top250专题

爬虫二:获取豆瓣电影Top250(Requests+XPath+CSV)
描述: 在上一篇获取豆瓣图书Top250的基础上,获取豆瓣电影Top250的数据并将结果写入CSV文件中。 代码: # -*- coding: UTF-8 -*-import requestsfrom lxml import etreeimport timeimport csv# 从网页上获取电影数据moviedata = []count = 0for i in range(1

爬虫一:获取豆瓣图书Top250(Requests+XPath)
目的: 获取豆瓣图书Top250的所有书目信息。 豆瓣网址:https://book.douban.com/top250 代码: import requestsfrom lxml import etreeimport timefor i in range(10):url = 'https://book.douban.com/top250?start=' + str(25*i)data
python爬虫入门——豆瓣电影排行榜top250
需要用到的库 1.requests 2.re(正则表达式库) 部分参数 请求头: 此处复制的火狐浏览器请求头 myheader = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:67.0) Gecko/20100101 Firefox/67.0","Host": "movie.douban.com"}
Python爬虫之简单学习BeautifulSoup库,学习获取的对象常用方法,实战豆瓣Top250
BeautifulSoup是一个非常流行的Python库,广泛应用于网络爬虫开发中,用于解析HTML和XML文档,以便于从中提取所需数据。它是进行网页内容抓取和数据挖掘的强大工具。 功能特性 易于使用: 提供简洁的API,使得即使是对网页结构不熟悉的开发者也能快速上手。文档解析: 支持多种解析器,包括Python标准库中的HTML解析器以及第三方的lxml解析器,后者速度更快且功能更强大。自动

2024年世界排名TOP250医院榜单发布|医学访学/博后/联培博士参考
作为医学类的访问学者、博士后及联合培养博士们,都希望到世界知名医院进行临床研修交流及科研学习。2024年世界最佳医院排行榜的发布为申请者提供了可选目标,现知识人网小编整理刊出。 近日,美国《新闻周刊》(Newsweek)重磅发布了2024年度全球最佳医院排名榜单。 名单包括30个国家2400家医院的数据。智利和马来西亚首次被列入排名,其中还包括美国、西欧和斯堪的纳维亚的大部分地区、10
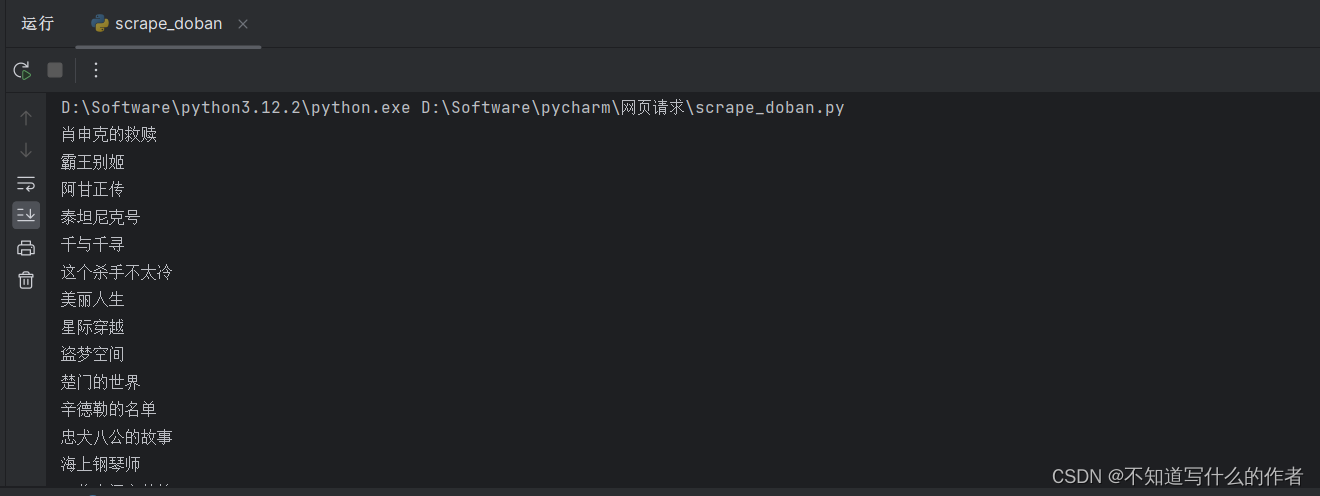
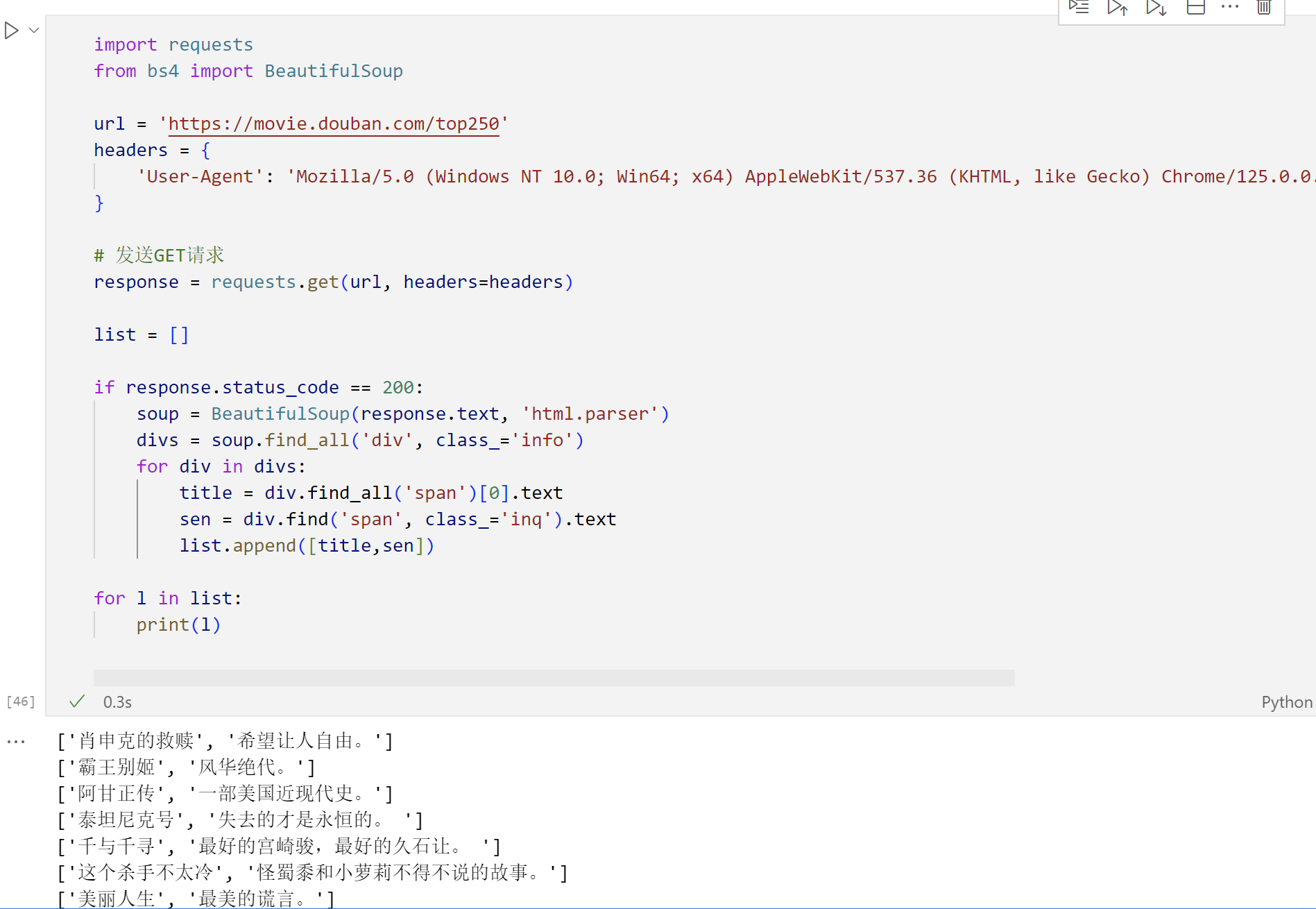
python爬虫获取豆瓣前top250的标题(简单)
今天是简略的一篇,简单小实验 import requestsfrom bs4 import BeautifulSoup# 模拟浏览器的构成(请求头)headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.

