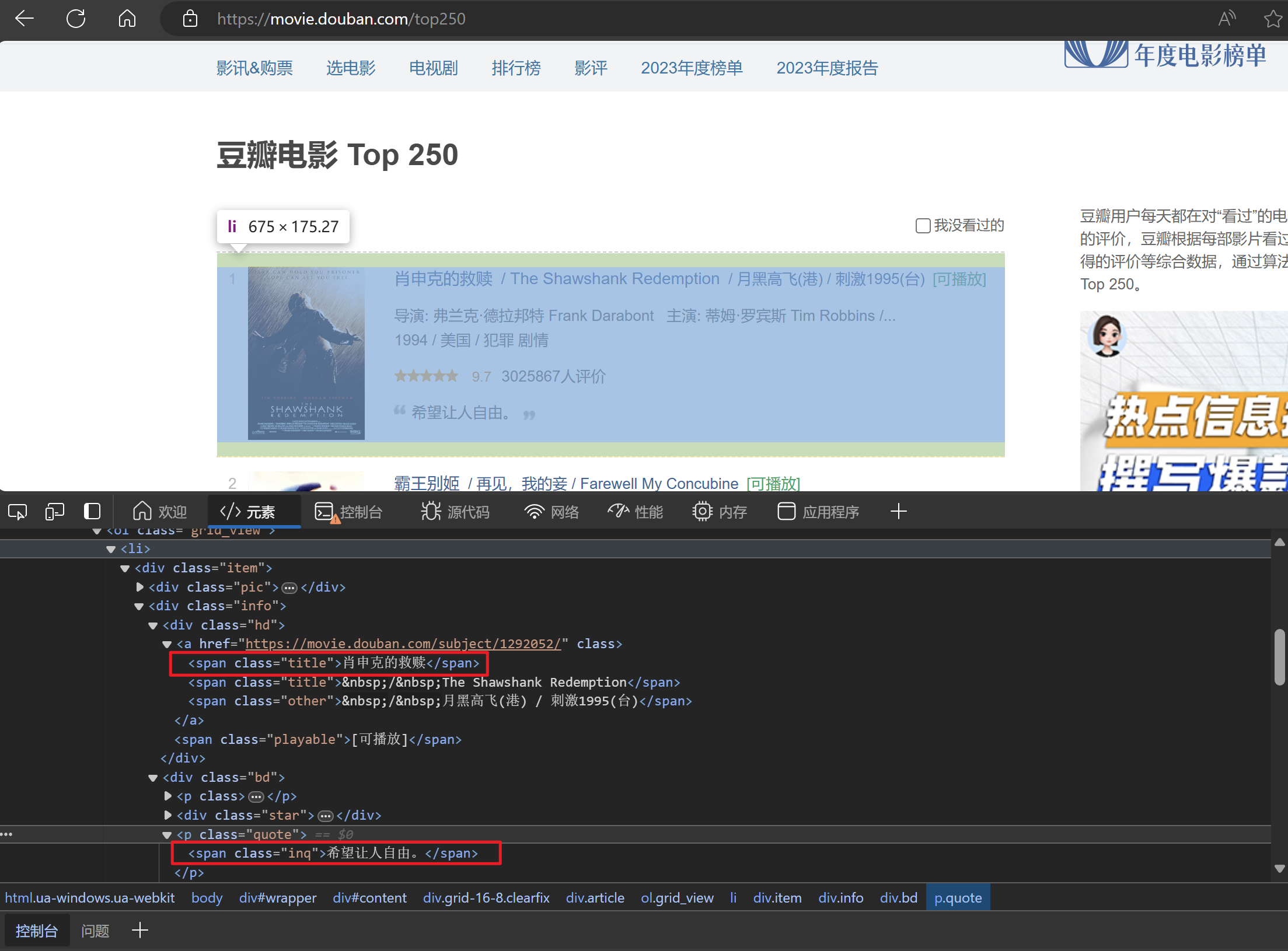
这次实验我们爬取电影名称和短语,我们通过观察知道每个电影的信息都包含在一个div中,这个div的class选择器为"info",而我们需要爬取的数据在这个div里面。
import requests
from bs4 import BeautifulSoupurl = 'https://movie.douban.com/top250'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0'
}# 发送GET请求
response = requests.get(url, headers=headers)if response.status_code == 200:soup = BeautifulSoup(response.text, 'html.parser')divs = soup.find_all('div', class_='info')获取到每个电影外层的div元素后,再嵌套循环,将需要抓取的标签使用.find()和.find_all()方法获取到。
import requests
from bs4 import BeautifulSoupurl = 'https://movie.douban.com/top250'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36 Edg/125.0.0.0'
