爬虫专题

Python多任务爬虫实现爬取图片和GDP数据
《Python多任务爬虫实现爬取图片和GDP数据》本文主要介绍了基于FastAPI开发Web站点的方法,包括搭建Web服务器、处理图片资源、实现多任务爬虫和数据可视化,同时,还简要介绍了Python爬... 目录一. 基于FastAPI之Web站点开发1. 基于FastAPI搭建Web服务器2. Web服务

Python爬虫HTTPS使用requests,httpx,aiohttp实战中的证书异步等问题
《Python爬虫HTTPS使用requests,httpx,aiohttp实战中的证书异步等问题》在爬虫工程里,“HTTPS”是绕不开的话题,HTTPS为传输加密提供保护,同时也给爬虫带来证书校验、... 目录一、核心问题与优先级检查(先问三件事)二、基础示例:requests 与证书处理三、高并发选型:

Python爬虫selenium验证之中文识别点选+图片验证码案例(最新推荐)
《Python爬虫selenium验证之中文识别点选+图片验证码案例(最新推荐)》本文介绍了如何使用Python和Selenium结合ddddocr库实现图片验证码的识别和点击功能,感兴趣的朋友一起看... 目录1.获取图片2.目标识别3.背景坐标识别3.1 ddddocr3.2 打码平台4.坐标点击5.图
Python3 BeautifulSoup爬虫 POJ自动提交
POJ 提交代码采用Base64加密方式 import http.cookiejarimport loggingimport urllib.parseimport urllib.requestimport base64from bs4 import BeautifulSoupfrom submitcode import SubmitCodeclass SubmitPoj():de

Python:豆瓣电影商业数据分析-爬取全数据【附带爬虫豆瓣,数据处理过程,数据分析,可视化,以及完整PPT报告】
**爬取豆瓣电影信息,分析近年电影行业的发展情况** 本文是完整的数据分析展现,代码有完整版,包含豆瓣电影爬取的具体方式【附带爬虫豆瓣,数据处理过程,数据分析,可视化,以及完整PPT报告】 最近MBA在学习《商业数据分析》,大实训作业给了数据要进行数据分析,所以先拿豆瓣电影练练手,网络上爬取豆瓣电影TOP250较多,但对于豆瓣电影全数据的爬取教程很少,所以我自己做一版。 目

Golang 网络爬虫框架gocolly/colly(五)
gcocolly+goquery可以非常好地抓取HTML页面中的数据,但碰到页面是由Javascript动态生成时,用goquery就显得捉襟见肘了。解决方法有很多种: 一,最笨拙但有效的方法是字符串处理,go语言string底层对应字节数组,复制任何长度的字符串的开销都很低廉,搜索性能比较高; 二,利用正则表达式,要提取的数据往往有明显的特征,所以正则表达式写起来比较简单,不必非常严谨; 三,使

Golang网络爬虫框架gocolly/colly(四)
爬虫靠演技,表演得越像浏览器,抓取数据越容易,这是我多年爬虫经验的感悟。回顾下个人的爬虫经历,共分三个阶段:第一阶段,09年左右开始接触爬虫,那时由于项目需要,要访问各大国际社交网站,Facebook,myspace,filcker,youtube等等,国际上叫得上名字的社交网站都爬过,大部分网站提供restful api,有些功能没有api,就只能用http抓包工具分析协议,自己爬;国内的优酷、

Golang网络爬虫框架gocolly/colly(三)
熟悉了《Golang 网络爬虫框架gocolly/colly 一》和《Golang 网络爬虫框架gocolly/colly 二》之后就可以在网络上爬取大部分数据了。本文接下来将爬取中证指数有限公司提供的行业市盈率。(http://www.csindex.com.cn/zh-CN/downloads/industry-price-earnings-ratio) 定义数据结构体: type Zhj

014.Python爬虫系列_解析练习
我 的 个 人 主 页:👉👉 失心疯的个人主页 👈👈 入 门 教 程 推 荐 :👉👉 Python零基础入门教程合集 👈👈 虚 拟 环 境 搭 建 :👉👉 Python项目虚拟环境(超详细讲解) 👈👈 PyQt5 系 列 教 程:👉👉 Python GUI(PyQt5)文章合集 👈👈 Oracle数据库教程:👉👉 Oracle数据库文章合集 👈👈 优