【Python】豆瓣电影TOP250数据规律分析(Pearson相关系数、折线图、条形图、直方图)
1、数据集预览 部分数据说明: 豆瓣排名num 评分rating_num 评分人数comment_num 电影时长movie_duration 2、查看电影数据集基本数据信息 import numpy as npimport pandas as pdimport matplotlib.pyplot as pltdata = pd.read_csv('电影排名.csv') #读取数据#

一个爬虫Demo(经典豆瓣TOP250)
获取网页源码,拿想要的内容就完事了。 import xlwtimport requestsfrom bs4 import BeautifulSoupdef get_style():style = xlwt.XFStyle()alignment = xlwt.Alignment()alignment.horz = 0x02alignment.vert = 0x01style.alignme
爬虫笔记【豆瓣图书TOP250和猫眼电影TOP100】
参考视频:Python网络爬虫与信息提取北京理工大学【嵩天】 requsts库 BeautifulSoup库 正则表达式 图片 周二珂女神的头像 import requestsurl = 'http://tvax2.sinaimg.cn/crop.12.0.1218.1218.180/71e28d79ly8fn19fotj2qj20yi0xu0w9.jpg'r = requests.ge

通过爬取豆瓣评分Top250电影数据浅谈对Python爬虫的认识
今天在酱酱的带领下接触到了Python爬虫,有点兴趣,探索一下。 Python是如何与Excel表格搭讪哒? python有专门的库为Excel文件的操作提供支持,这些库包括xlrd,xlwt,xlutils,openpyxl,xlsxwriter等它们可以帮助我们自动化办公。 首先是一个简单的Python与excel交互的代码。 import openpyxl #导入我们要用到的库imp
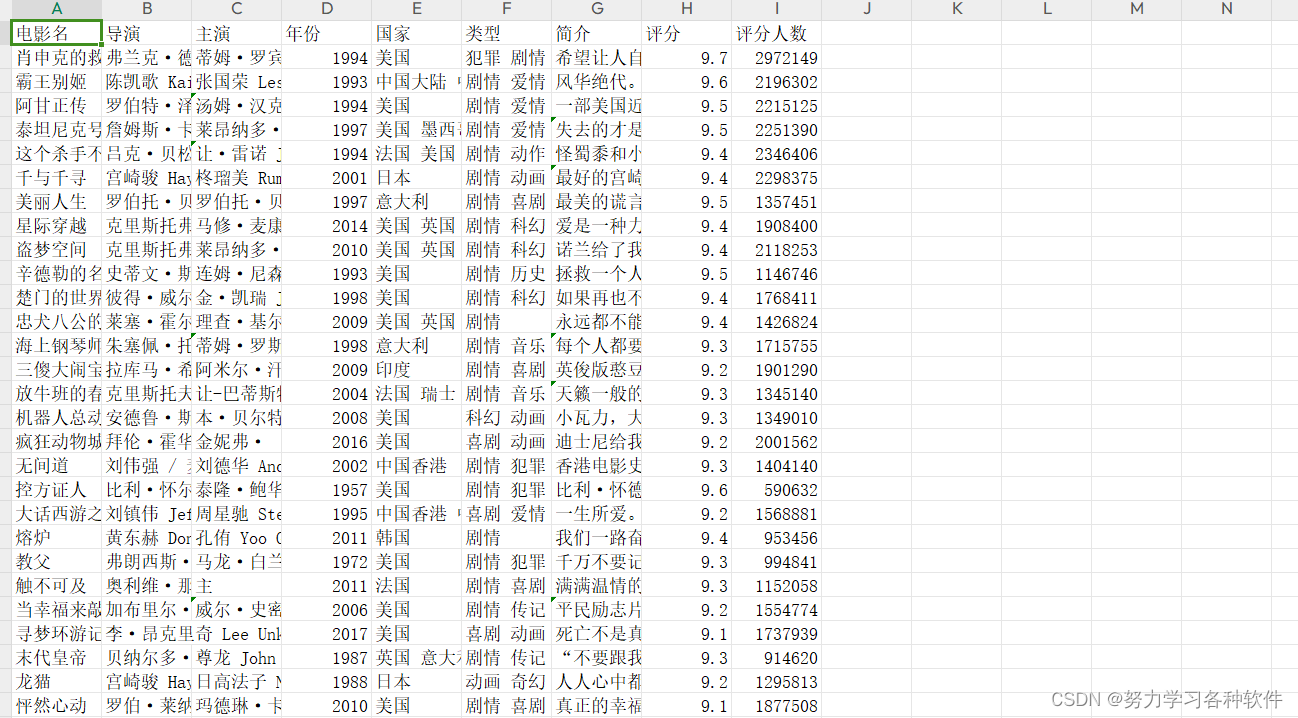
爬虫入门,爬取豆瓣top250电影信息
import requestsimport csvimport parselimport timef = open('豆瓣top250.csv',mode='a',encoding='utf-8',newline='')csv_writer = csv.writer(f)csv_writer.writerow(['电影名','导演','主演','年份','国家','类型','简介','
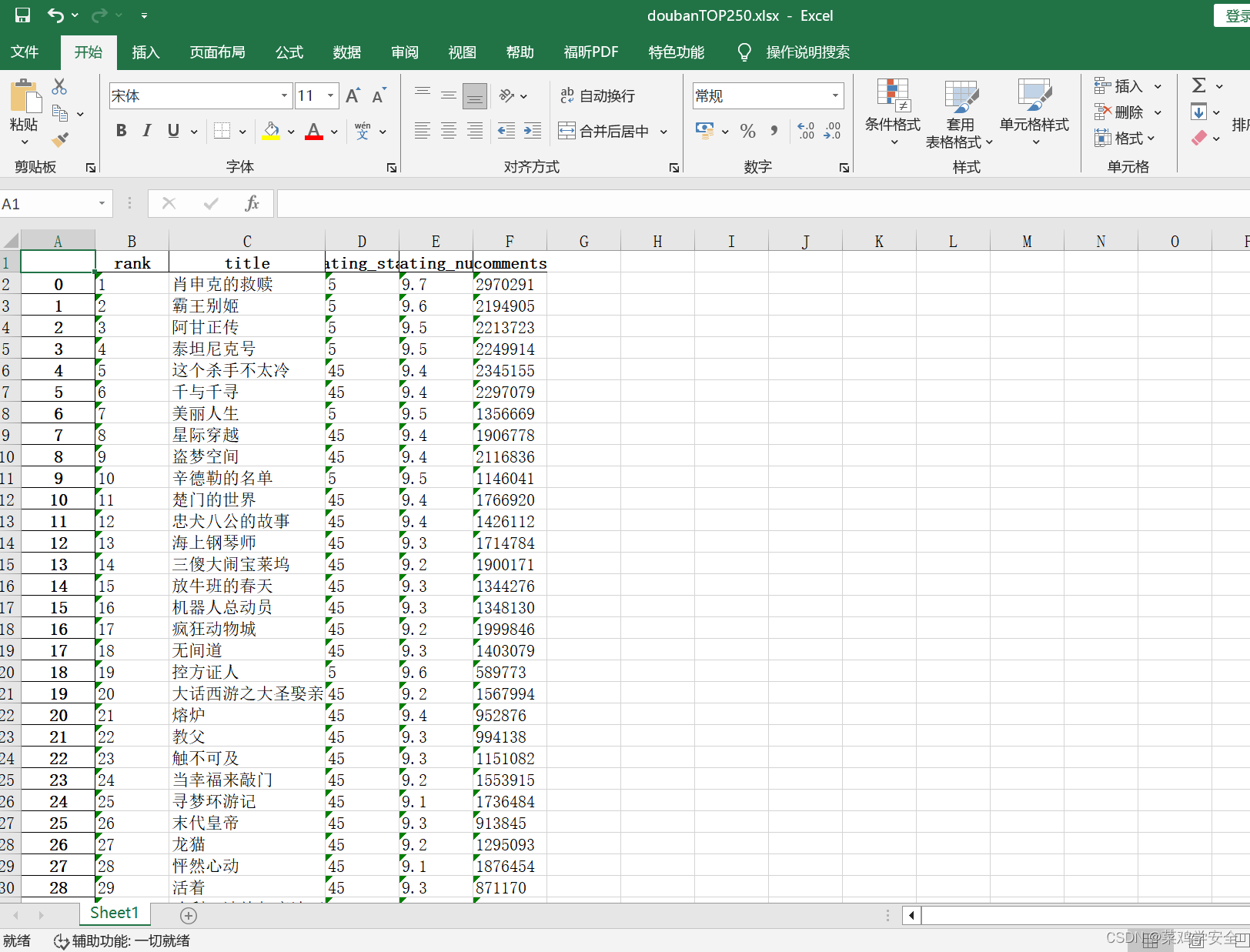
python爬虫小练习——爬取豆瓣电影top250
爬取豆瓣电影top250 需求分析 将爬取的数据导入到表格中,方便人为查看。 实现方法 三大功能 1,下载所有网页内容。 2,处理网页中的内容提取自己想要的数据 3,导入到表格中 分析网站结构需要提取的内容 代码 import requestsfrom bs4 import BeautifulSoupimport pprintimport jsonimport panda
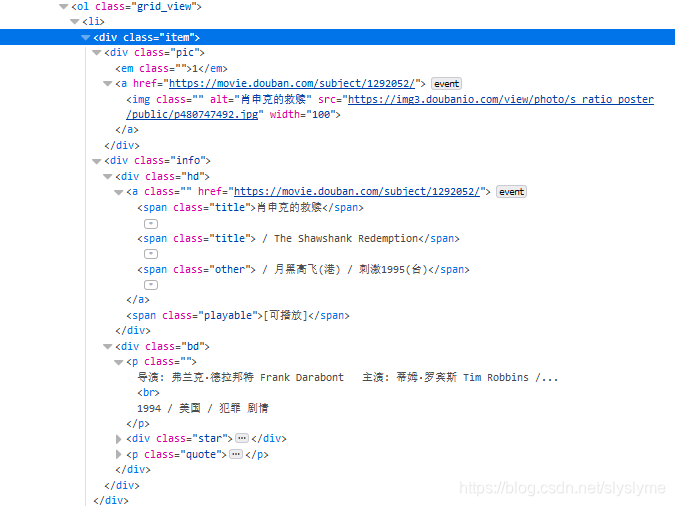
Python爬虫学习--3--爬取豆瓣Top250电影