}# 发送GET请求
response = requests.get(url, headers=headers)list = []if response.status_code == 200:# 解析html代码soup = BeautifulSoup(response.text, 'html.parser')# 查找此页面的所有div标签,选择器为'info'divs = soup.find_all('div', class_='info')# 遍历获取到的元素,获取电影名称和短语for div in divs:title = div.find_all('span')[0].textsen = div.find('span', class_='inq').textlist.append([title,sen])for l in list:print(l)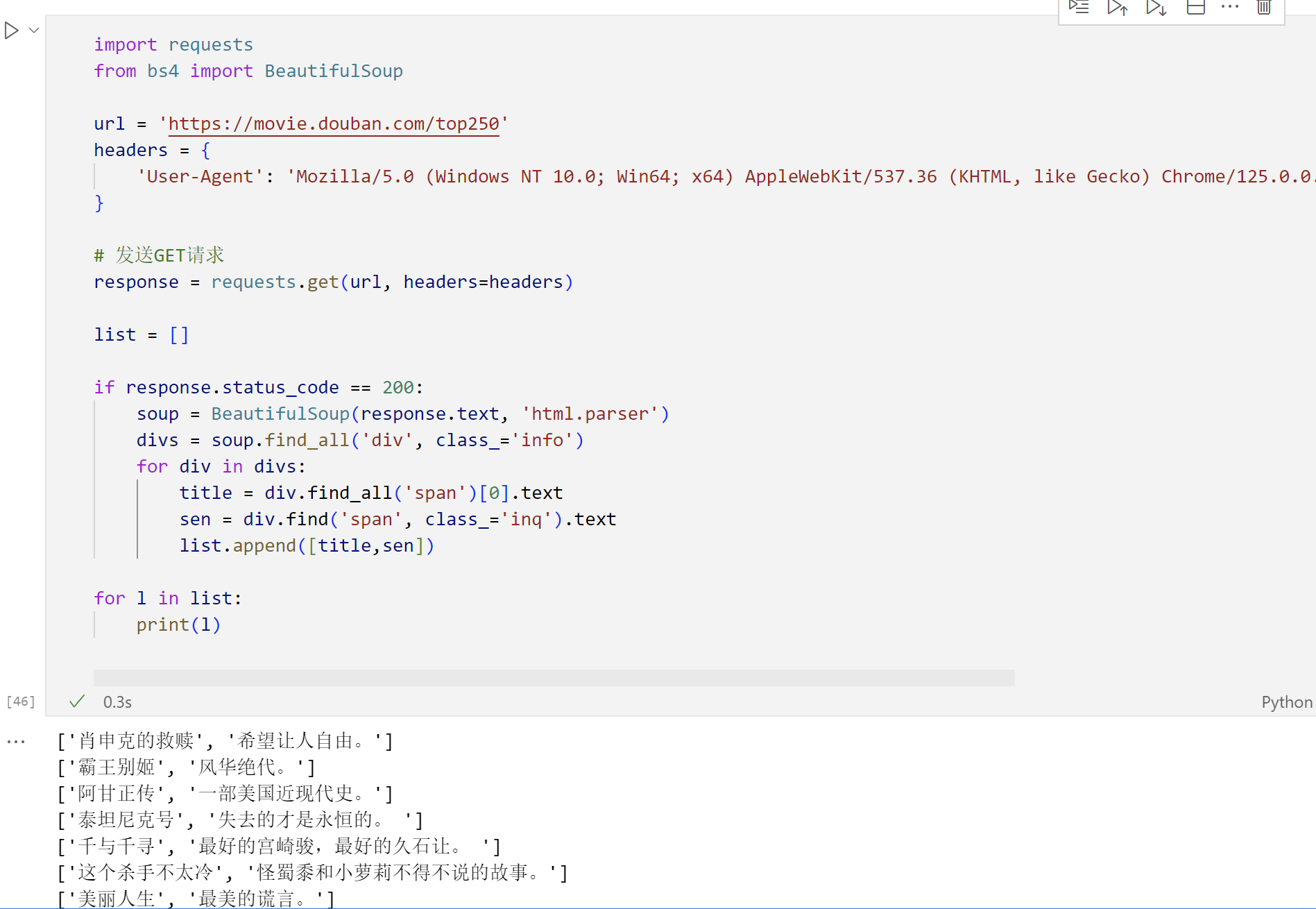
这篇关于Python爬虫之简单学习BeautifulSoup库,学习获取的对象常用方法,实战豆瓣Top250的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