urllib与requests爬虫简介
urllib与requests爬虫简介 – 潘登同学的爬虫笔记 文章目录 urllib与requests爬虫简介 -- 潘登同学的爬虫笔记第一个爬虫程序 urllib的基本使用Request对象的使用urllib发送get请求实战-喜马拉雅网站 urllib发送post请求 动态页面获取数据请求 SSL证书验证伪装自己的爬虫-请求头 urllib的底层原理伪装自己的爬虫-设置代理爬虫coo
Python 爬虫入门 - 基础数据采集
Python网络爬虫是一种强大且灵活的工具,用于从互联网上自动化地获取和处理数据。无论你是数据科学家、市场分析师,还是一个想要深入了解互联网数据的开发者,掌握网络爬虫技术都将为你打开一扇通向丰富数据资源的大门。 在本教程中,我们将从基本概念入手,逐步深入了解如何构建和优化网络爬虫,涵盖从发送请求、解析网页结构到保存数据的全过程,并讨论如何应对常见的反爬虫机制。通过本教程,你将能够构建有效的网络爬

0基础学习爬虫系列:网页内容爬取
1.背景 今天我们来实现,监控网站最新数据爬虫。 在信息爆炸的年代,能够有一个爬虫帮你,将你感兴趣的最新消息推送给你,能够帮你节约非常多时间,同时确保不会miss重要信息。 爬虫应用场景: 应用场景主要功能数据来源示例使用目的搜索引擎优化 (SEO)分析关键词密度、外部链接质量等网站元数据、链接提升网站在搜索引擎中的排名市场研究收集竞品信息、价格比较电商网站、行业报告制定更有效的市场策略舆情

0基础学习爬虫系列:程序打包部署
1.目标 将已经写好的python代码,打包独立部署或运营。 2. 环境准备 1)通义千问 :https://tongyi.aliyun.com/qianwen 2)0基础学习爬虫系列–网页内容爬取:https://blog.csdn.net/qq_36918149/article/details/141998185?spm=1001.2014.3001.5502 3. 步骤 1)不知道

python网络爬虫(五)——爬取天气预报
1.注册高德天气key 点击高德天气,然后按照开发者文档完成key注册;作为爬虫练习项目之一。从高德地图json数据接口获取天气,可以获取某省的所有城市天气,高德地图的这个接口还能获取县城的天气。其天气查询API服务地址为https://restapi.amap.com/v3/weather/weatherInfo?parameters,若要获取某城市的天气推荐 2.安装MongoDB

python实现并发爬虫
阅读目录 一.顺序抓取 二.多线程抓取 三.gevent并发抓取 四.基于tornado的coroutine并发抓取 在进行单个爬虫抓取的时候,我们不可能按照一次抓取一个url的方式进行网页抓取,这样效率低,也浪费了cpu的资源。目前python上面进行并发抓取的实现方式主要有以下几种:进程,线程,协程。进程不在的讨论范围之内,一般来说,进程是用来开启多个spider,比如我们开启了4进程,同

如何通过 Scrapyd + ScrapydWeb 简单高效地部署和监控分布式爬虫项目
来自 Scrapy 官方账号的推荐 需求分析 初级用户: 只有一台开发主机能够通过 Scrapyd-client 打包和部署 Scrapy 爬虫项目,以及通过 Scrapyd JSON API 来控制爬虫,感觉命令行操作太麻烦,希望能够通过浏览器直接部署和运行项目 专业用户: 有 N 台云主机,通过 Scrapy-Redis 构建分布式爬虫希望集成身份认证希望在页面上直观

013.Python爬虫系列_re正则解析
我 的 个 人 主 页:👉👉 失心疯的个人主页 👈👈 入 门 教 程 推 荐 :👉👉 Python零基础入门教程合集 👈👈 虚 拟 环 境 搭 建 :👉👉 Python项目虚拟环境(超详细讲解) 👈👈 PyQt5 系 列 教 程:👉👉 Python GUI(PyQt5)文章合集 👈👈 Oracle数据库教程:👉👉 Oracle数据库文章合集 👈👈 优
【go语言爬虫】go语言高性能抓取手机号码归属地、所属运营商
一、需求分析 根据手机号码获取手机号码的归属地和所属运营商类型 类似:四川 18683339513 乐山 614000 0833 中国联通 二、运行效果 三、实现源代码 package main//网址:https://github.com/M2shad0w/phone-go//安装包:go get github.com/M2shad0w/phone-goimport ("fmt