爬取链接 这个网页中每页有25条信息,共有10页 首先我们要做的获取每一页的连接,由第一页 https://movie.douban.com/top250 //第一页 https://movie.douban.com/top250?start=0&filter= //第一页 https://movie.dou
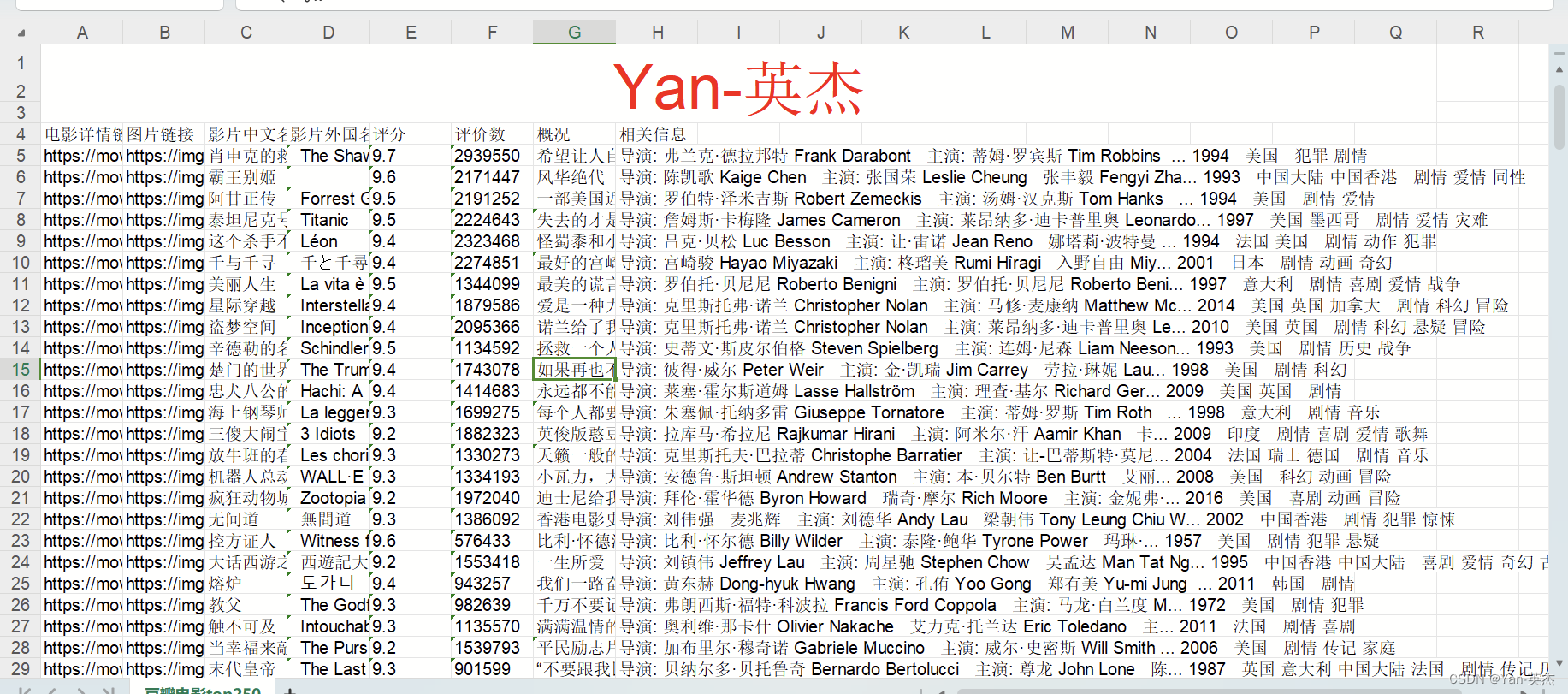
【python】爬取豆瓣电影排行榜Top250存储到Excel文件中【附源码】
英杰社区https://bbs.csdn.net/topics/617804998 一、背景 近年来,Python在数据爬取和处理方面的应用越来越广泛。本文将介绍一个基于Python的爬虫程 序,用于抓取豆瓣电影Top250的相关信息,并将其保存为Excel文件。 程序包含以下几个部分: 导入模块:程序导入了 Beautiful
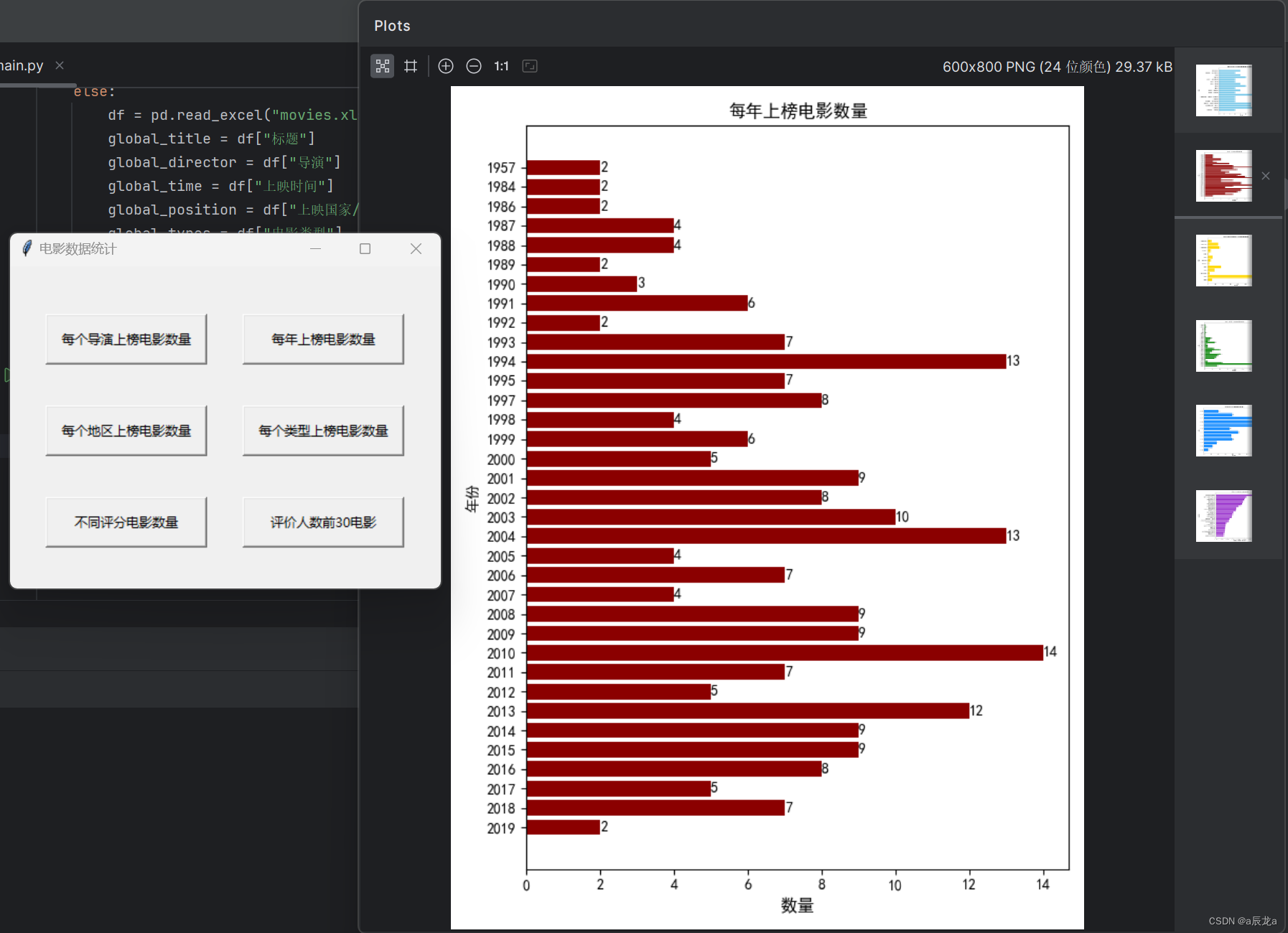
【Python期末】动态爬取电影Top250数据可视化处理(有GUI界面/无数据库)
诚接计算机专业编程作业(C语言、C++、Python、Java、HTML、JavaScript、Vue等),10/15R左右,如有需要请私信我,或者加我的企鹅号:1404293476 本文资源:https://download.csdn.net/download/weixin_47040861/88713693 目录 1.题目要求 2.实现功能 3.视频演示 1.题目要求 动态爬
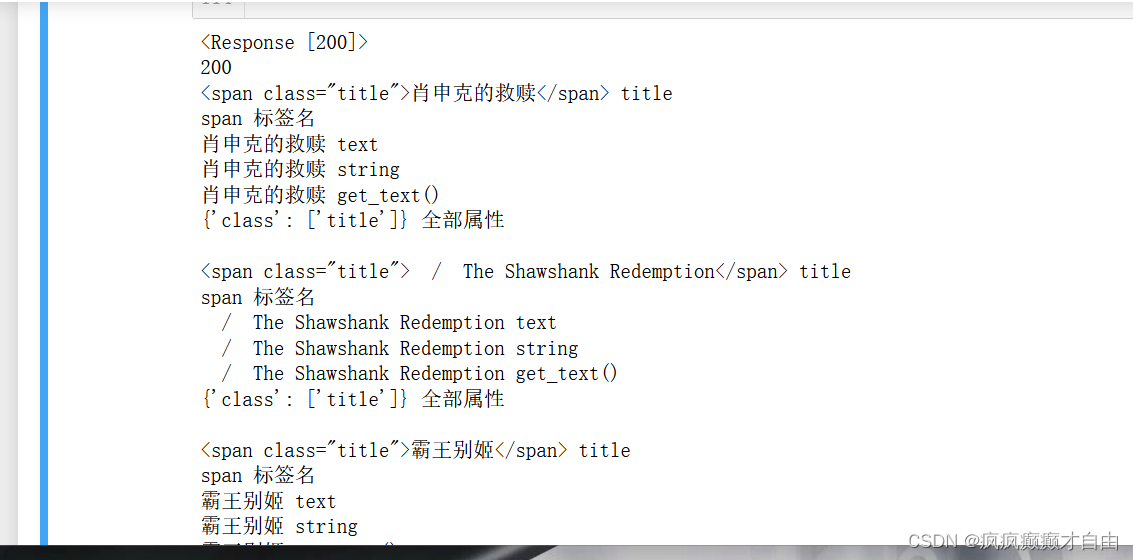
爬取豆瓣电影top250的电影名称(完整代码与解释)
