本文主要是介绍【python爬虫】网贷天眼平台表格数据抓取,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、需求分析
抓取url:
http://www.p2peye.com/shuju/ptsj/
抓取字段:
昨日数据
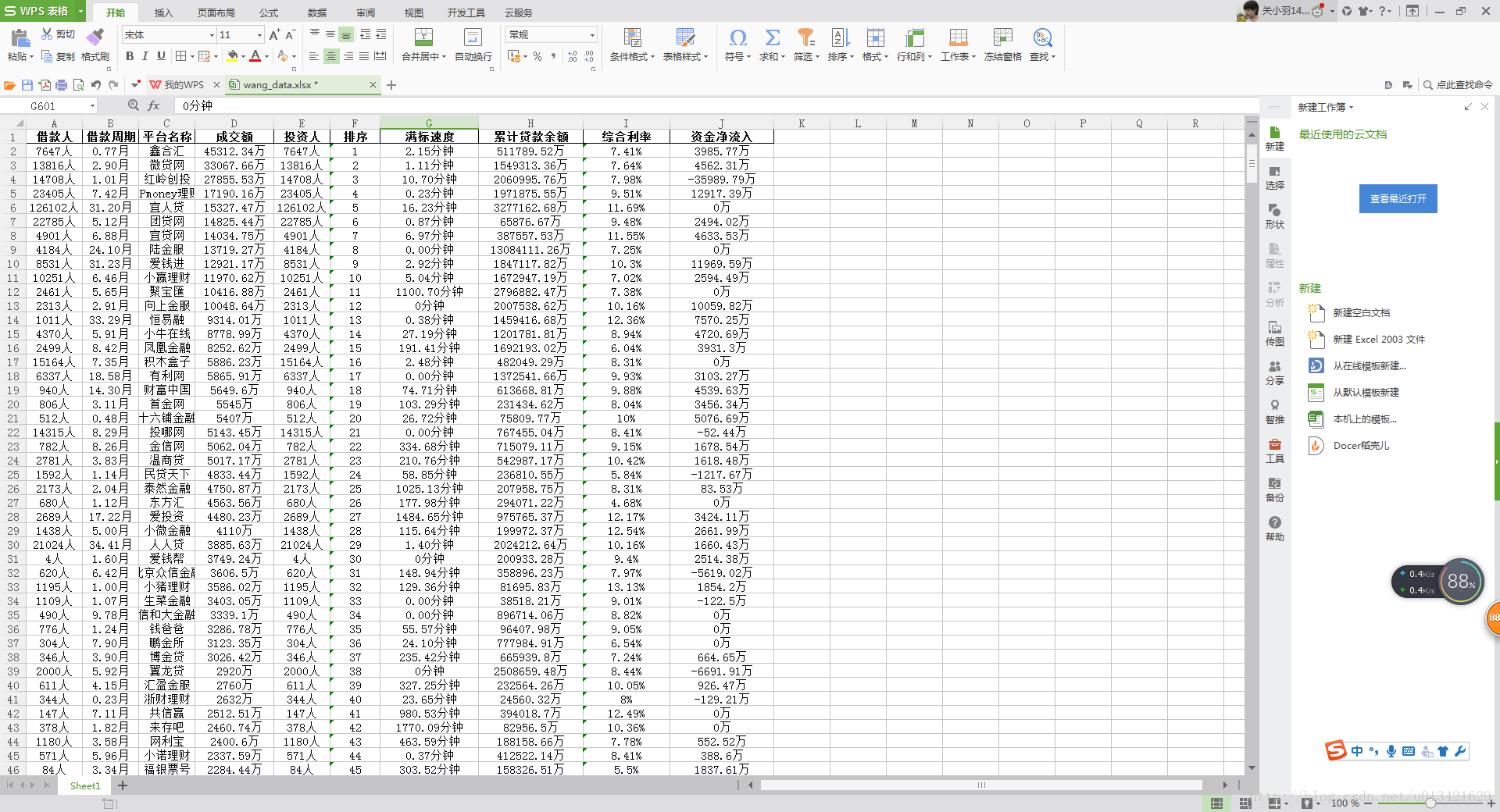
排序 平台名称 成交额 综合利率 投资人 借款周期 借款人 满标速度 累计贷款余额 资金净流入
二、python爬虫源代码
# -*- coding:utf-8*-
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import time
time1=time.time()
import requests
from lxml import etree
import re
import pandas as pdurl="http://www.p2peye.com/shuju/ptsj/"
head={"Host": "www.p2peye.com","Connection": "keep-alive","Cache-Control": "max-age=0","Upgrade-Insecure-Requests": "1","User-Agent": "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36","Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8","Accept-Encoding": "gzip, deflate, sdch","Accept-Language": "zh-CN,zh;q=0.8"
}html=requests.get(url,headers=head).content
selector=etree.HTML(html)num1=[]
name1=[]
total1=[]
rate1=[]
pnum1=[]
cycle1=[]
p1num1=[]
fuload1=[]
alltotal1=[]
capital1=[]#############用正则表达式匹配
num=re.findall('<td class="num">(.*?)</td>',html,re.S)
for each in num:print eachnum1.append(each)##############用xpath解析平台名称
name=selector.xpath('//td[@class="name"]//a/text()')
for each in name:print eachname1.append(each)#############用xpath解析成交额
total=selector.xpath('//td[@class="total"]/text()')
for each in total:print eachtotal1.append(each)#############用xpath解析综合利率
rate=selector.xpath('//td[@class="rate"]/text()')
for each in rate:print eachrate1.append(each)#############用xpath解析投资人
pnum=selector.xpath('//td[@class="pnum"]/text()')
for each in pnum:print eachpnum1.append(each)#############用xpath解析借款周期
cycle=selector.xpath('//td[@class="cycle"]/text()')
for each in cycle:print eachcycle1.append(each)#############用xpath解析借款人
p1num=selector.xpath('//td[@class="p1num"]/text()')
for each in p1num:print eachp1num1.append(each)#############用xpath解析满标速度
fuload=selector.xpath('//td[@class="fuload"]/text()')
for each in fuload:print eachfuload1.append(each)#############用xpath解析累计贷款余额
alltotal=selector.xpath('//td[@class="alltotal"]/text()')
for each in alltotal:print eachalltotal1.append(each)##############用xpath解析资金净流入
capital=selector.xpath('//td[@class="capital"]/text()')
for each in capital:print eachcapital1.append(each)data=pd.DataFrame({"排序":num1,"平台名称":name1,"成交额":total1,"综合利率":rate1,"投资人":pnum1,"借款周期":cycle1,"借款人":pnum1,"满标速度":fuload1,\"累计贷款余额":alltotal1,"资金净流入":capital})print data####################写入excel
pd.DataFrame.to_excel(data, "C:\\wang_data.xlsx", header=True, encoding='gbk', index=False)
################计算当前时间
time2 = time.time()
print u'ok,爬虫结束!'
print u'总共耗时:' + str(time2 - time1) + 's'
这篇关于【python爬虫】网贷天眼平台表格数据抓取的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