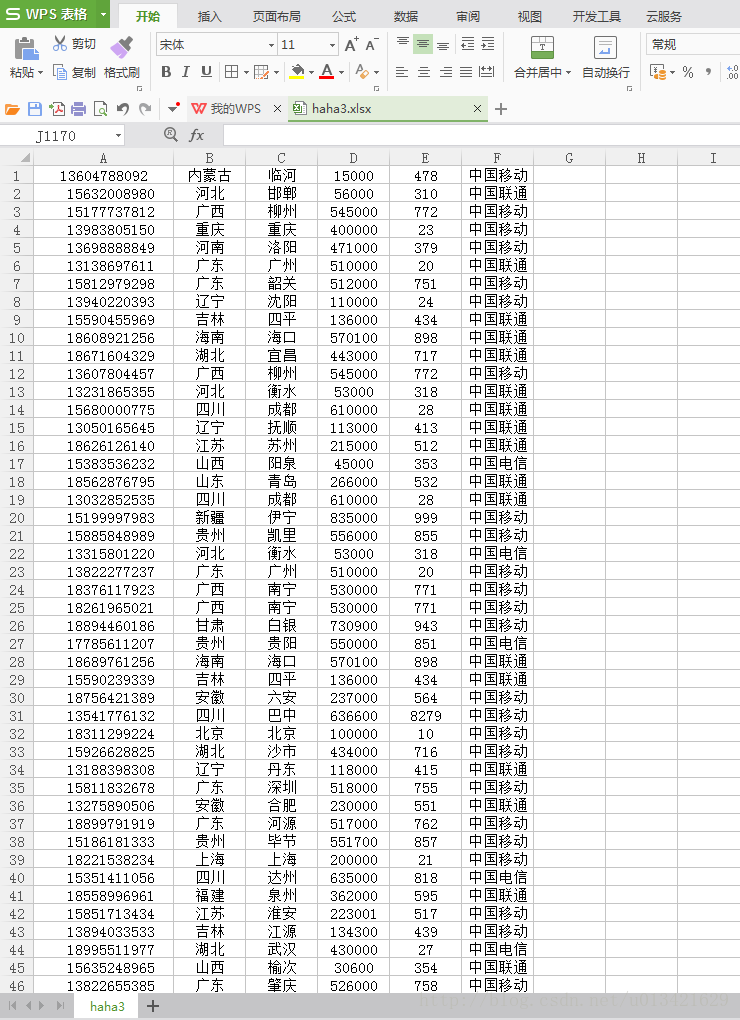
【go语言爬虫】网贷天眼数据平台爬虫
一、需求分析 利用go语言抓取网贷天眼数据平台昨日数据 字段: 排序 平台名称 成交额 综合利率 投资人 借款周期 借款人 满标速度 累计贷款余额 资金净流入 抓取url: http://www.p2peye.com/shuju/ptsj/ 二、go语言爬虫实现源代码 package mainimport ("fmt""io/ioutil""net/http""time""os""r
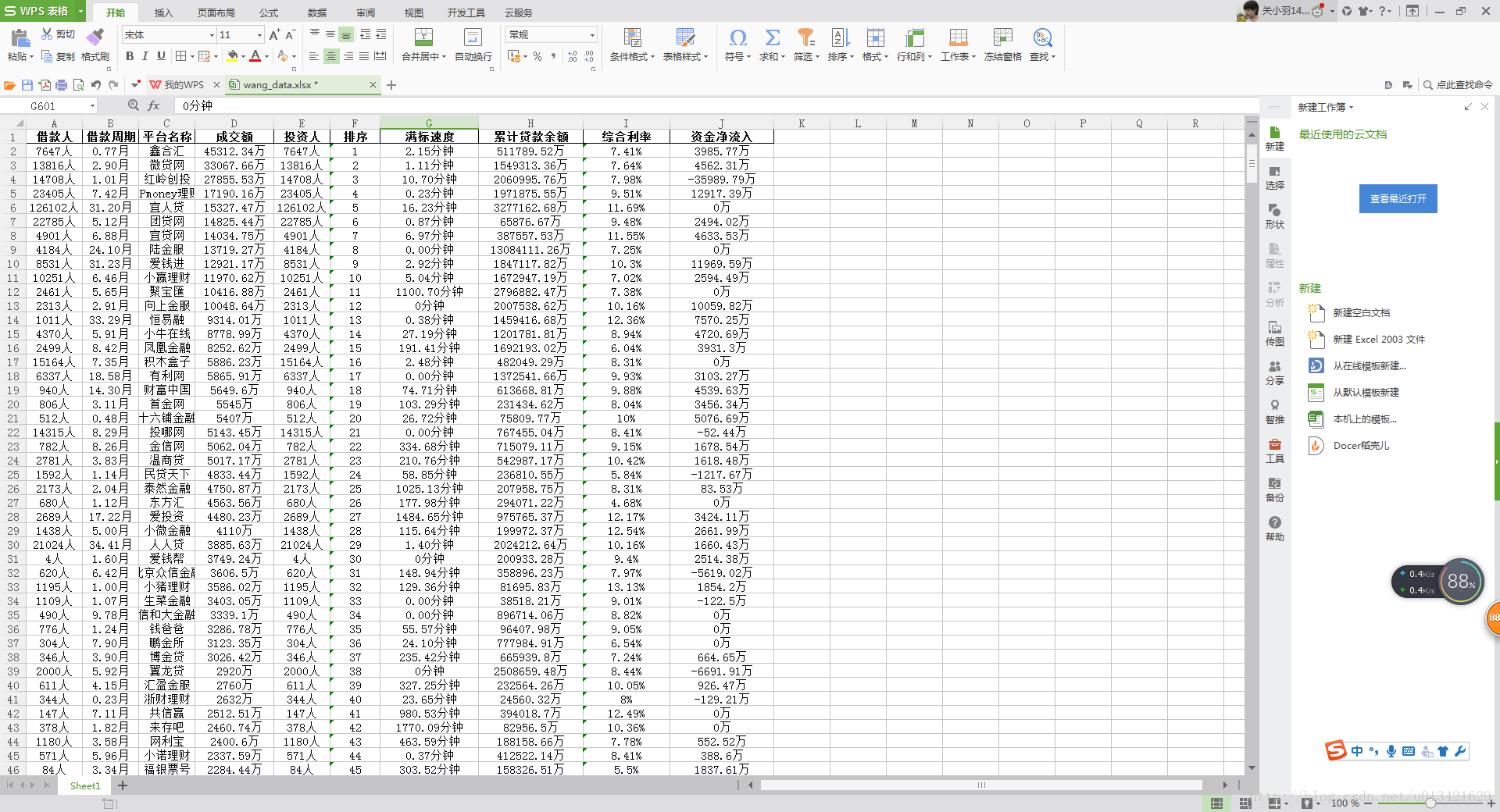
【python爬虫】网贷天眼平台表格数据抓取
一、需求分析 抓取url: http://www.p2peye.com/shuju/ptsj/ 抓取字段: 昨日数据 排序 平台名称 成交额 综合利率 投资人 借款周期 借款人 满标速度 累计贷款余额 资金净流入 二、python爬虫源代码 # -*- coding:utf-8*-import sysreload(sys)sys.setdefaultencoding('utf-