在爬取豆瓣电影top250的电影名称之前,需要在安装两个第三方库requests和bs4,方法是在终端输入: pip install requestspip install bs4 截几张关键性图片: 豆瓣top250电影网页 运行结果 测试html文件标签的各个方法的作用: # import requests# response = requests.g

【Python 爬虫案例】爬取豆瓣读书Top250书籍信息,并保存到表格
获取数据请求 网页地址:豆瓣读书 Top 250 (douban.com) 进入网页——打开浏览器开发者模式——刷新网页——过滤数据 复制curl格式请求 使用在线工具转换请求 链接:curl命令转代码 - 在线工具 (tool.lu) 至此req中的请求内容已获取完成,下面是

Python爬虫——豆瓣电影Top250
#爬取 豆瓣电影Top250#250个电影 ,分为10个页显示,1页有25个电影import urllib.requestfrom bs4 import BeautifulSoupurl = "http://movie.douban.com/top250"headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident

开学了,爬一下某瓣电影Top250,挑几部电影康康~
随便说几句 打游戏和学习之余,最喜欢看电影啦~ 开学了,无聊的时候挑一部高分电影欣赏欣赏 而D瓣电影: 号称提供最新的电影介绍及评论包括上映影片的影讯。 来这里找 高分的电影再好不过。 '''博文说明:编写时间: 2021-03-01爬取入口url: https://movie.douban.com/top250用到的库:request,fake-useragent,BeautifulS

爬虫入门--爬取电影TOP250-附源码解析
