本文主要是介绍【爬虫实战】最新python豆瓣热榜Top250,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一.最终效果
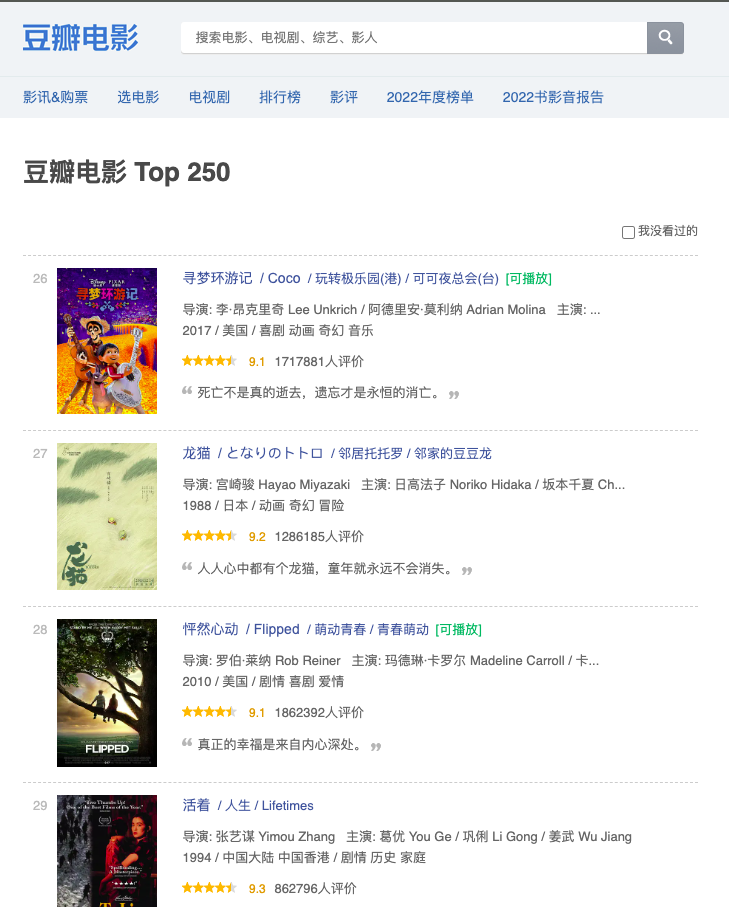

豆瓣是大多数新手练习爬虫的
二.数据定位过程
对于一个目标网站,该如何快速判定页面上的数据来源?首先你需要简单web调试能力,对大多数开发者来说都chrome浏览器应该是不二选择,当然我选中的也是。F12打开调试面板,如下图:

如果数据是来自服务端API接口,当你按上图操作翻页时,右侧空白面板处会出现请求记录,此时页面数据就是通过接口返回的;如果像上面这种,翻页操作之后还是空白,说明数据不是通过接口返回的。那接下来就需要我们定位页面元素位置了,操作如下图:
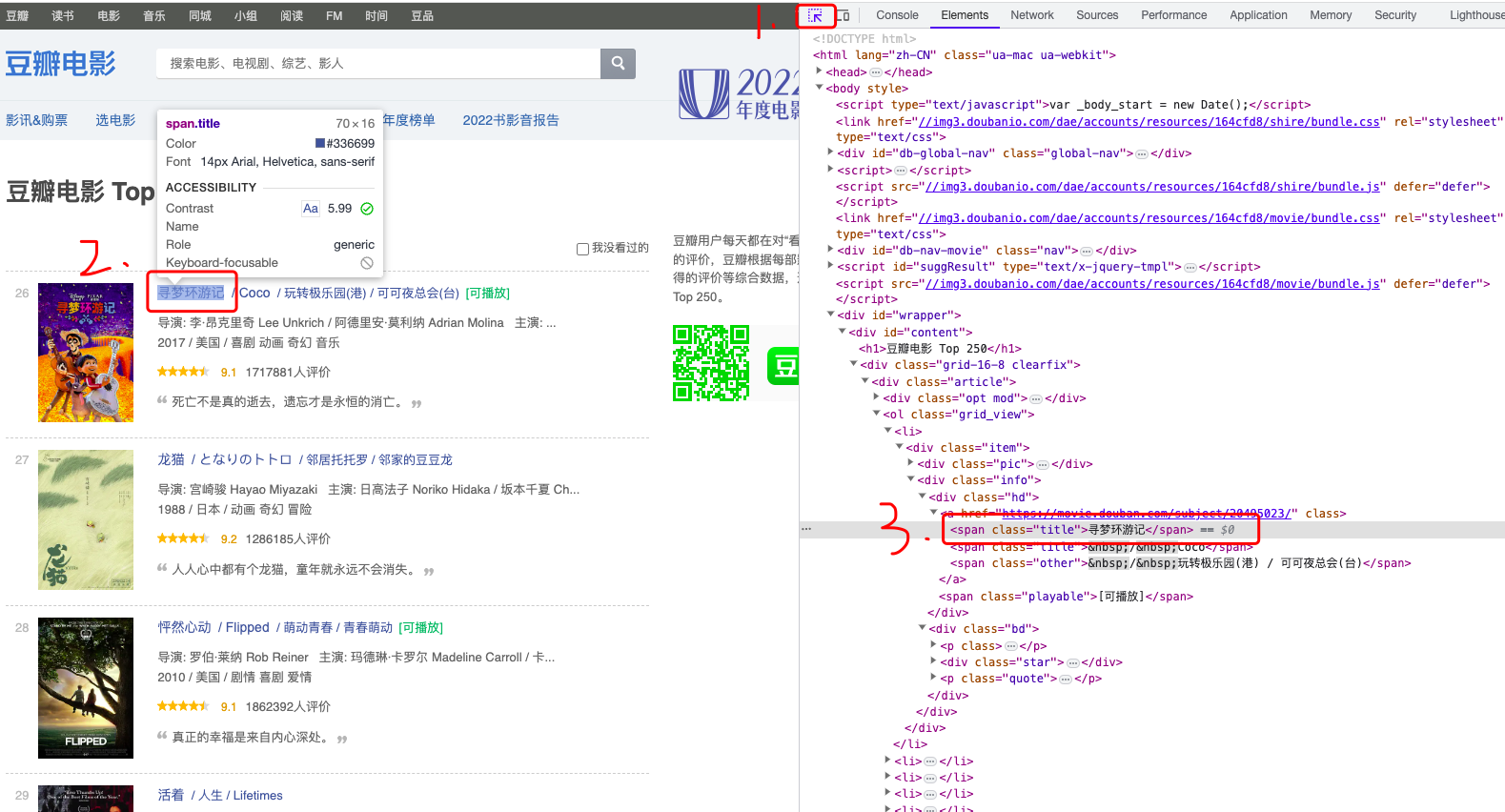
接下来就需要一个个解析我们需要的字段了;
三.编写代码
安装项目依赖库:
pip install pandas bs4
引入:
from bs4 import BeautifulSoup
使用:
soup = BeautifulSoup(html, 'html.parser')
elements = soup.select('#content .grid_view li')
注意:soup.select返回的也是soup对象,可以继续元素的查找:
for card in elements:pic = card.select_one('.item .pic')# 序号index = pic.select_one('em').text# logoimg = pic.select_one('img')# 电影名称title = card.select_one('.item .info .hd a').get_text(strip=True)...
四.保存数据
保存数据我们还是使用pandas(如果对pandas不了解的可以到我主页看我前几期分享关于pandas的文章):
Todo:
def data_to_save(self, list, page):df = pd.DataFrame(list)print("数据保存中...")if page == 1:has_file = self.check_data()if not has_file:df.to_csv(self.file_path, index=False, columns=["index", "title", "playable", "intro", "rating", "reviews", "comment"])returndf.to_csv(self.file_path, index=False, mode='a', header=False)
注意如果不是首次添加数据,需要使用mode='a’追加模式,这样加入的数据没有表头;
五.打包成exe
打包成exe使用工具pyinstaller,如果对这个库不熟悉的同学可以到我的主页查看历史分享:
Todo:
pyinstaller -F -c main.py (没有 main.spec 文件用此命令)
或者
pyinstaller main.spec (有 main.spec 文件用此命令)
六.运行过程
防止爬取太快被拉黑,请设置请求延迟区间(请求时根据输入的区间随机延迟n秒)
请输入延迟区间的开始时间(默认请回车): 1
请输入延迟区间的结束时间(默认请回车): 3
输入获取的页码数(回车默认-1获取全部): 6
开始请求第1页...
开始解析第1页数据...
数据保存中...
共有250页:
随机延时几秒: 2.847s
开始请求第2页...
开始解析第2页数据...
数据保存中...
随机延时几秒: 1.6s
开始请求第3页...
开始解析第3页数据...
数据保存中...
随机延时几秒: 2.472s
开始请求第4页...
开始解析第4页数据...
数据保存中...
随机延时几秒: 2.756s
开始请求第5页...
开始解析第5页数据...
数据保存中...
随机延时几秒: 2.598s
开始请求第6页...
开始解析第6页数据...
数据保存中...
完整代码、项目说明文档、爬取结果数据csv文件、exe文件都放入源码包中;文章最后可获取;
七.获取完整源码
爱学习的小伙伴,本次案例的完整源码,已上传微信公众号“一个努力奔跑的snail”,后台回复 豆瓣 即可获取。
这篇关于【爬虫实战】最新python豆瓣热榜Top250的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