【R语言爬虫】网贷天眼数据平台表格数据抓取2
一、需求分析 抓取url: http://www.p2peye.com/shuju/ptsj/ 昨日数据: 字段:排序 平台名称 成交额 综合利率 投资人 借款周期 借款人 满标速度 累计贷款余额 资金净流入 二、rvest爬虫实现源代码 rm(list=ls())gc()options(scipen = 200)library('rvest')timestart<-Sys
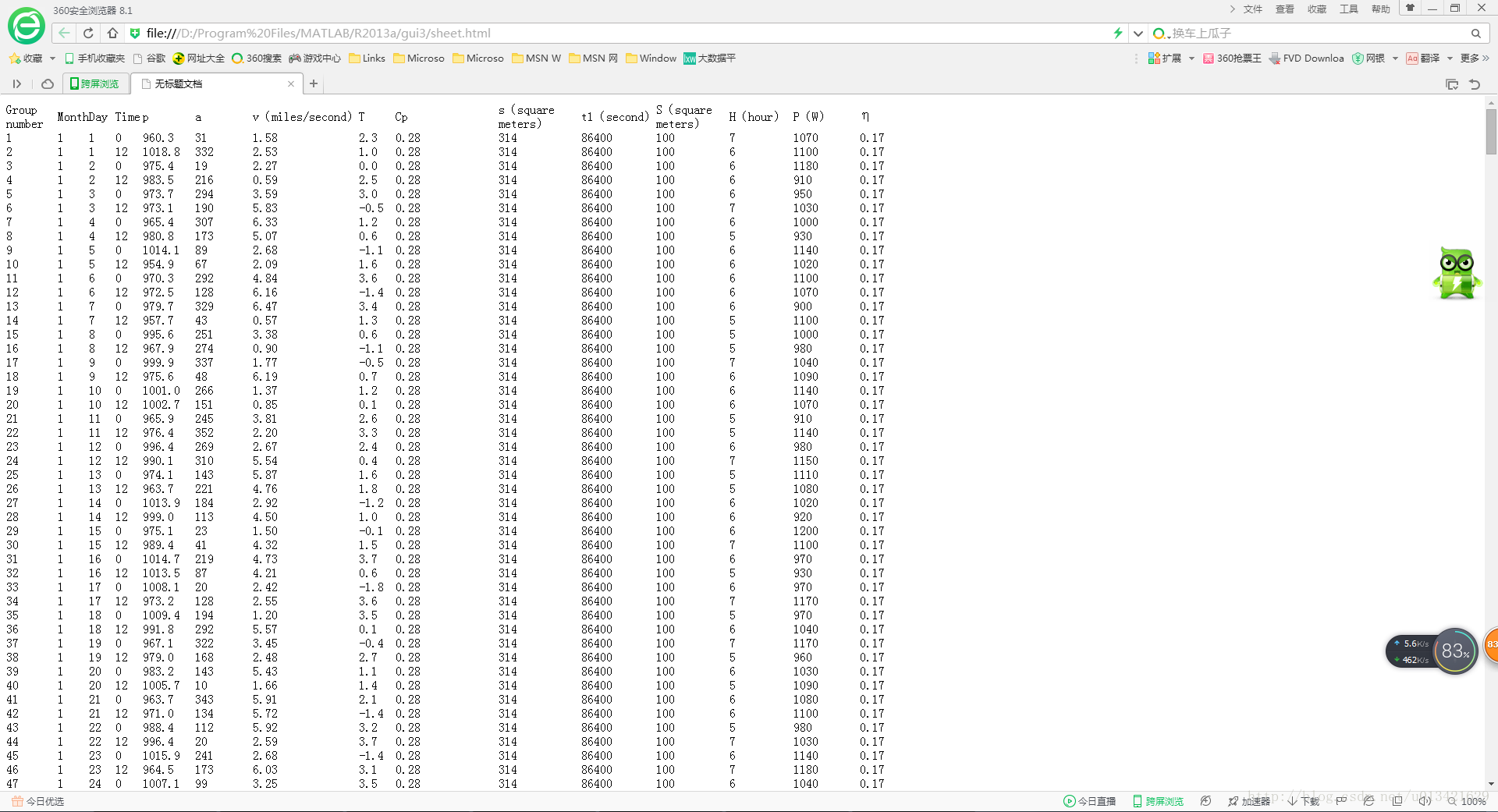
【matlab 爬虫】用matlab做网络爬虫入门系列1
一、需求分析 抓取内容: 二、实现代码 clc,clear%%% 设置不用科学计数法显示数据format short g% % % 读取源代码sourcefile=urlread('file:///D:/Program%20Files/MATLAB/R2013a/gui3/sheet.html');% 正则表达式获取第一行数据存为data1expr1='<td .*?>(