爬取电影TOP250 1 知识小课堂1.1 什么是爬虫1.2 爬虫能做什么 2 代码解析2.1 运行环境2.2 过程解析2.2.1 第一步:引入两个模块2.2.2 找到网址2.2.3 拉去页面全内容 2.2.42.3 完整代码 1 知识小课堂 1.1 什么是爬虫 爬虫,也叫网络蜘蛛,如果把互联网比喻成一个蜘蛛网,那么蜘蛛就是在网上爬来爬去的蜘蛛。网络爬虫按照系统结构和实现
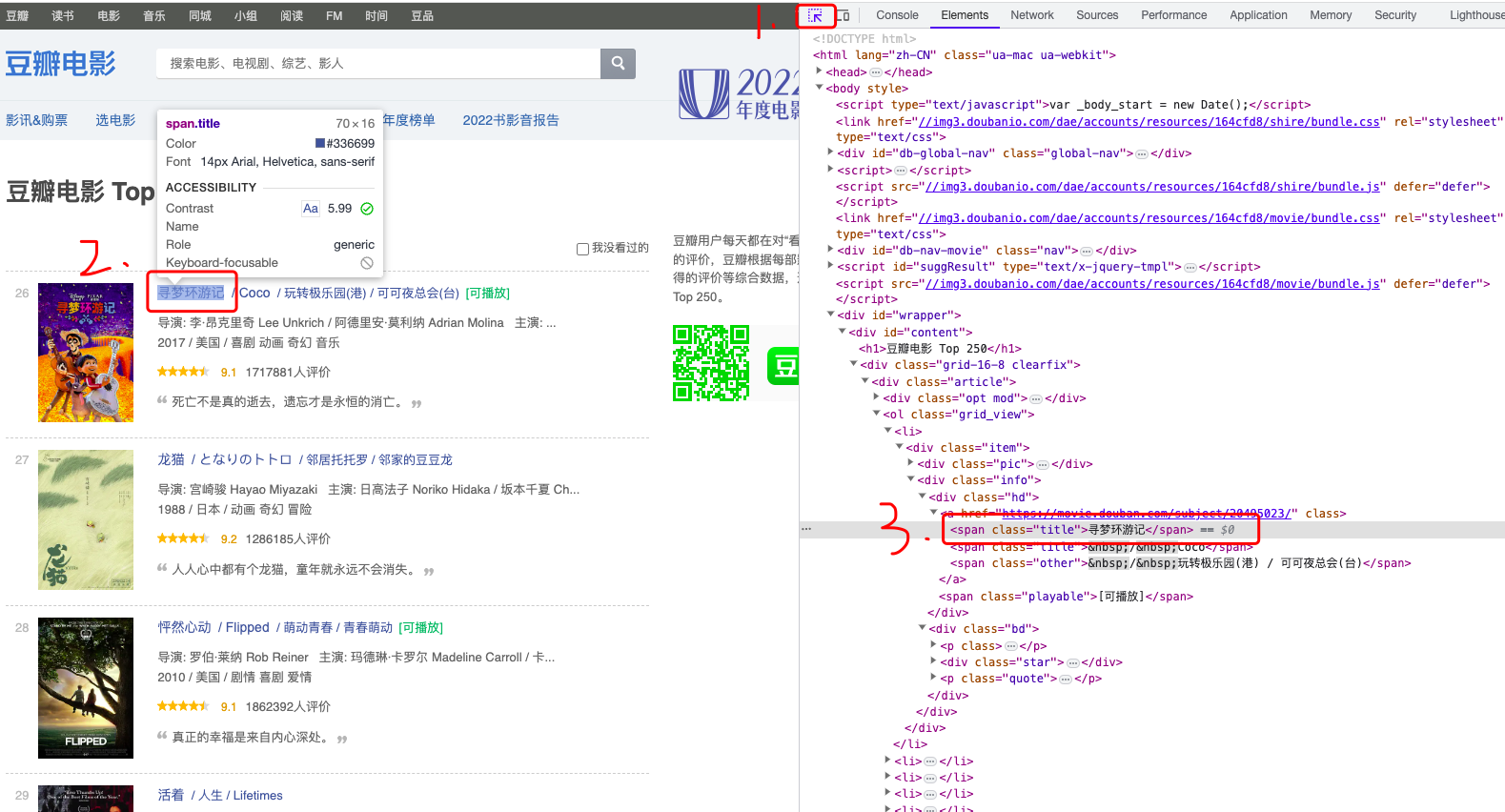
【爬虫实战】最新python豆瓣热榜Top250
一.最终效果 豆瓣是大多数新手练习爬虫的 二.数据定位过程 对于一个目标网站,该如何快速判定页面上的数据来源?首先你需要简单web调试能力,对大多数开发者来说都chrome浏览器应该是不二选择,当然我选中的也是。F12打开调试面板,如下图: 如果数据是来自服务端API接口,当你按上图操作翻页时,右侧空白面板处会出现请求记录,此时页面数据就是通过接口返回的;如果像上面这种,翻页操作

使用Jsoup包抓取豆瓣Top250电影信息
Java制作爬虫程序主要用到的网页解析工具Jsoup,而在Python使用的是漂亮汤,Jsoup能向JS和JQuery一样获取网页文件的模型(dom),是解析网页文件的有力工具,使用方法见:Jsoup详解(一)——Jsoup详解 Jsoup的使用方法和JS基本相同,进入豆瓣Top250界面: 找到链接地址: String[] url=new String[25];//进入Top250的界

爬虫练习-爬取豆瓣网图书TOP250的数据
前言 爬取豆瓣网图书TOP250的数据,书名、链接、作者、出版社、出版时间、价格、评分、评语,并将数据存储于CSV文件中 本文为整理代码,梳理思路,验证代码有效性——2019.12.15 环境: Python3(Anaconda3) PyCharm Chrome浏览器 主要模块: lxml requests csv 1. 爬取的豆瓣图书首页如下 2. 分析URL规律 htt
【python】爬取豆瓣电影排行榜TOP250存储到CSV文件中【附源码】
一、导入必要的模块: 代码首先导入了需要使用的模块:requests、lxml和csv。 import requestsfrom lxml import etreeimport csv 如果出现模块报错 进入控制台输入:建议使用国内镜像源 pip install 模块名称 -i https://mirrors.aliyun.com/

基于豆瓣电影TOP250网站的网络爬虫及其拓展项目
环境:Windows10 +Python3.9+anaconda3 一、 项目功能 ① 实现简单的用户交互界面 ② 从豆瓣电影top250网站上爬取top250电影的相关信息 ③ 从豆瓣电影top250网站截取到每一部电影对应的电影编号 ④ 通过用户输入的电影排行返回电影相关信息并通过其对应编号进入电影对应的短评界面,爬取前10页的评论内容,删除一些无关紧要词汇后生成词云图。 ⑤ 在源代码目录下储
scrapy mysql 报错_Scrapy+MySQL爬取豆瓣电影TOP250
说真的,不知道为啥!只要一问那些做过爬虫的筒靴,不管是自己平时兴趣爱好亦或是刚接触入门,都喜欢拿豆瓣网作为爬虫练手对象,以至于到现在都变成了没爬过豆瓣的都不好意思说自己搞过爬虫了。好了,切入正题...... 一、系统环境 Python版本:2.7.12(64位) Scrapy版本:1.4.0 Mysql版本:5.6.35(64位) 系统版本:Win10(64位) MySQLdb版本: MySQL