【python 爬虫】python淘宝爬虫实战(selenum+phontomjs)
1、需求目标 : 进去淘宝页面,搜索耐克关键词,抓取 商品的标题,链接,价格,城市,旺旺号,付款人数,进去第二层,抓取商品的销售量,款号等。 2、结果展示 3、源代码 # encoding: utf-8import sysreload(sys)sys.setdefaultencoding('utf-8')import timeimport pandas as pd
【R语言 爬虫】Rwebdriver 安装方法
RSelenium和Rwebdriver个人刚接触不久,除了语法不太一样以为,都是调用的Selenium Server。一个是2012年发布的包,一个是比较新的包需要在github下载。个人推荐使用Rwebdriver,不仅因为新,跟python里的RSelenium函数很多非常相似。 安装步骤 library(devtools)#如果没有安装要下载安装 install_github(rep
【python 爬虫】python中url链接编码处理方法
一、问题描述 有些网址,会把中文编码成gb2312格式,例如百度知道,美容这一词,网址上面会编码成: %C3%C0%C8%DD 那么如何生成这种编码呢? 二、解决方法 1、把要编码的文字encode成所需格式 2、利用urllib 库的quote方法编码 # -*- coding:utf-8*-import sysreload(sys)sys.setdefaultencodin
【python 爬虫】python如何以request payload形式发送post请求
普通的http的post请求的请求content-type类型是:Content-Type:application/x-www-form-urlencoded, 而另外一种形式request payload,其Content-Type为application/json import jsonurl = 'https://api.github.com/some/endpoint'payload